






1、大模型简介
大语言模型(LLM,Large Language Model),也称大型语言模型,是一种旨在理解和生成人类语言的人工智能模型。尽管这些大型语言模型与小型语言模型(例如 3.3 亿参数的 BERT 和 15 亿参数的 GPT-2)使用相似的架构和预训练任务,但它们展现出截然不同的能力,尤其在解决复杂任务时表现出了惊人的潜力,这被称为“涌现能力”。
2、大模型发展史
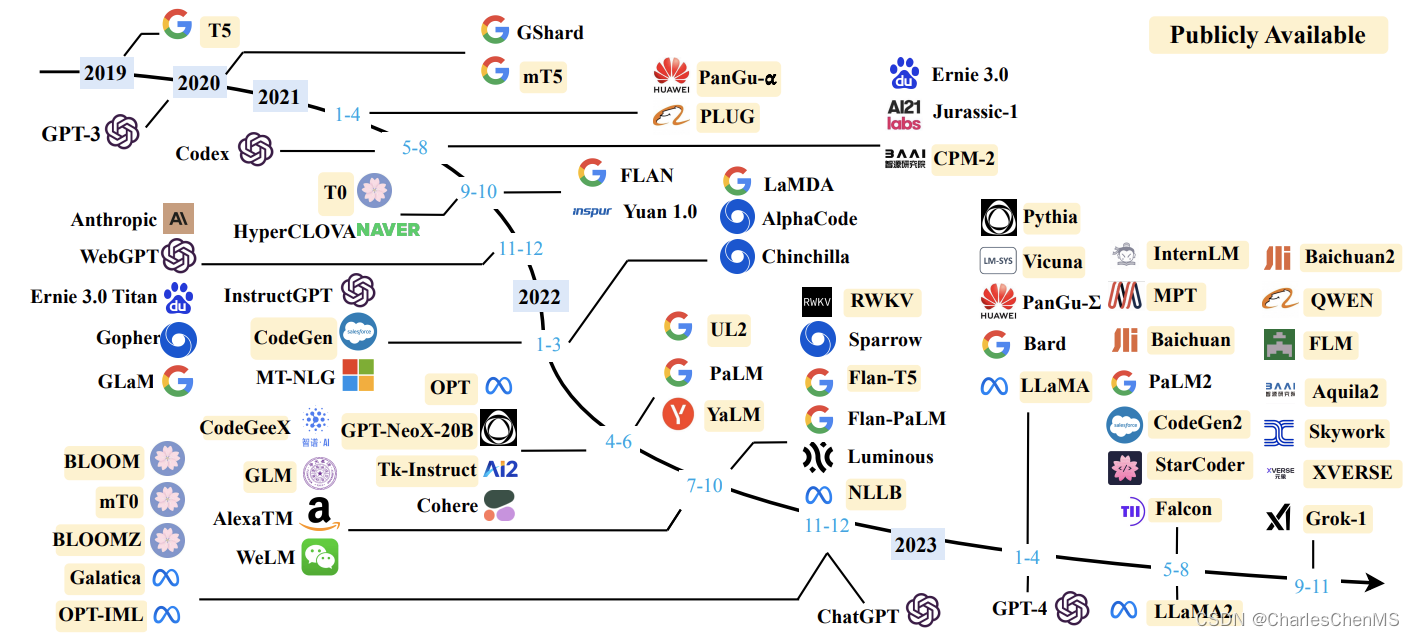
很多公司都在早期就布局了大模型的研究,但真正引爆大模型发展的还是OpenAI公司的ChatGPT,本质上是一个基于基座模型的对话应用,说明真正迎合市场需求的真正能落地的应用才能快速推动技术的发展。
3、LLM的能力
区分大语言模型(LLM)与以前的预训练语言模型(PLM)最显著的特征之一是它们的 涌现能力 。涌现能力是一种令人惊讶的能力,它在小型模型中不明显,但在大型模型中特别突出。类似物理学中的相变现象,涌现能力就像是模型性能随着规模增大而迅速提升,超过了随机水平,也就是我们常说的量变引起质变。
涌现能力可以与某些复杂任务有关,但我们更关注的是其通用能力。接下来,我们简要介绍三个 LLM 典型的涌现能力:
-
上下文学习:上下文学习能力是由 GPT-3 首次引入的。这种能力允许语言模型在提供自然语言指令或多个任务示例的情况下,通过理解上下文并生成相应输出的方式来执行任务,而无需额外的训练或参数更新。
-
指令遵循:通过使用自然语言描述的多任务数据进行微调,也就是所谓的
指令微调。LLM 被证明在使用指令形式化描述的未见过的任务上表现良好。这意味着 LLM 能够根据任务指令执行任务,而无需事先见过具体示例,展示了其强大的泛化能力。 -
逐步推理:小型语言模型通常难以解决涉及多个推理步骤的复杂任务,例如数学问题。然而,LLM 通过采用
思维链(CoT, Chain of Thought)推理策略,利用包含中间推理步骤的提示机制来解决这些任务,从而得出最终答案。据推测,这种能力可能是通过对代码的训练获得的。
4、RAG
大型语言模型(LLM)相较于传统的语言模型具有更强大的能力,然而在某些情况下,它们仍可能无法提供准确的答案。为了解决大型语言模型在生成文本时面临的一系列挑战,提高模型的性能和输出质量,研究人员提出了一种新的模型架构:检索增强生成(RAG, Retrieval-Augmented Generation)。该架构巧妙地整合了从庞大知识库中检索到的相关信息,并以此为基础,指导大型语言模型生成更为精准的答案,从而显著提升了回答的准确性与深度。
总体来说对于固定应用领域的大模型来说,这种方法避免了训练数据和模型的频繁更新,大大降低了成本;并且能够改善用户的使用感受,而且能够给出具体的知识源头。
5、LLM开发
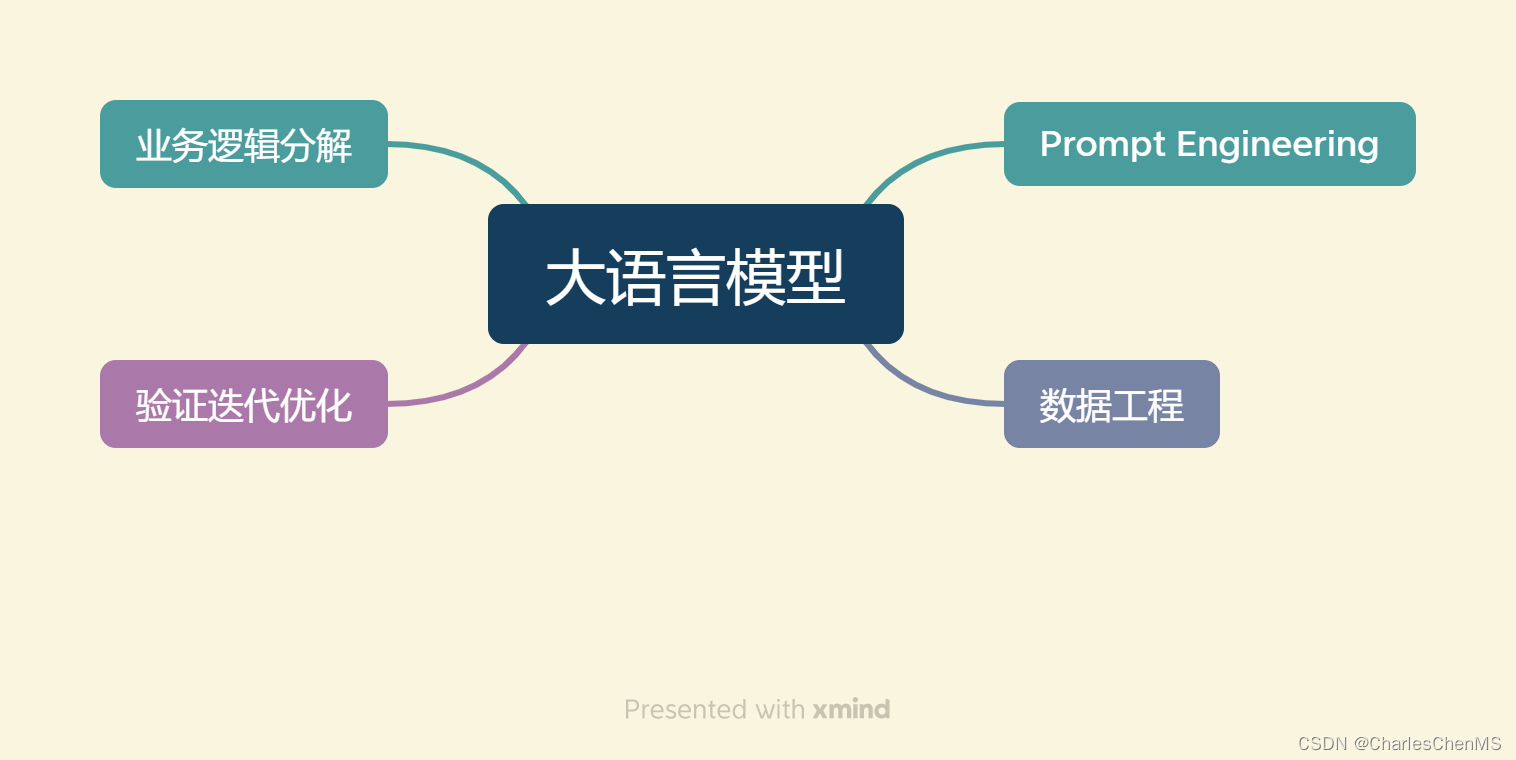
大模型开发与传统的AI开发有很大的差别,大语言模型的两个核心能力:指令遵循与文本生成提供了复杂业务逻辑的简单平替方案。传统业务需要大量的人工参与去对子业务的数据和模型分别进行构建,而大模型可以基于所有的数据去构建,将业务逻辑的重心放在提示工程之上。















 1423
1423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









