









0. 声明 ☕️
本文将使用SVM实现情感分析任务:包含数据预处理,模型构建等一系列操作,从0开始构建了完整的项目。若有错误欢迎指正,感谢!🌹,让我们共同进步!!⛽️。本文的最后,挂出了使用的数据集(waimai_cn.csv),所以读者可以放心食用~ ( PS:中文停用词网上很多,所以没挂出来。 )🤠
⚠️:若要转载请标明出处!!!
1. 文本预处理 📖
import joblib
import jieba
import gensim
from numpy import *
import numpy as np
import pandas as pd
from sklearn import svm
from sklearn.metrics import accuracy_score, f1_score
from sklearn.metrics import confusion_matrix
# 加载停用词
def stop_words(path='/Users/apple/DataspellProjects/Computational_linguistics_EI/dataset/stopwords.txt'):
with open(path,'r',encoding='gbk',errors='ignore') as f:
return[l.strip() for l in f]
# 文本预处理
def text_preprocessing():
# 加载停用词
stopwords = stop_words()
# 读取文件
df = pd.read_csv("/Users/apple/DataspellProjects/Computational_linguistics_EI/dataset/waimai_cn.csv")
# 切词并过滤调停用词
df["review"] = df["review"].map(lambda x: " ".join([i for i in jieba.cut(x) if i not in stopwords]))
# 保存处理好的文本
df.to_csv("/Users/apple/DataspellProjects/Computational_linguistics_EI/dataset/processed_waimai_cn.csv", index=False, header=True,
columns=["label", "review"])
text_preprocessing()
print("OK")

2. 训练自己的词向量模型 🔢
from gensim.models import word2vec
import pandas as pd
data = pd.read_csv("/Users/apple/DataspellProjects/Computational_linguistics_EI/dataset/processed_waimai_cn.csv") #加载数据
# 将文本列转换为句子列表
sentences = [str(text).split() for text in data["review"]]
# 训练模型
model = word2vec.Word2Vec(sentences, window=1, min_count=2, workers=4)
model.save('my_word2vec_model.bin')
# 加载模型
model = word2vec.Word2Vec.load('my_word2vec_model.bin')
# 查找与给定词最相似的词
similar_words = model.wv.most_similar('难')
print(similar_words)
print("OK")

# 测试
# 获取词向量
from gensim.models import Word2Vec
# 加载模型文件
model = Word2Vec.load("my_word2vec_model.bin")
# 使用模型获取词向量
vector = model.wv["好吃"]
print(vector)
print(vector.shape)

3. 构建decoder 🤔️
# 整句话的词向量,我们知道词向量的叠加同时也会将语义进行叠加,这里我们将每句话中的所有词进行词向量的相加,我们就可以定义词向量相加的方法:
from gensim.models import word2vec
def total_vector(words):
model = word2vec.Word2Vec.load("my_word2vec_model.bin")
vec = np.zeros(100).reshape((1, 100))
for word in words:
try:
vec += model.wv[word].reshape((1, 100))
except KeyError:
continue
return vec
4. 测试 🧪
- 下述代码将数据集分为三个部分;
- 其中训练集占80%,测试集占20%,而训练集又被划分为训练集和验证集;
- 其中训练集占75%,验证集占25%。 random_state参数用于控制随机数生成器的种子,以便可以重复运行代码并获得相同的结果。
df = pd.read_csv('/Users/apple/DataspellProjects/Computational_linguistics_EI/dataset/processed_waimai_cn.csv')
# X = np.array((df["review"].map(total_vector)).tolist()).reshape(-1, 1)
X = np.array([df["review"].map(total_vector)]).reshape(-1, 100)
y = np.array(df["label"])
print(X.shape)
print(y.shape)

from sklearn.model_selection import train_test_split
# 首先将数据集划分为训练集和测试集,其中test_size表示测试集所占比例
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 然后将训练集划分为训练集和验证集,其中validation_size表示验证集所占比例
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=42)
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)

5. 训练SVM 🏋️
import joblib
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
SVM = SVC(C=5.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
SVM.fit(X_train, y_train)
joblib.dump(model, 'waimai_svm0.pkl')
6. 预测 💻
joblib.dump(SVM, 'waimai_svm0.pkl')
pre_X_test = SVM.predict(X_test)
7. 评价指标 🧐
accuracy = accuracy_score(pre_X_test, y_test)
print(f"accuracy:{accuracy}")
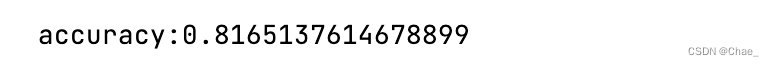
# f1
f1 = f1_score(pre_X_test,y_test,average='micro')
print(f"f1:{f1}")

8. 实验效果 🥳
def svm_predict(query):
words = jieba.lcut(str(query), cut_all=False)
print([word for word in words])
words_vec = total_vector(words).reshape(1, -1)
print(words_vec)
result = SVM.predict(words_vec)
print(result)
if int(result) == 1:
print('类别:好评')
elif int(result) == 0:
print('类别:坏评')
query = input("请输入你的评论:")
svm_predict(query)


















 217
217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











