






量化模型并与模型对话
LMDeploy量化主要包括 KV8量化和W4A16量化。总的来说,量化是一种以参数或计算中间结果精度下降换空间节省(以及同时带来的性能提升)的策略。
常见的 LLM 模型由于 Decoder Only 架构的特性,实际推理时大多数的时间都消耗在了逐 Token 生成阶段(Decoding 阶段),是典型的访存密集型场景。
那么,如何优化 LLM 模型推理中的访存密集问题呢? 我们可以使用KV8量化和W4A16量化。KV8量化是指将逐 Token(Decoding)生成过程中的上下文 K 和 V 中间结果进行 INT8 量化(计算时再反量化),以降低生成过程中的显存占用。W4A16 量化,将 FP16 的模型权重量化为 INT4,Kernel 计算时,访存量直接降为 FP16 模型的 1/4,大幅降低了访存成本。Weight Only 是指仅量化权重,数值计算依然采用 FP16(需要将 INT4 权重反量化)。
KV Cache是一种缓存技术,通过存储键值对的形式来复用计算结果,以达到提高性能和降低内存消耗的目的。在大规模训练和推理中,KV Cache可以显著减少重复计算量,从而提升模型的推理速度。理想情况下,KV Cache全部存储于显存,以加快访存速度。当显存空间不足时,也可以将KV Cache放在内存,通过缓存管理器控制将当前需要使用的数据放入显存。
LMDeploy使用AWQ算法,实现模型4bit权重量化。推理引擎TurboMind提供了非常高效的4bit推理cuda kernel,性能是FP16的2.4倍以上。
仅需执行一条命令,就可以完成模型量化工作:
lmdeploy lite auto_awq \
/root/models/internlm2-chat-1_8b \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 1024 \
--w-bits 4 \
--w-group-size 128 \
--work-dir /root/models/internlm2-chat-1_8b-4bit用量化模型进行对话:
lmdeploy chat /root/internlm2-chat-1_8b-4bit --model-format awq --cache-max-entry-count 0.4效果如下:


API服务形式部署量化模型对话
通过命令启动API服务器
lmdeploy serve api_server \
/root/models/internlm2-chat-1_8b-4bit \
--model-format awq \
--cache-max-entry-count 0.4\
--quant-policy 0 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1可以通过FastAPI自带的docs查看接口:
首先通过ssh连接服务器
ssh -CNg -L 23333:127.0.0.1:23333 root@ssh.intern-ai.org.cn -p <你的ssh端口号>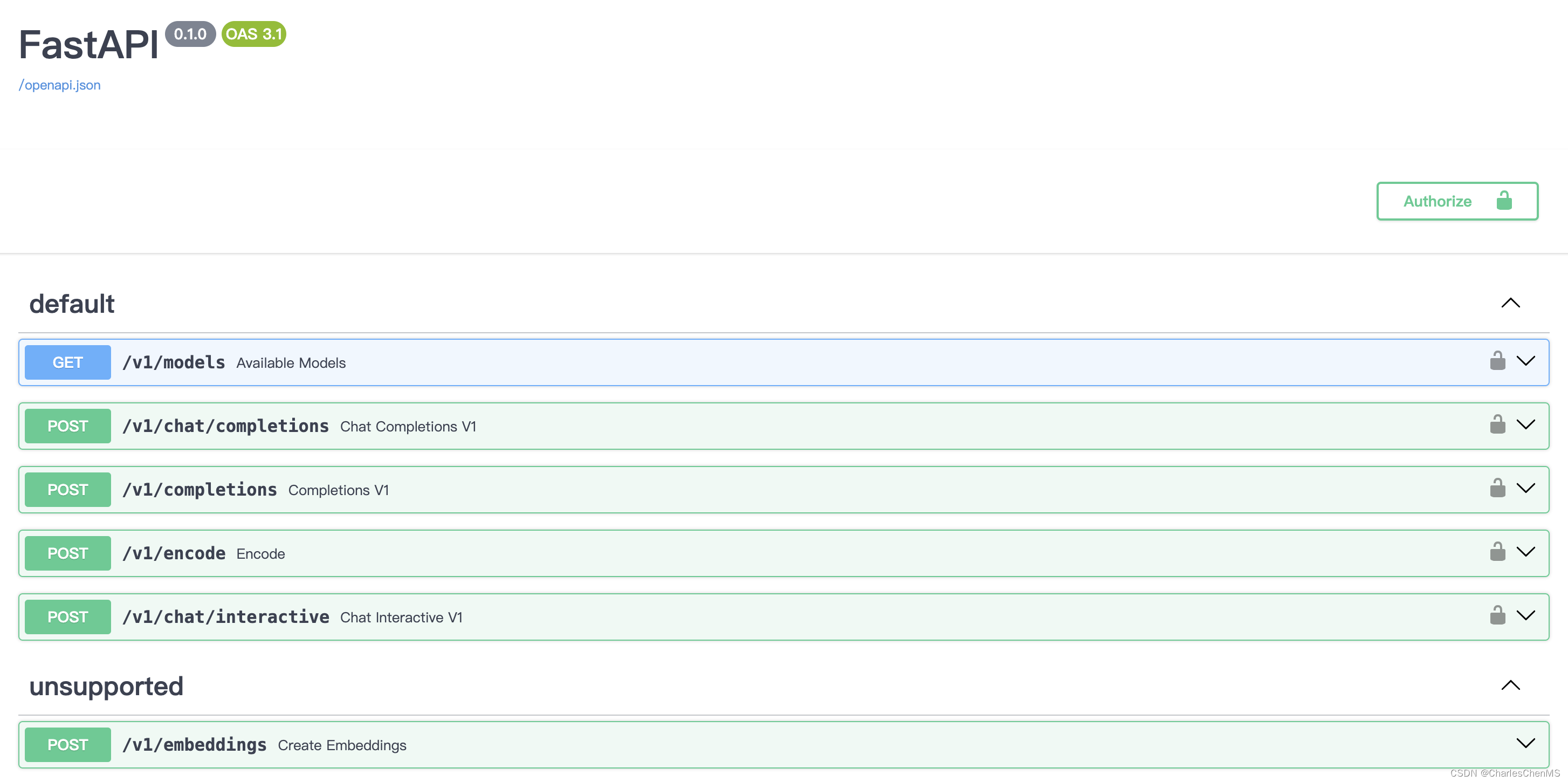 接下来通过命令行客户端访问服务:
接下来通过命令行客户端访问服务:
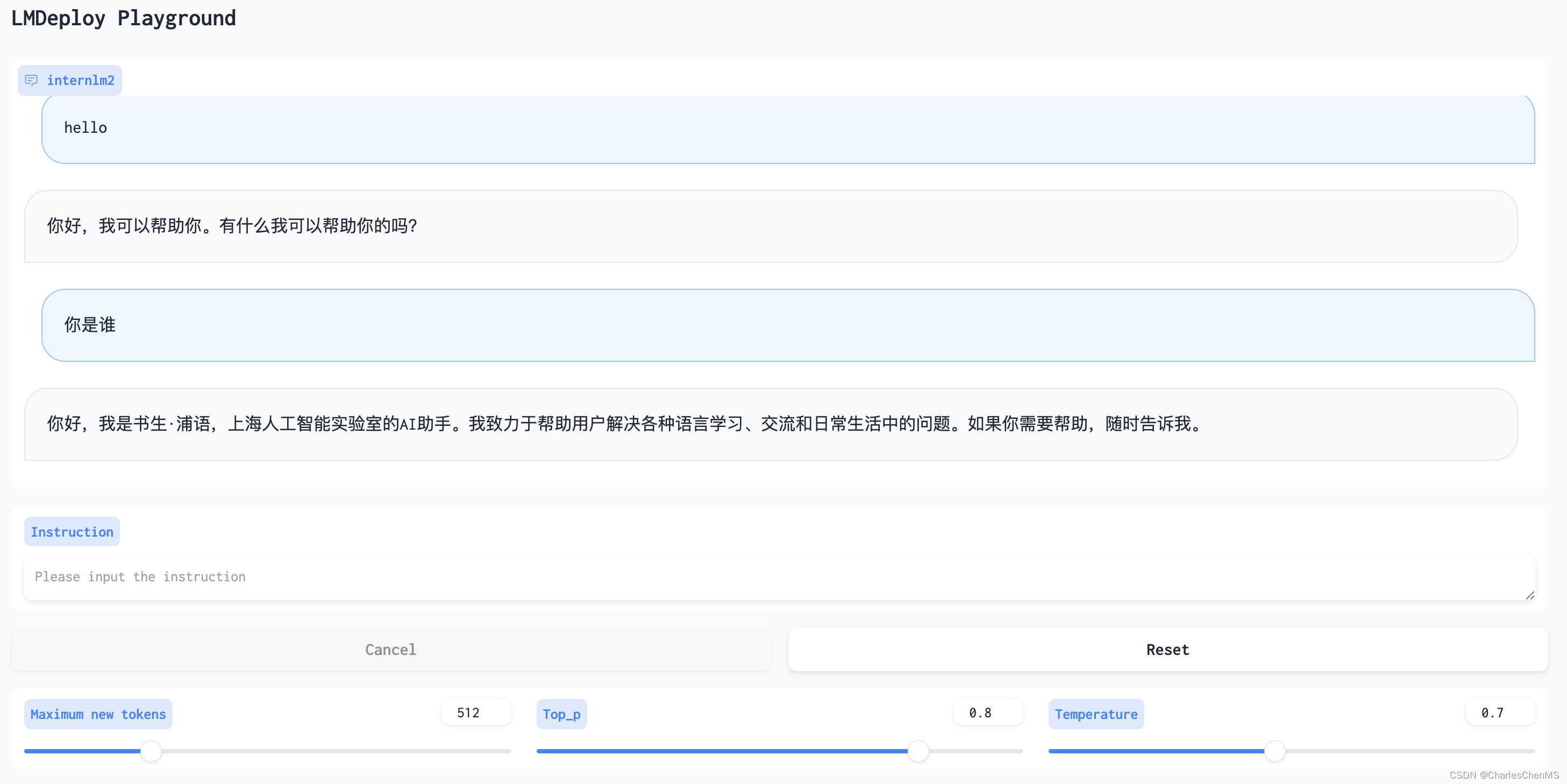
 然后通过gradio访问对话服务:
然后通过gradio访问对话服务:
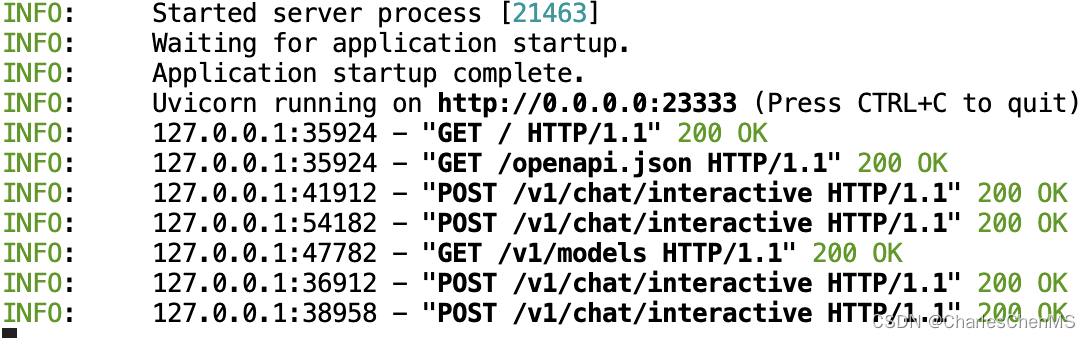
可以在服务端看到接口调用的chat:
 通过python代码来部署量化模型
通过python代码来部署量化模型
新建Python源代码文件pipeline.py:
touch /root/pipeline.py写入以下代码:
from lmdeploy import pipeline
pipe = pipeline('/root/models/internlm2-chat-1_8b')
response = pipe(['Hi, pls intro yourself', '上海是'])
print(response)运行代码:
python /root/pipeline.py效果如下:
 使用LMDeploy运行视觉多模态大模型llava
使用LMDeploy运行视觉多模态大模型llava
先安装llava依赖库:
pip install git+https://github.com/haotian-liu/LLaVA.git@4e2277a060da264c4f21b364c867cc622c945874新建文件:
touch /root/gradio_llava.py填入以下代码:
import gradio as gr
from lmdeploy import pipeline
# pipe = pipeline('liuhaotian/llava-v1.6-vicuna-7b') 非开发机运行此命令
pipe = pipeline('/share/new_models/liuhaotian/llava-v1.6-vicuna-7b')
def model(image, text):
if image is None:
return [(text, "请上传一张图片。")]
else:
response = pipe((text, image)).text
return [(text, response)]
demo = gr.Interface(fn=model, inputs=[gr.Image(type="pil"), gr.Textbox()], outputs=gr.Chatbot())
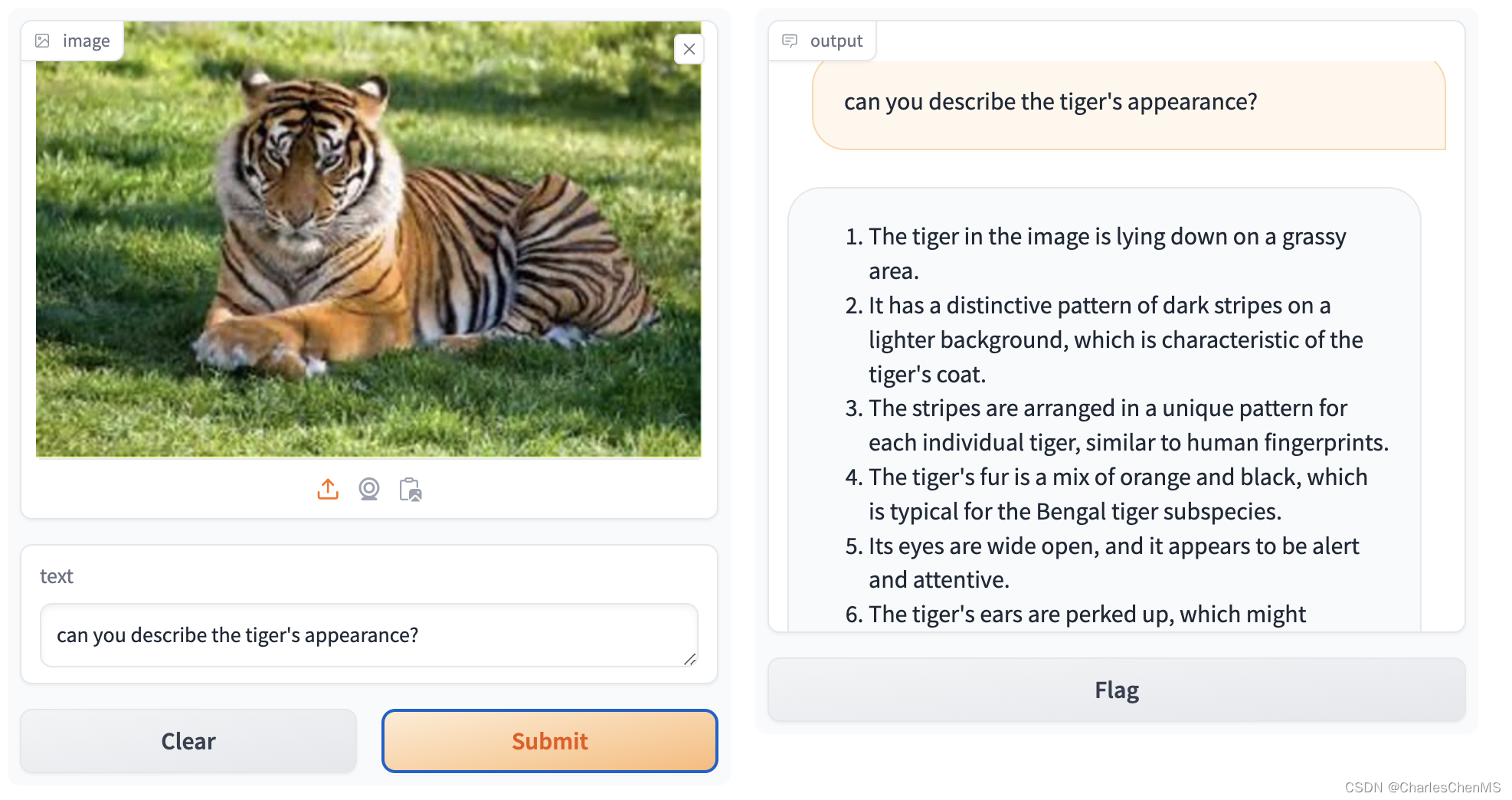
demo.launch() 运行效果如下:
















 971
971











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









