






 本文指导如何在WindowsSubsystemforLinux(WSL)中安装Ubuntu,以及如何正确配置CUDA、cuDNN,以支持PyTorch的GPU使用。包括CUDA版本选择、驱动管理、环境变量设置和验证步骤。
本文指导如何在WindowsSubsystemforLinux(WSL)中安装Ubuntu,以及如何正确配置CUDA、cuDNN,以支持PyTorch的GPU使用。包括CUDA版本选择、驱动管理、环境变量设置和验证步骤。
安装驱动
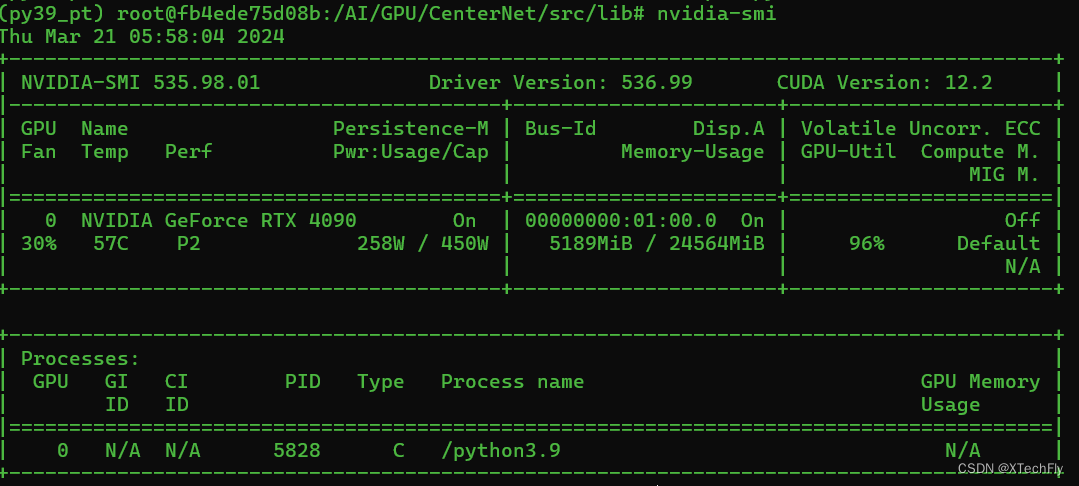
首先需要明确的是,在WSL下安装Ubuntu,如果要使用主机的GPU卡,只需要在主机Windows上安装驱动,Linux中不需要安装驱动,可以在Linux中使用nvidia-smi命令查看驱动版本。
安装CUDA
避坑注意事项:如果要使用pytorch,建议最高安装CUDA11.8,因为CUDA版本再往上当前没有配套的pytorch版本。
CUDA下载地址:https://developer.nvidia.com/cuda-toolkit-archive
安装WSL Ubuntu版本,点击以下链接直达:
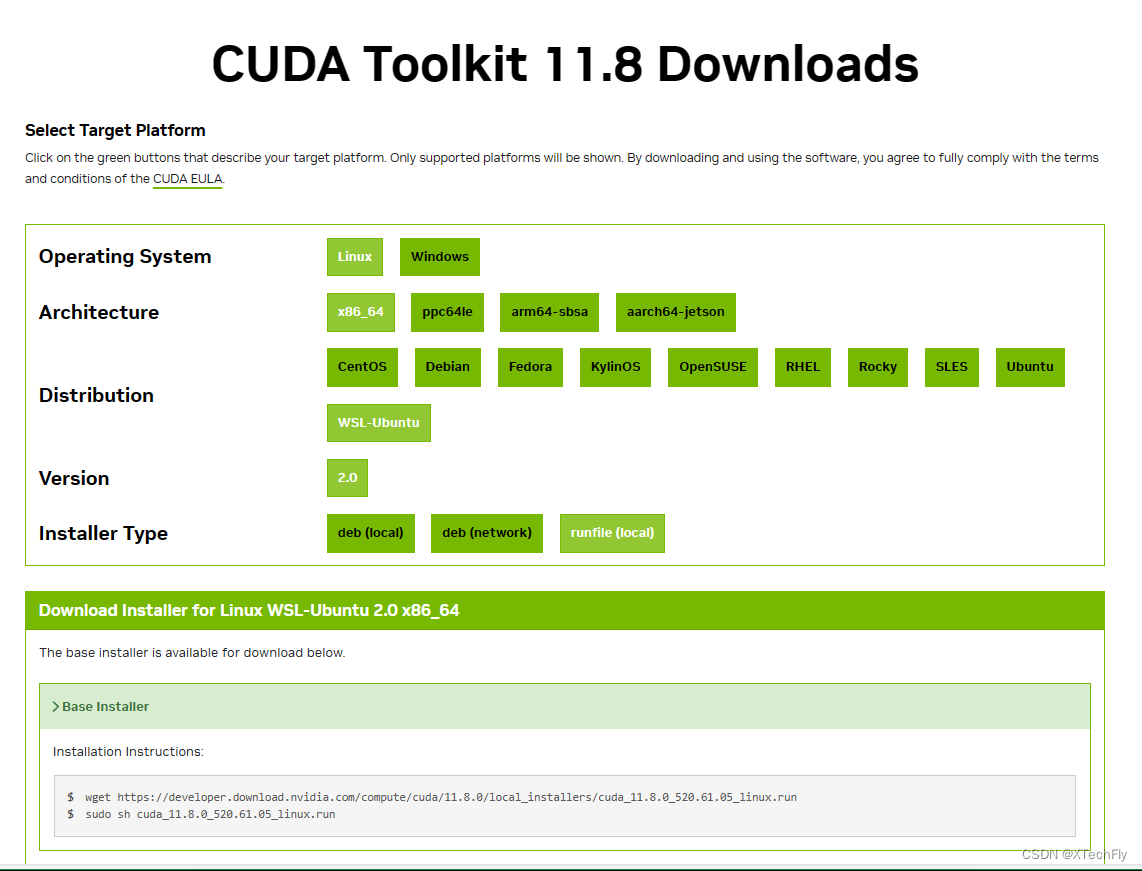
CUDA11.8_Linux下载
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.runCUDA安装配置
sudo sh cuda_11.8.0_520.61.05_linux.run
rm -rf /usr/local/cuda
ln -s /usr/local/cuda-11.8 /usr/local/cuda
vi ~/.bashrc
# 添加如下环境变量
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH验证CUDA安装
nvcc -V
安装cuDnn
cuDnn需要配套CUDA版本,配套参考cuDnn官网:
cuDnn下载地址:https://developer.nvidia.com/rdp/cudnn-archive
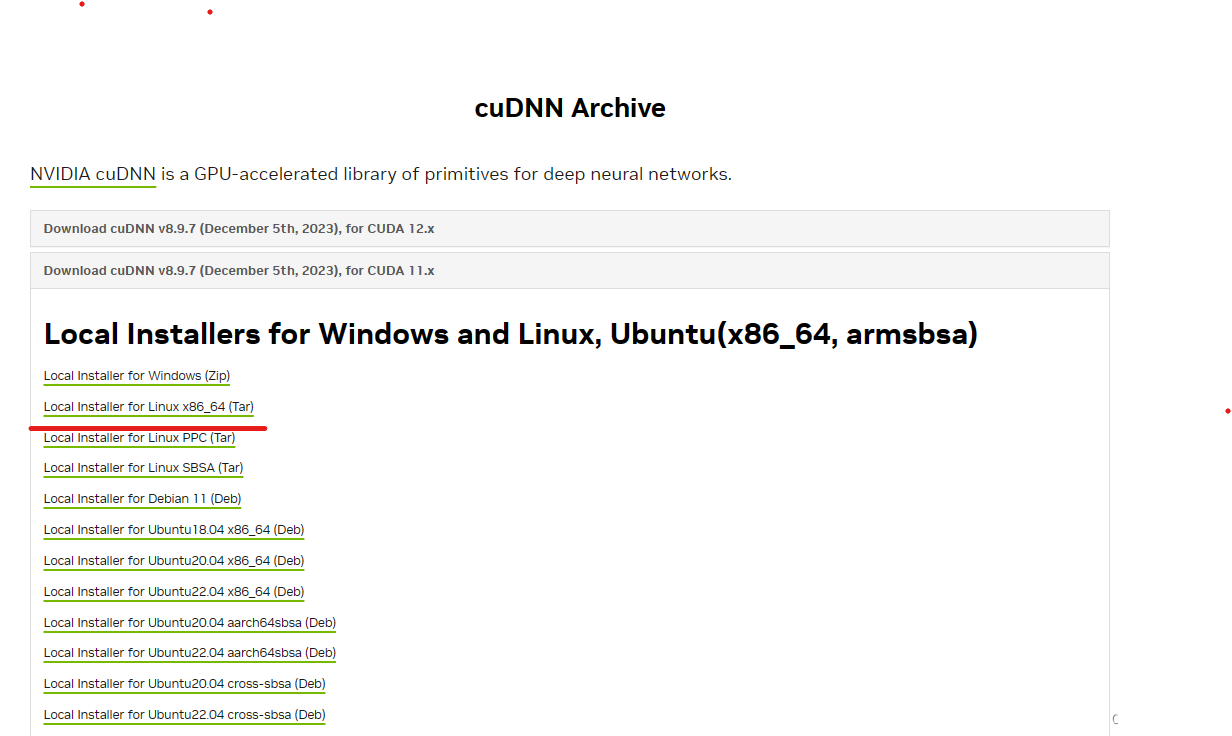
cuDNN8.9.7_Linux下载
cuDnn安装配置
tar -xvf cudnn-linux-x86_64-8.9.7.29_cuda11-archive.tar.xz
cd cudnn-*-archive
sudo cp include/cudnn*.h /usr/local/cuda/include
sudo cp -P lib/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*Pytorch安装
Pytorch与CUDA配套
Pytorch与CUDA配套关系参考:https://pytorch.org/get-started/locally/
使用如下命令可以安装CUDA11.8配套的pytorch,有时候安装不成功,可能与CUDA安装有关系,待验证。
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
如果你的硬件配置和我一样,建议直接下载以下链接的whl进行安装。实测OK。
torch和torchvision配套
建议参考: https://github.com/pytorch/vision#installation
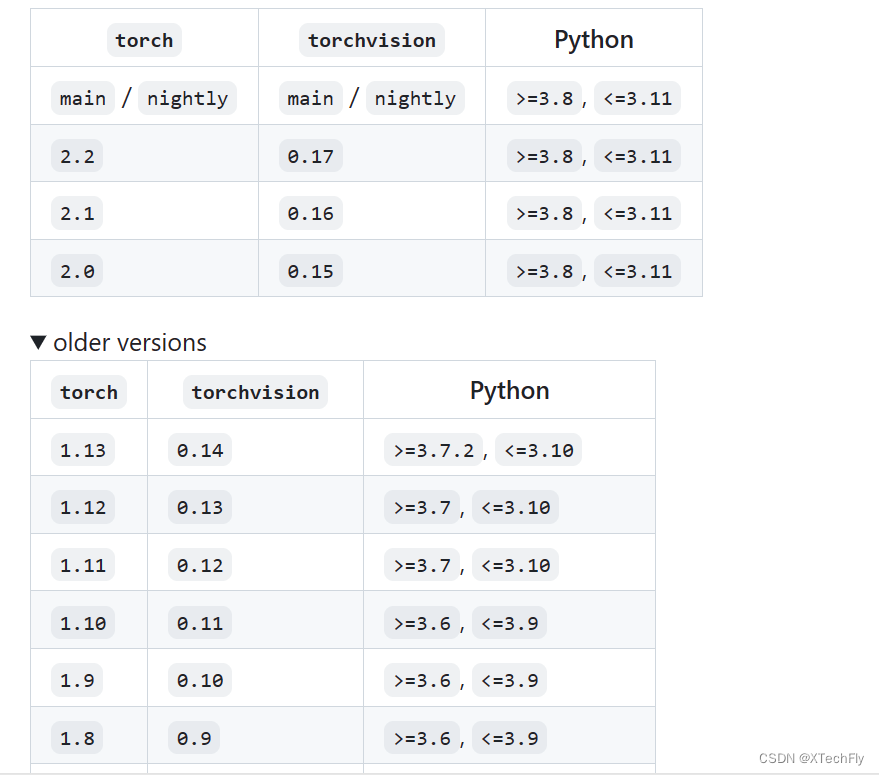
可以看到如果选择torch版本是2.1.0,可以安装0.16版本的torchvision。
torch和torchvision下载地址: https://download.pytorch.org/whl/torch_stable.html
torch和torchaudio配套
建议参考:Installing pre-built binaries — Torchaudio 2.2.0.dev20240323 documentation
torch2.1.0下载地址
https://download.pytorch.org/whl/cu118/torch-2.1.0%2Bcu118-cp39-cp39-linux_x86_64.whl
torchvision0.16.0下载地址
https://download.pytorch.org/whl/cu118/torchvision-0.16.0%2Bcu118-cp39-cp39-linux_x86_64.whl
torchaudio2.1.0下载地址
迅雷云盘备份
https://pan.xunlei.com/s/VNtUlafg0sA20sbCU3fsEsaIA1?pwd=uiy7#

















 826
826

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









