










0. Statement(声明)
This paper is a very hot paper on computer vision published in 2012. I briefly sorted out the main points of the paper, if there are mistakes, welcome to correct them. (“ImageNet Classification with Deep Convolutional Neural Networks”,这篇论文是2012年发布的关于计算机视觉非常火爆的论文。本人简单的梳理了论文中讲的要点,若有错误欢迎指正。🏫)
1. Start reading the paper! (1. 开始阅读论文吧!)
According to my blog on how to read essays efficiently, we know that reading essays is divided into three steps. (根据我的如何高效的阅读论文那一篇博客中,我们知道,读论文要分成三步骤。)
1.1 Pass 1
Abstract -> Discussion -> graphs/ charts.
After the first step, we know that the authors used CNNs to beat the other models in the competition, and the results were several times better than theirs. However, some details are also unclear to the authors and need to be discussed by the researchers in the future. (第一步操作过后,我们知道了作者使用了CNNs在竞赛中打败了其他的模型,而且效果比它们的好好几倍。但是,有些细节作者也是不清楚,需要研究者今后讨论。)
1.2 Pass 2
Introduction
We want to do object recognition with very good models, prevent overfitting, and collect big data. It is easy to do big with CNNs, but easy to overfit. Because of the GPU, it is now good to train CNNs. Trained very large neural networks and achieved particularly good results. The neural network has 5 convolutional layers and 3 fully linked layers; it was found that depth is very important and removing any layer is not possible. And used unusual features and new techniques to reduce overfitting. (我们要做object recognition,用很好的模型,防止过拟合,而且收集了大数据。使用CNNs做大容易,但是容易过拟合。因为有GPU,现在好训练CNN了。训练了很大的神经网络,取得了特别好的结果。神经网络有5个卷积层,3个全链接层;发现深度很重要,移掉任何一层都不行。并且用了unusual feature 和新的技术来降低过拟合。)
The Dataset
The Dataset has 15 million pieces of data and 20,000 categories. And this dataset does not have a fixed resolution, so the author made the image, 256 X 256. The short side is reduced to 256, and the long side is to ensure that the aspect ratio also goes down. However, if the long edge is more than 256, the two edges are truncated by the center. (数据集具有1500万条数据,2万种类。并且此数据集不是固定分辨率的,所以作者把图片弄成了,256*256 。把短边减少到256,长边是保证高宽比也往下降。但是,长边如果多于256的话,以中心为界把两个边截掉。)
The point ⚠️: only the original pixels are used, and no data feature extraction is done. After that, this method is the so-called End to End which means that the original picture, the original text directly, does not do any feature extraction, the neural network can help to do it. (重点 ⚠️:只是使用了原始的pixels,没有做数据特征的提取。之后,此方法就是所谓的End to End 就是说原始的图片,原始的文本直接进去,不做任何特征提取,神经网络自己就能帮忙做出来。)
The Architecture
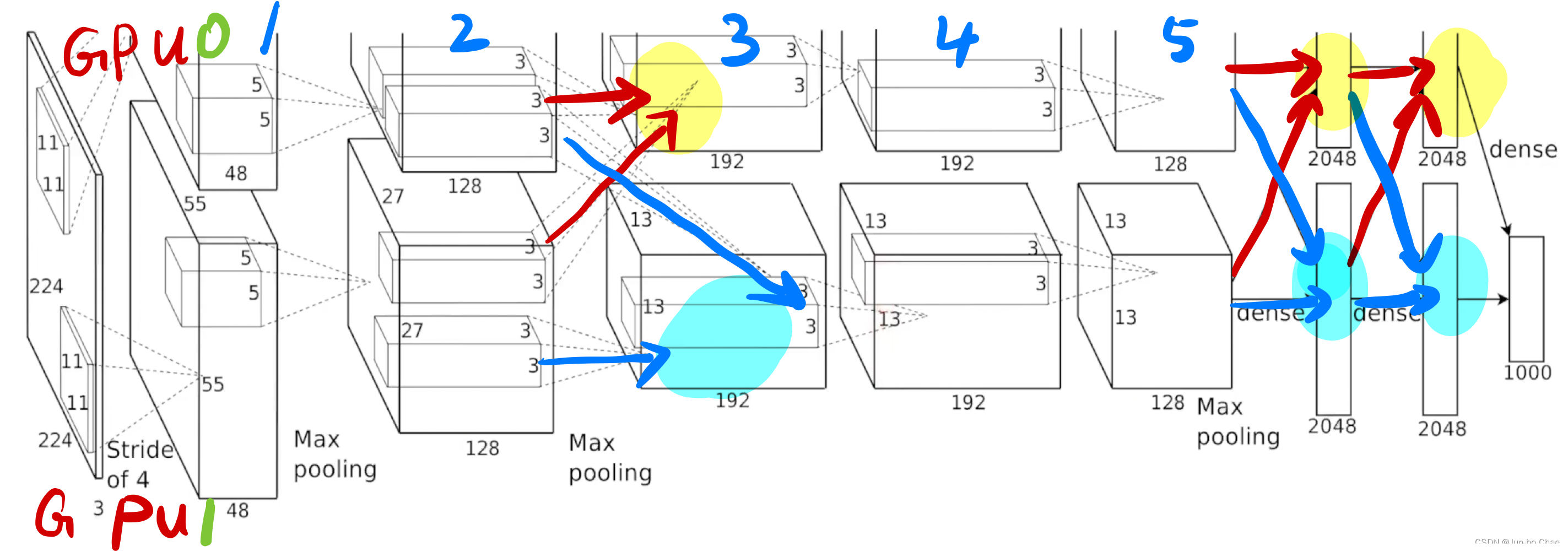
Cube indicates the size of the input and output of this data for each layer. The data input is a 224 * 224 * 3 image. The first convolution layer (the window of convolution is 11 * 11 and the stride is 4) has 48 layers of channels. (立方体表示每一层的输入和输出这个数据的大小。 数据输入的时候是224 * 224 * 3的图片。第一个卷积层(卷积的窗口是11 * 11,stride是4)有48层的通道。)
On the engineering side, it is divided into two GPUs (GPU0, GPU1) with separate convolutional layers. Each GPU has 5 convolutional layers, and the output of one convolutional layer is the input of the other convolutional layer. In convolutional layers 2 and 3, there is communication between GPU0 and GPU1, which are merged in the output channel dimension. In the rest of 1 to 2, 3 to 4, and 4 to 5, each GUP does its learning. However, the height and width between the respective convolutional layers are varied. (在工程方面,分成了两个GPU(GPU0,GPU1)分别有卷积层。每个GPU有5个卷积层,且一个卷积层的输出是另一个卷积层的输入。卷积层2和3中,GPU0和GPU1之间会有通信,在输出通道维度合并。其余的1到2,3到4,4到5中,每个GUP都是各做各的学习。 但是,各自卷积层之间的高宽是有变化的。)
Feature ⚠️: As the height and width of the image slowly decrease, the depth slowly increases. That is, the spatial information is slowly compressed as the network increases (224 * 224 to 13 * 13; indicating that each pixel inside 13 * 13 can represent a large chunk of the previous pixel). And the number of channels slowly increases (each channel number is a specific some patterns, 192 can be simply thought of as being able to identify the middle of picture 192 different patterns, each channel to identify a is a cat leg ah or an edge or something else what). After that, the input of the full linkage layer of each GPU is the result of combining the output of the 5th convolution of the two GPUs, each GPU does the full linkage independently first. Then, finally, it is combined at the classification layer to generate a vector of length 4096. If the vectors of 4096 are very close to each other, it means that the two images are of the same object. And the vector of 4096 lengths can represent the semantic information of the images well. (特点⚠️:随着图片的高宽慢慢的减少,深度慢慢的增加。 也就是说,随着网络的增加,空间信息慢慢的压缩(224 * 224 到 13 * 13;说明13 * 13 里面的每一个像素能够代表之前的一大块的像素)。并且通道数慢慢的增加(每一个通道数是一种特定的一些模式,192个可以简单的认为是能够识别图片中间的192种不同的模式,每一个通道去识别一个是猫腿呀还是一个边还是什么其他的什么东西)。之后,每个GPU的全链接层的输入是两个GPU中的第5个卷积的输出合并起来的结果,每个GPU先独立做全链接。然后,最后在分类层的时候合并起来生成长度为4096的向量。 若两个图片的长度为4096的向量非常接近就说明是同一个物体的图片。并且长度为4096的向量能够很好的表示图片的语义信息。)
In summary
- The increase in the width of the convolutional layers is an increase in semantic information. (卷积层宽度的增加是语义信息的增加。)
- The usefulness of deep learning is that, through so many previous layers, a picture is finally compressed into a single vector of 4096 lengths. This vector can represent all the semantic information in between. After a series of training (feature extraction) in the previous layers, it becomes a vector that the machine can understand. (深度学习的用处是,通过前面那么多层,最后把一张图片压缩成一个长为4096的一个向量。这个向量能把中间的语义信息都表示出来。通过前面一系列层的训练(特征提取)之后变成了一个机器能够看懂的向量。)
- The whole machine learning can be seen as the compression of knowledge (text, images, etc.), through the intermediate model, and finally compressed into a vector, this vector can be recognized by the machine. After the machine recognizes it, it can do all kinds of things on it. (整个机器学习可以看作的对一个知识(文字,图片等)的压缩,通过中间的模型,最后压缩成一个向量,这个向量机器可以识别。机器识别之后就能够在这上面做各种各样的事情了。)
Model defects
AlexNet design with three full links (the last one is the output, the middle two very large 4096 full links is a big bottleneck, resulting in a particularly large model that can not put the network into the GPU as a whole). (模型的缺陷:AlexNet设计的时候用了三个全链接(最后一个是输出,中间两个很大的4096全链接是一个很大的瓶颈,导致模型特别大不能把网络整体的放入GPU里))
Reducing Overfitting
Overfitting image understanding: You are given some questions, and you memorize this, but there is no understanding of what the questions are for. So, the exam is not good. (过拟合形象理解:给你一些题,你就把这个背下来的,根本没有理解题是干什么的。所以,考试的时候肯定考不好。)
Data Augmentation
- The author set the image to 224 * 224, so the image is randomly snapped from 256 * 256. (因为作者设定的图片是224 * 224。所以,随机从256 * 256 的图片中扣出来。)
- The author changed the entire RGB channel of the image, using PCA, so that the transformed image will be different from the original (color). (作者把图片的整个RGB的channel 改变一下,使用了PCA。这么操作的话会导致变换的图片会跟原始图片是不一样的(颜色)。)
Details of learning
- SGD: a batch size of 128 examples, momentum of 0.9 weight decay of 0.0005 (L2 regularization).
- The weights are initialized by Gaussian random variables with mean of 0 and variance of 0.01. (权重是均值为0,方差为0.01的高斯随机变量来初始化了。)
3.The bias of the convolution layers in the second, fourth, and fifth layers are initialized to 1, the fully linked layers are also initialized to 1, and the rest layers are initialized to 0. (在第2层,第4层,第5层的卷积层的偏移量初始为1,全链接层也初始化为1,剩下的全部初始化为0 。) - The learning rate is initialized to 0.01; if the validation set error does not move, it is manually divided by 10 to 0.001. (Learning rate初始化为0.01,要是验证集误差不动了就手动除以10,变为0.001 。)
Results
- Found a strange phenomenon: the result after convolution on GPU0 is color independent, but on GPU1 is color-dependent. (发现了奇怪的现象:GPU0上卷积后的结果是跟颜色无关的,但是GPU1上是跟颜色有关的。)
- Look at each feature activation: that is, what the output of each convolutional layer or fully linked layer is doing. Very often, we do not know what the neurons are learning. However, some neurons correspond very well to the neurons at the bottom of the layer that has learned some more local information, such as texture, orientation, etc. If it’s a neuron on the upper side it will learn, for example, this is a hole, or this is a human‘s head or hand, or this is an animal or a lot of information in there. (看一下每个feature activation:就是每个卷积层或者全链接层他的输出那些东西在干什么。很多时候虽然不知道神经元在学什么。但是,有一些神经元还是很有对应性的,它在底层的神经元学到了一些比较局部的信息,比如说纹理,方向等。如果是偏上的神经元的话会学到,比如这是一个洞,或者这是一个人的头,手,或者是这是一个动物,或者很多信息在里面。)
2. Acknowledgements(鸣谢)
Thanks to Mr. Li Mu for sharing, the video explanation is detailed in the following link 🔗:(感谢李沐老师的分享,视频讲解详见如下链接🔗:)
Pass 1
Pass 2















 936
936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











