






第三章——线性模型
1. 问题的引入——一元线性模型
如果给出一些属性值,来预测一些结果时,(比如通过发际线高度来预测计算机水平)。线性模型希望学得一个属性值的线性组合来进行对结果的预测。
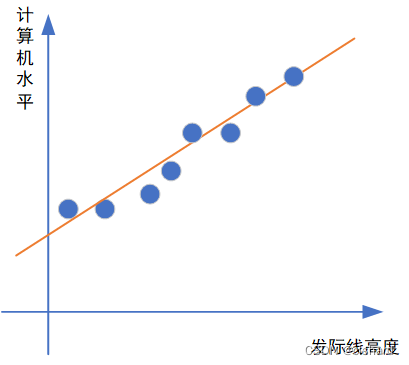
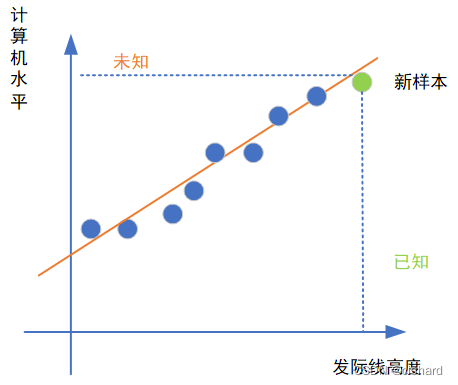
为什么要学习一个线性组合呢?试想这样一个场景,现在有一个人我并不知道他的计算机水平,但是我可以测到他的发际线高度。那么,如果说我们利用模型“学习”到了橙色直线的表达式,也就是学到了“计算机水平”随着“发际线高度”的变化而取值不同的这样一个函数,我是不是就可以通过发际线高度来“推测”他的计算机水平了?
于是,一元线性回归模型的数学表达式为:
表示属性值(比如本例中的发际线高度),
表示预测得到的结果(本例中的计算机水平),已知的真实值用
来表示。
那么如何确定和b,使得模型预测的结果最接近真实值呢?我们对于未知的样本,是无法得知真实值的,所以就需要通过已知的样本建模,使得得到的模型能对已知样本做最好的预测,也就是说需要求得模型,使得
更接近
。
问题的关键在于如何衡量与
之间的差别。均方误差是回归任务中最常用的性能度量,所以可以通过使均方误差最小化来求得
和b。
是预测值与真实值之间的“距离”的平方。
表示方差。
与高等数学里极值点的求法类似,分别对w和b求导,并令式子等于0即可求得w和b的最优值。
2. 多元线性回归
如果把例子中的单个属性扩展到多个属性,就得到了多元线性回归。
由线性代数的知识我们知道,向量的内积可以写成:
那么多元线性回归的函数就是
我们试图学得上面的表达式,使接近
。如果把
和
吸收进入向量形式,写成
,再把X写成最后一列为1的形式,标记写成列向量。
那么求方差最小化的式子变为
利用矩阵的求导法则 ,对求导得到
令上式为0得到最优解















 1529
1529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









