







NON-DEEP NETWORKS
普林斯顿大学和英特尔实验室
0 Abstract
深度是深度神经网络的重要特征,深度网络越深就参数量越大,速度越慢。
所以想设计高性能的非深度的神经网络
使用并行子网络,保持高性能的同时减少深度
实验结果
通过利用并行子结构,作者证明了,深度仅为12的网络可以在ImageNet、CIFAR10和CIFAR100上实现超过80%、96%和81%的Top-1精度。此外,作者还在COCO上进行了实验,深度为12的主干网络能够实现48%的AP精度。此外,作者还分析了此设计中缩放网络的规则,并展示了如何在不改变网络深度的情况下提高性能。
1 Introduction
DNN革新了许多领域,关键属性是深度。通常,神经网络可以被描述为层的线性序列,即没有组内连接的神经元群。在这种情况下,网络的深度就是它的层数
Resnet的结论:人们普遍认为,大深度是高性能网络的重要组成部分,因为深度增加了网络的表征能力,并有助于学习越来越抽象的特征,Resnet因此而成功
所以现在高性能通过大深度训练模型实现 基本都在30层往上
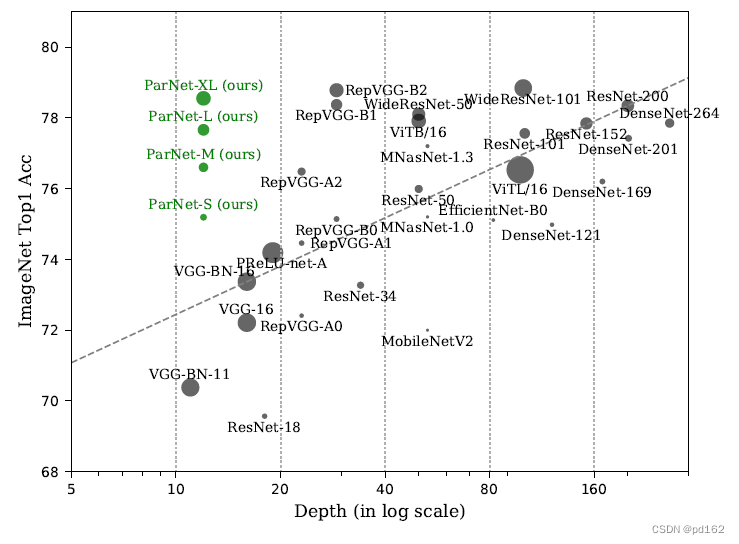
(为了公平起见,我们排除了长时间训练、高分辨率或多尺度裁剪测试的结果。)
但是大深度总是必要的吗?这个问题值得一问,因为大深度并非没有缺点。更深层次的网络会导致更多的顺序处理和更高的延迟;它很难并行化,也不太适合需要快速响应的应用程序。
本文研究10-20层的神经网络,提出并行化的神经网络ParNet
12层的神经网络在ImageNet能到80% 在MS-COCO上能到48%
ParNet的关键设计选择是使用并行子网。我们不是按顺序排列层,而是在并行的子网络中排列层。这种设计是“令人尴尬的平行”,在这个意义上,除了开始和结束,子网之间没有连接。这使得我们可以在保持高精度的同时减少网络的深度。值得注意的是,我们的平行结构不同于通过增加一层神经元的数量来“扩大”神经网络。
尽管处理单元之间的通信带来了额外的延迟,但还是实现了这一点。这表明,在未来,可能会有专门的硬件来进一步减少通信延迟,类似parnet的体系结构可以用于创建非常快速的识别系统。(硬件要跟上了!)
我们证明了ParNet可以通过增加宽度、分辨率和分支数量来有效缩放,同时保持深度不变。我们观察到ParNet的性能并没有饱和,而是随着计算吞吐量的增加而增加。
summary
• 12层的网络有竞争力
• 我们展示了如何利用ParNet中的并行结构进行快速、低延迟的推断
• 我们研究了ParNet的缩放规则,证明了在恒定的低深度下缩放是有效的。
2 Related Work
2.1 Analyzing importance of depth
深度的重要性:具有sigmoid激活的单层神经网络可以以任意小的误差近似任何函数
但是,需要使用具有足够大宽度的网络,这可能会大幅增加参数数量。后续工作表明,要逼近一个函数,具有非线性的深层网络所需的参数要比浅层网络少得多
然而,在这样的分析中,先前的工作只研究了线性顺序结构的浅层网络,不清楚这个结论是否仍然适用于其他设计。在这项工作中,我们表明,与传统的见解相反,浅层网络可以表现得非常好,关键是要有并行的子结构。
2.2 Scaling DNNs
在神经网络缩放问题上 增加深度、宽度和分辨率可以有效地缩放卷积网络(2019)
我们发现,在保持深度不变和较低的情况下,可以通过增加分支数量、宽度和分辨率来有效地扩展ParNet
与2016的工作相比,我们考虑得浅层得多 12层
2.3 Shallow network
浅网络在机器学习理论中引起了广泛的关注。单层神经网络具有无限宽,其行为类似于高斯过程,可以从核方法的角度来理解训练过程
但是,与最先进的网络相比,这样的模式并不具有竞争力
我们提供了实证证明,非深度网络可以与深度网络竞争
2.4 Multi-stream networks
多流神经网络已被用于各种计算机视觉任务
HRNet 在整个前进通道中保持多分辨率流
这些信息流定期地融合在一起以交换信息。
我们也使用不同分辨率的流,但我们的网络要浅得多,流只在最后融合一次,这使得并行化更容易
3 Method
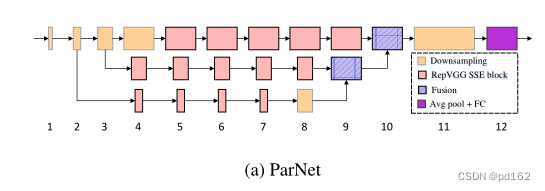
ParNet由以不同分辨率处理特征的并行子结构组成,作者将这些并行子结构称为streams。来自不同stream的特征在网络的后期进行融合,这些融合的特征用于下游任务。下图展示了ParNet的示意图。
3.1 DOWNSAMPLING AND FUSION BLOCK
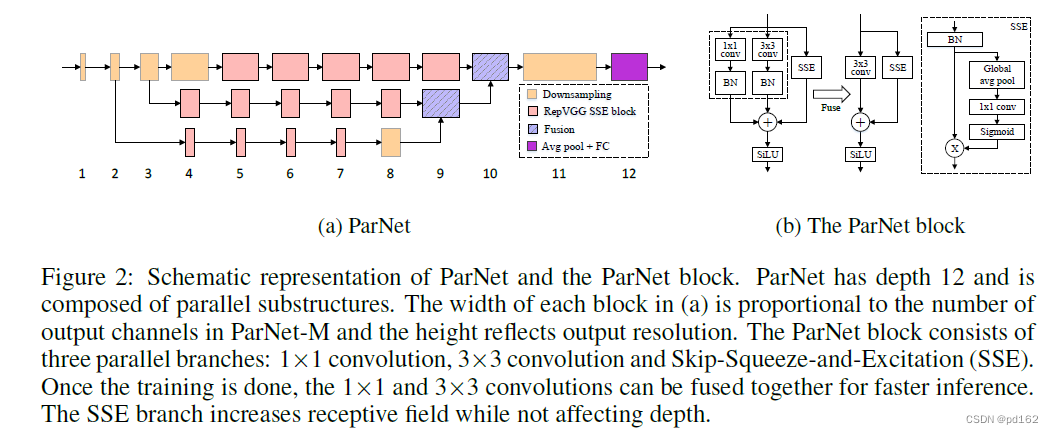
根据经验,选择了VGG风格的块作为基础块 Rep-VGG解决了VGG不好训练的问题
使用了Rep-VGG
只有3*3的卷积层 感受野必然受限
所以建立了SSE层(基于SE层改造 2018CVPR)标准的SE增加了网络的深度,因此,作者使用了一种Skip-Squeeze-Excitation的设计,并使用了一个全连接层。
将RepVGG和SSE进行结合 得到RepVGG-SSE基础模块
将Relu换成Silu 增强非线性 增强网络的表征能力
3.2 Network architecture
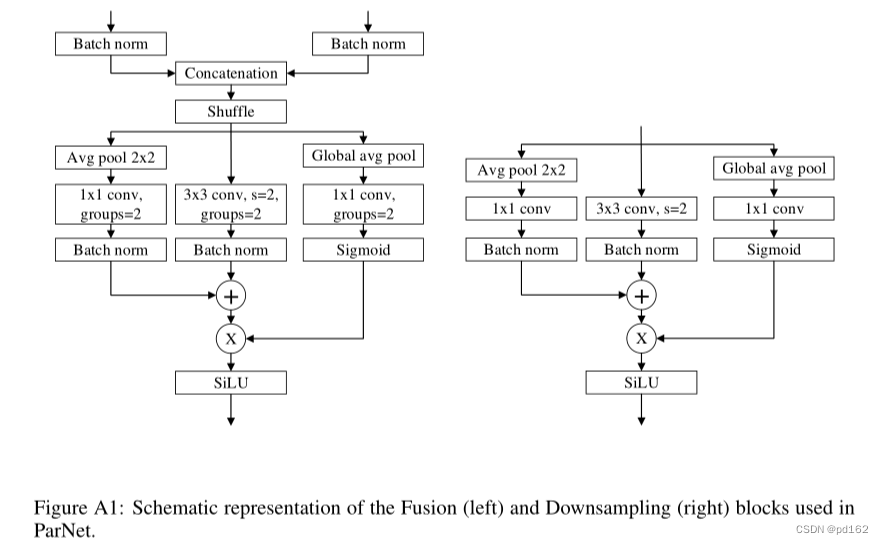
除了RepVGG-SSE模块,还有下采样和特征融合块
下行采样块降低分辨率,增加宽度,以实现多尺度处理,而融合块合并来自多个分辨率的信息。
由于连接,Fusion块的输入通道是下采样块的两倍。因此,为了减少参数计数,我们使用与group=2的卷积
3.3 Network architecture
在CIFAR中,图像的分辨率较低,网络架构与ImageNet略有不同。首先,我们用RepVGGSSE块替换深度1和2的Downsampling块。为了减少最后一层的参数数量,我们将最后一个宽度较大的Downsampling块替换为一个较窄的11卷积层。此外,我们还通过从每个流中删除一个块并添加深度为3的块来减少参数的数量。
ParNet的示意图如上图所示,每个stream由一系列RepVGG SSE块组成,这些块以不同的分辨率处理特征。然后,使用拼接的融合块对来自不同stream的特征进行融合。最后,输出被传递到深度下标为11的下采样块。
3.4 Scaling ParNet
通过扩大网络规模可以获得更高的精度,之前的工作缩放了宽度、分辨率和深度。由于本文保持低的深度,所以增加宽度、分辨率和stream来放大ParNet
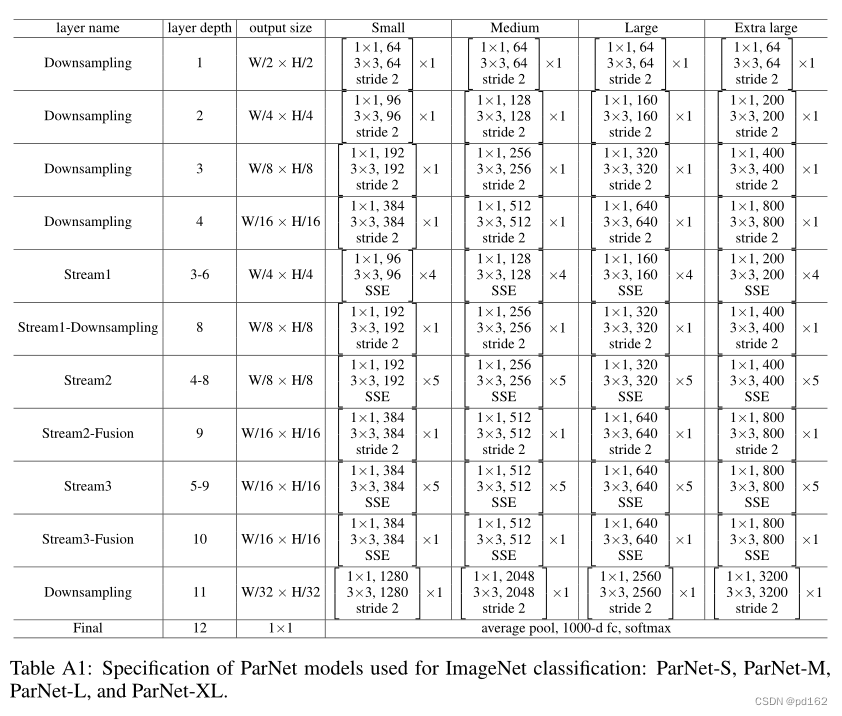
3.4 PRACTICAL ADVANTAGES OF PARALLEL ARCHITECTURES
硬件发展会有瓶颈,所以并行计算是很有必要的
为什么这段文章在扯硬件发展瓶颈????
所有这些因素使得非深度并行结构在实现快速推断方面具有优势
4 Results
ILSVRC2012 ImageNet Large Scale visual recognition challenge 2012
1.28M trainning images
50k validation images
1000 classes
SGD 120 epochs
前5个epoch warmup
每30epoch learning rate decay 0.1
初始 lr = 0.8
bz = 2048
cross-entropy loss with smoothed labels
cropping, flipping, color-jitter, and rand-augment (Cubuk et al., 2020) data augmentations.
参数量减少很多 深度减少很多 性能差别不大
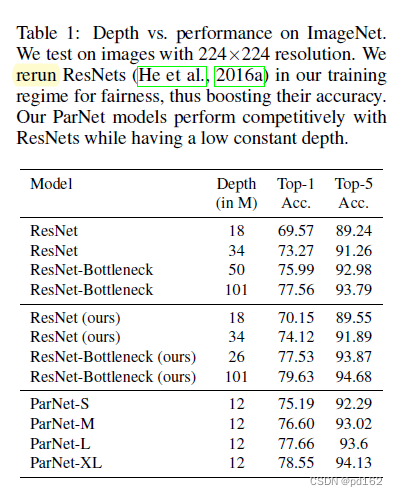
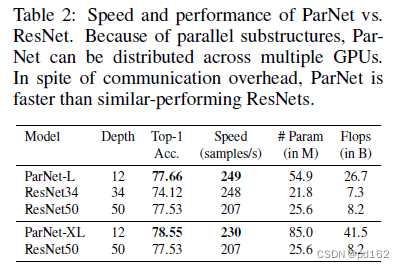
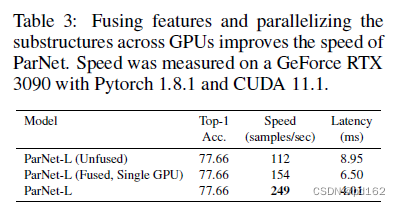
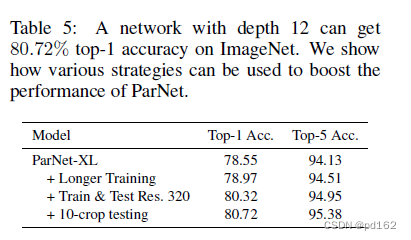
Experiments on MS-COCO
MS-COCO数据集
We evaluate on the COCO-2017 dataset,
which consists of 118K training images and 5K validation images with 80 classes.
使用ParNet代替YOLOv4的backbone
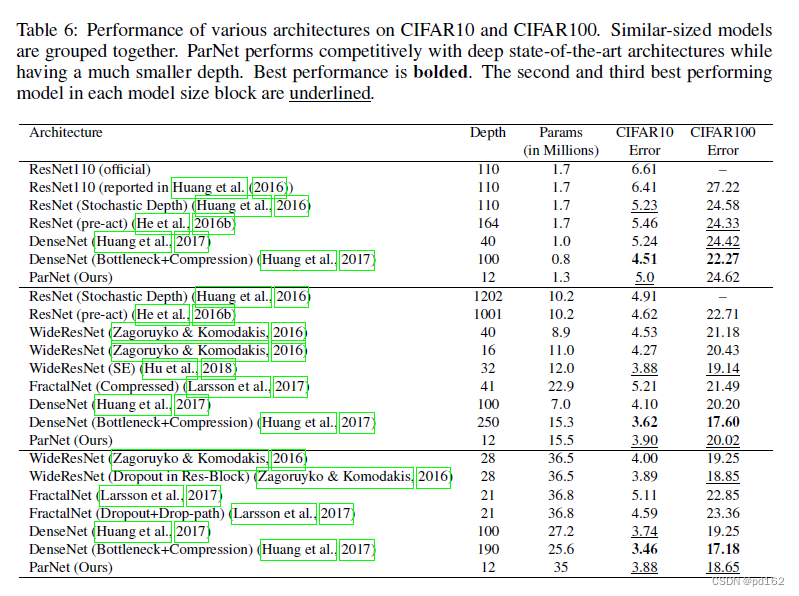
Experiments on CIFAR
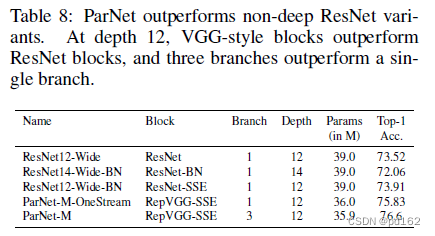
Ablation Studies
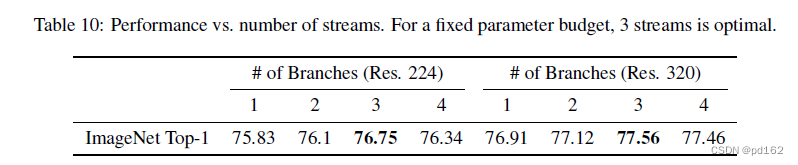

Scaling ParNet.

5 Discussion
我们提供了第一个经验证明,非深度网络可以在大规模视觉识别基准测试中与深度网络竞争。我们展示了并行子结构可以用来创建性能惊人的非深度网络。我们还演示了如何在不增加深度的情况下扩大和改进此类网络的性能。
(笔者注:RepVGG与HRNet的变体 未被ICLR2022接收,但是浅层也是趋势 有其价值)
















 2934
2934











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









