







1、免模型预测
具体说来,有模型强化学习尝试先学习一个环境模型,它可以是环境的动态(例如,给定一个状态和一个动作,预测下一个状态)或奖励(给定一个状态和一个动作,预测奖励),即前面小节所讲的状态转移概率和奖励函数。一旦有了这个环境模型,智能体可以使用它来计划最佳的行动策略,例如通过模拟可能的未来状态来预测哪个动作会导致最大的累积奖励。它的优点很明显,即可以在不与真实环境交互的情况下进行学习,因此可以节省实验的成本。但缺点是,这种模型往往是不完美的,或者是复杂到难以学习和计算。
而免模型则直接学习在特定状态下执行特定动作的价值或优化策略。它直接从与环境的交互中学习,不需要建立任何预测环境动态的模型。其优点是不需要学习可能是较为复杂的环境模型,更加简单直接,但是缺点是在学习过程中需要与真实环境进行大量的交互。注意,除了动态规划之外,基础的强化学习算法都是免模型的。
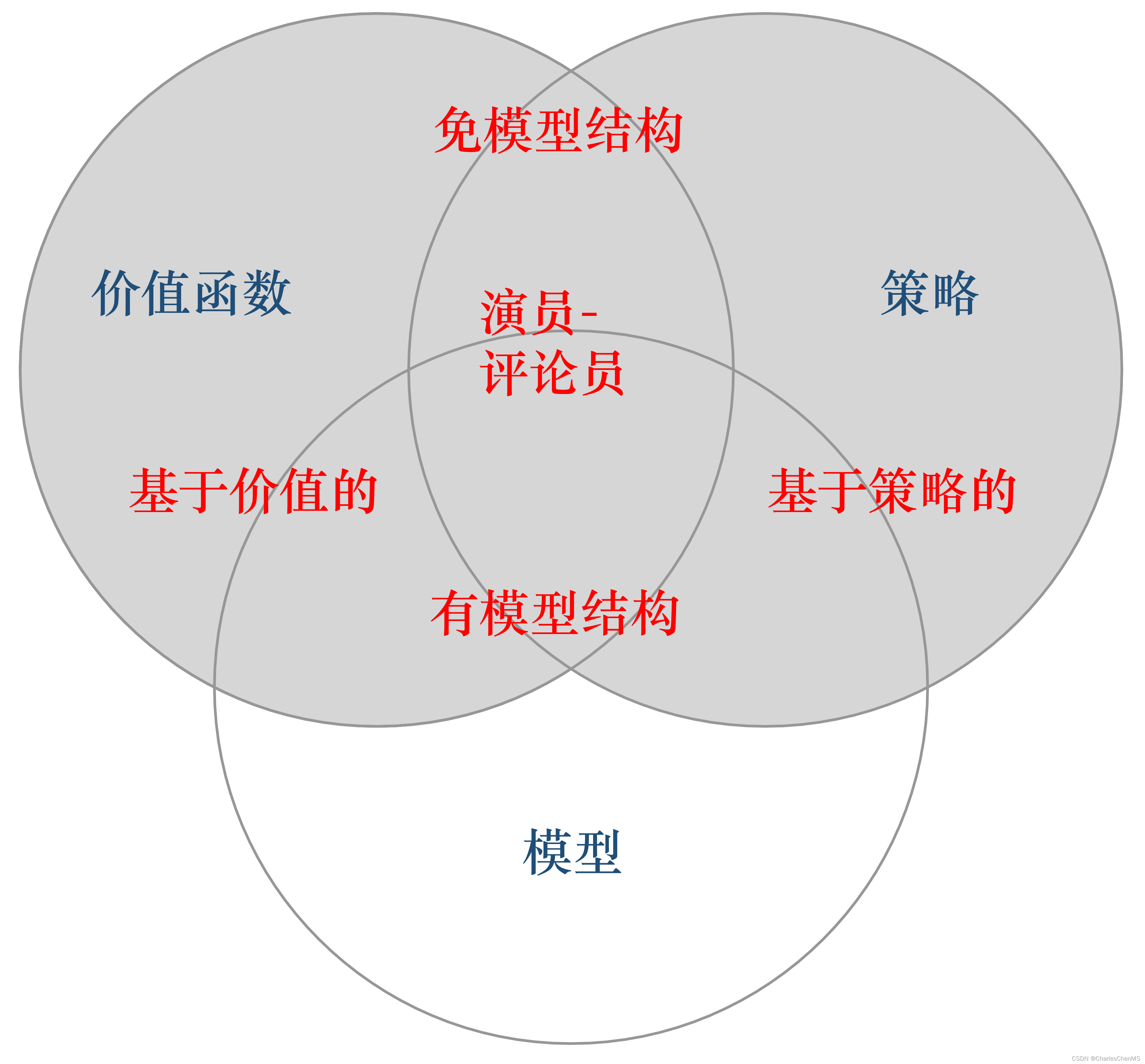
前面提到很多经典的强化学习算法都是免模型的,换句话说在这种情况下环境的状态转移概率是未知的,这种情况下会去近似环境的状态价值函数,这其实跟状态转移概率是等价的,我们把这个过程称为预测。换句话说,预测的主要目的是估计或计算环境中的某种期望值,比如状态价值函数 或动作价值函数 。例如,我们正在玩一个游戏,并想知道如果按照某种策略玩游戏,我们的预期得分会是多少。
而控制的目标则是找到一个最优策略,该策略可以最大化期望的回
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2321
2321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









