







本文介绍了基于Python的分布式框架Ray的基本安装与使用。Ray框架下不仅可以通过conda和Python十分方便的构建一个集群,还可以自动的对分布式任务进行并发处理,且支持GPU分布式任务的提交,极大的简化了手动分布式开发的工作量。
技术背景
假设我们在一个局域网内有多台工作站(不是服务器),那么有没有一个简单的方案可以实现一个小集群,提交分布式的任务呢? Ray为我们提供了一个很好的解决方案,允许你通过conda和Python灵活的构建集群环境,并提交分布式的任务。其基本架构为:
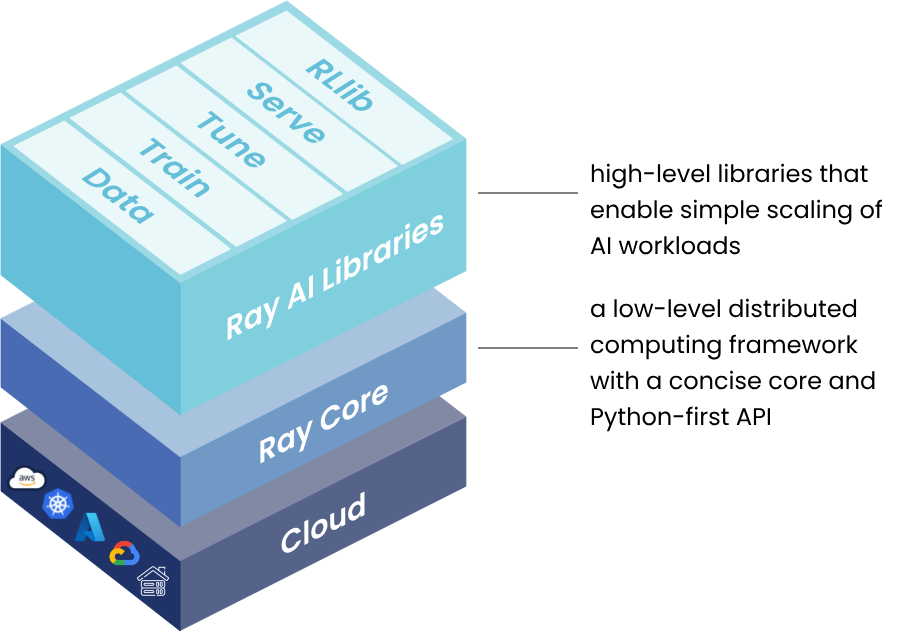
那么本文简单的介绍一下Ray的安装与基本使用。
安装
由于是一个Python的框架,Ray可以直接使用pip进行安装和管理:
但是需要注意的是,在所有需要构建集群的设备上,需要统一Python和Ray的版本,因此建议先使用conda创建同样的虚拟环境之后,再安装统一版本的ray。否则在添加集群节点的时候就有可能出现如下问题:
启动和连接服务
一般在配置集群的时候可以先配置下密钥登陆:
就这么两步,就可以配置远程服务器ssh免密登陆(配置的过程中有可能需要输入一次密码)。然后在主节点(配置一个master节点)启动ray服务:
这就启动完成了,并给你指示了下一步的操作,例如在另一个节点上配置添加到集群中,可以使用指令:
但是前面提到了,这里要求Python和Ray版本要一致,如果版本不一致就会出现这样的报错:
到这里其实Ray集群就已经部署完成了,非常的简单方便。
基础使用
我们先用一个最简单的案例来测试一下:
这个Python脚本打印了远程节点的计算资源,那么我们可以用这样的方式去提交一个本地的job:
这里的信息说明,远程的集群只有一个节点,该节点上有48个可用的CPU核资源。这些输出信息不仅可以在终端窗口上看到,还可以从这里给出的dashboard链接里面看到更加详细的任务管理情况:
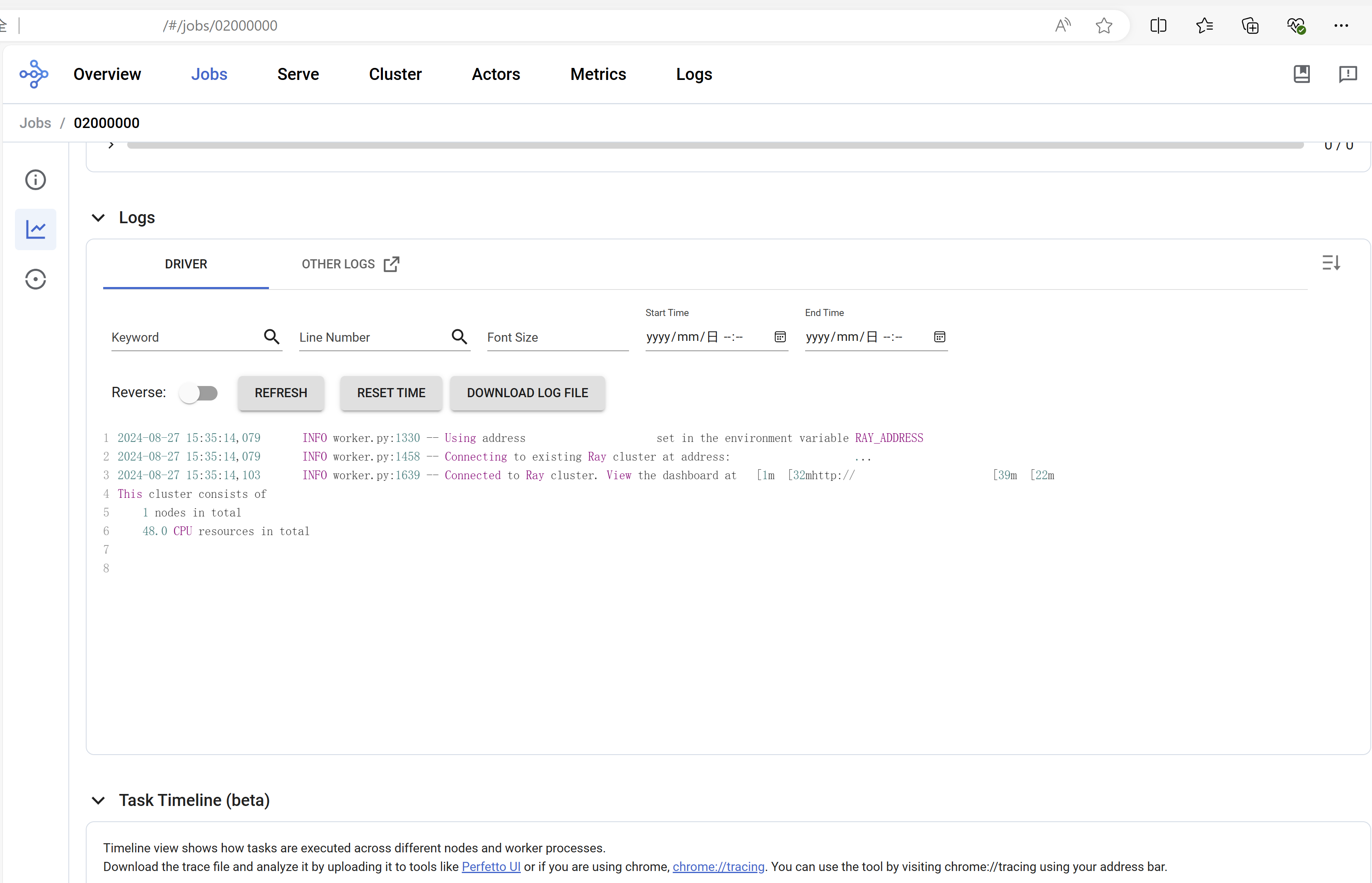
这里也顺便提交一个输出软件位置信息的指令,确认下任务是在远程执行而不是在本地执行:
返回的日志为:
这里可以看到,提交的任务中numpy是保存在mindspore-latest虚拟环境中的,而本地的numpy不在虚拟环境中,说明任务确实是在远程执行的。类似的可以在dashboard上面看到提交日志:
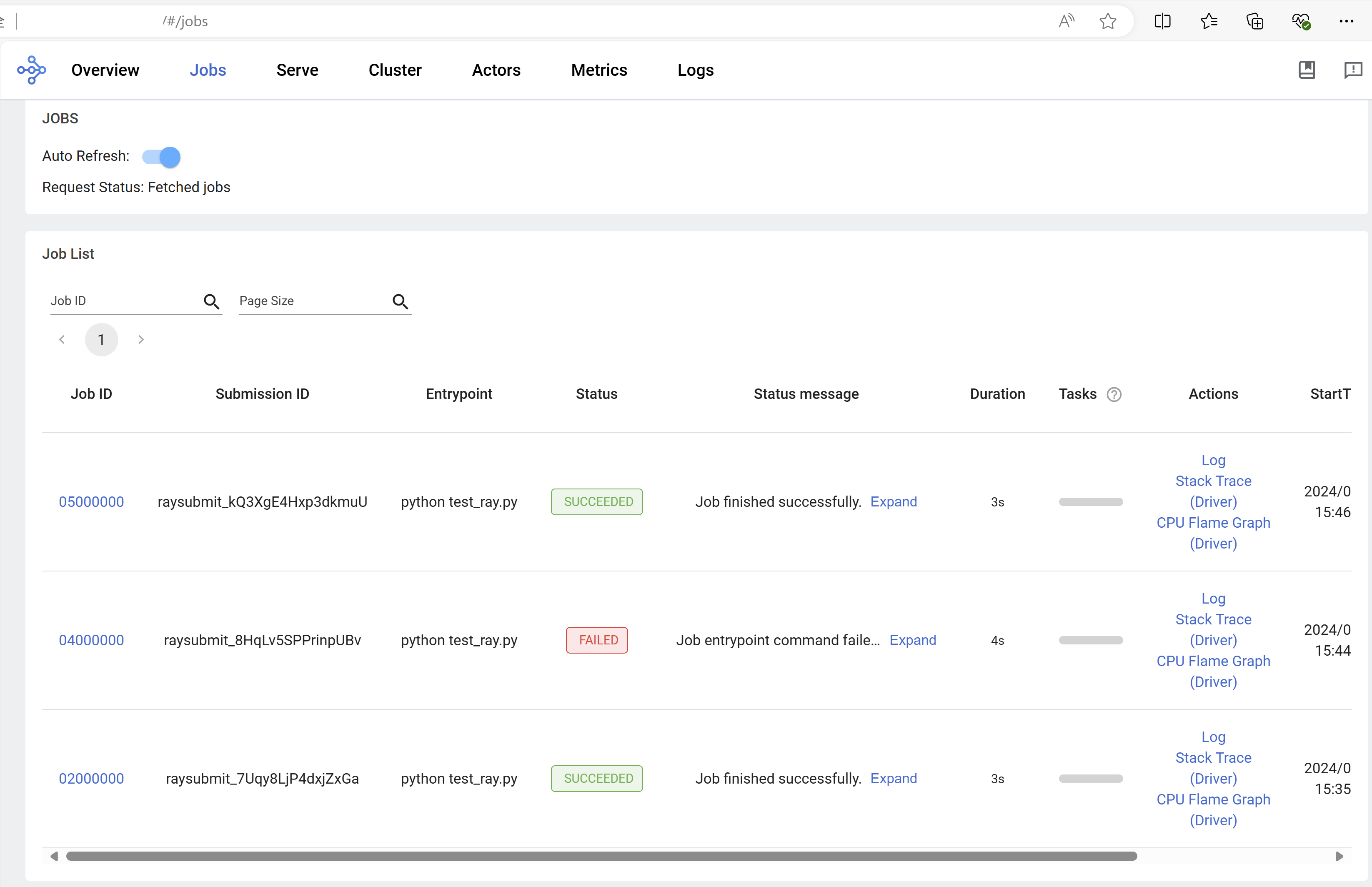
接下来测试一下分布式框架ray的并发特性:
这个案例的内容是用蒙特卡洛算法计算圆周率的值,一次提交10个任务,每个任务中撒点100000个,并休眠2s。那么如果是顺序执行的话,理论上需要休眠20s。而这里提交任务之后,输出如下:
总的运行时间在7.656秒,其中5s左右的时间是来自网络delay。所以实际上并发之后的总运行时间就在2s左右,跟单任务休眠的时间差不多。也就是说,远程提交的任务确实是并发执行的。最终返回的结果进行加和处理,得到的圆周率估计为:3.141656。而且除了普通的CPU任务之外,还可以上传GPU任务:
这个任务是用mindspore简单创建了一个Tensor,并计算了Tensor的总和返回给本地,输出内容为:
返回的计算结果是6.0,那么也是正确的。
查看和管理任务
前面的任务输出信息中,都有相应的job_id,我们可以根据这个job_id在主节点上面查看相关任务的执行情况:
可以查看该任务的输出内容:
还可以终止该任务的运行:
总结概要
本文介绍了基于Python的分布式框架Ray的基本安装与使用。Ray框架下不仅可以通过conda和Python十分方便的构建一个集群,还可以自动的对分布式任务进行并发处理,且支持GPU分布式任务的提交,极大的简化了手动分布式开发的工作量。
作者ID:DechinPhy















 2271
2271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









