







《Mobility-Aware Computation Offloading in Edge Computing Using Machine Learning》 论文阅读笔记一
Common sense
计算卸载(computing offloading) 是边缘计算中关键技术之一,其主要关注的三个问题为:卸载谁,什么时间卸载,卸载到哪里。关于计算卸载的理论研究较为广泛,绝大部分将问题建模成为整数规划/混合整数规划问题等,通过采用凸优化理论,启发式算法,博弈论,排队论,马尔可夫决策,深度强化学习等方法进行近似求解。
虽然该方面的理论相对比较完备,但依然在建模和方法等层面依然存在完善的空间。大规模的边缘节点、异构平台、信道的时变性、用户空间的移动性等,需要不同的模型如动态模型、分布式模型、不确定模型等。同样地,对于求解方法来说,智能化将是下一步研究的重点,如何兼顾准确率与计算效率,是需要考虑的问题。
在应用层面,AR/VR、UAV、工业物联网等场景中,合理进行计算卸载能够提供高质量/低延时的服务。
计算迁移(computation migration) 发生在异构多服务器场景中,当用户移动过程中离一台新的边缘服务器更近时,网络控制器将把计算任务迁移到新的服务器上,或者在原有服务器上完成计算后将计算结果返回给新的服务器,以便用户及时得到结果。基于random-walk移动模型,问题被建模为MDP问题。在MEC的移动管理中,计算迁移是一种十分有效的方式。
Question
在进行计算卸载时,边缘侧用户常常由于其在时间/空间上的不确定性使得其应用特征(application specifications)发生改变,从而使得计算卸载的周转时间(trunaround time)延长,如何设计有效的算法减少周转时间成为本文要解决的问题。
Analysis
边缘计算的优势为:比之用户设备,具有更多的计算资源和更快速的计算能力,且由于其分布在用户的边缘侧,用户能够将计算敏感型任务分配到边缘服务器上,从而降低任务的处理时延。
而当用户设备动态变化时,用户与边缘服务器之间的距离将随之发生变化,相应地,卸载时延将会增加,从而削弱了边缘计算的优势。为了保证原有的低时延目标,需要考虑将动态不确定性转化为可预测确定性。
Contributions
- 采用机器学习的矩阵补全(matrix completion)方法,利用已有的application specification预测app未来的specification,通过预测,能够提前规划好卸载or迁移的cloudlets,从而优化卸载决策。
- 提出两种卸载方法S-OMAC和G-OMAC,最小化移动应用的turnaround time和迁移的cloudlets数量。
- S-OAMC是基于采样的近似动态规划方法,能够实现负载均衡;G-OAMC采用贪心思想,能够快速获得结果。
- 将以上两种方法与benchmark/SOTA对比,能够找到低迁移率的近似优化trunaround time。
Related work

与现有的工作相比,本文的工作充分考虑了表中提到的几点:
- 多用户(device)多服务器(cloudlet)场景
- 考虑用户设备的移动性
- 以服务器的资源有限作为约束,目标为最小化时延
- 首次提出turnaround time这一评价指标,综合考虑通信时延、计算时延和迁移时延
- 使用真实的数据集(walk、drive等),更加贴合用户实际生活场景
- 使用采样的方法
- 采用预测的方法
System model
假设有n个applications,分别记为U = {u1,u2,…un},有m个cloudlets,分别记为C = {c1,c2,…,cm}计算卸载发生的时隙记为1,…T。
每个用户在t时刻的特征定义为:
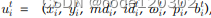
其中,xi/yi为app的位置,md为迁移数据量,id为卸载数据量,w为计算所需指令数,p为所需处理速度,b为所需带宽。为简化建模,t>=2时计算迁移才会发生,在此之前id=md。
每个cloudlet cj 在t时刻的特征定义为:
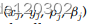
其中,xj/yj为cloudlet的位置,pj为总的处理速度,beta为总的带宽。
优化目标:最小化turnaround time
turnaround time = offloading time + migration time + computation time
offloading time = propagation latency + transmission latency
migration time = propagation latency + transmission latency
定义以下时延:

前者为传播时延,d为距离,theta为传播速度;后者为传输时延,s为数据量,beta为带宽。
使用f来表示app与cloudlet之间、cloudlet与cloudlet之间的距离

定义两个变量,分别代表是否进行计算卸载和计算迁移。

那么问题可以建模为下图:

目标函数为turnaround time最小
约束为:
(3)t时刻app ui只能迁移到一个cloudlet上【二进制卸载】
(4)t时刻卸载到cj 上的所有app的处理速度需求不能超过cj的总处理需求
(5)t时刻卸载到cj 上的所有app的带宽需求不能超过cj的总带宽需求
(6)确保不等式右边的两个变量为1时左边的变量也为1
(7)t时刻app ui是否卸载到cj上
(8)t时刻app ui是否从cj迁移到ck
该问题是一个广义指派问题(generalized assignment problem, GAP)的实例,被证明为NP-hard问题。
关于GAP,求解方法可以分为以下几类:元启发式算法、松弛算法、精确算法等。元启发式算法有:遗产算法、变领域搜索、禁忌搜索等方法;松弛算法最常用的是基于拉格朗日松弛(LR)。也可采用蜜蜂算法求解。
Sampling-based offloading to cloudlets
S-OAMC算法的思路:通过最小化需要迁移的数量来最小化turnaround time。
算法如下:

输入参数解释:
w为窗口大小,表示未来需要预测的时隙数量,若w=5,在t=1时刻进行预测,那么将会得到时刻2到时刻6的app特征。
gama为折损因子,实验中取0.3,算法中表示未来不同时刻对当前决策的影响权重,离当前时刻越近,则权重越大,离当前时刻越远,则权重越小。
算法流程:
- 使用Ui来维护app i 从第一个时隙到当前时隙t的每个时隙的特征,使用Ri来维护app i从第一个时隙到当前时隙t的每个时隙所卸载的cloudlet。将它们都初始化为空集。
- 对每个时隙内的进行迭代:若t mod w为0,则说明该时刻需要进行预测(阶段性预测,并非每时每刻都得预测),调用predict函数,得到t+1——t+w时刻的app i 的特征值。
- 对于所有的cloudlet,计算app i 卸载到cj 上的代价vij。该代价包括卸载时延和计算时延。当t >= 2且cj并非上一个时刻的迁移对象,那么需要将迁移时延计算后加入到vij中。
- 循环调用assign函数直到所有时刻都被分配了cloudlet。assign函数返回t时刻的决策(即t时刻各app的分配情况),分配完毕,更新V,U,C:Ut删除已分配app的特征;C在分配后更新总处理速度和带宽资源;Vt则删除已分配aa对应的行【代码里没有消除这一操作】
- 分配完毕,更新R,记录每个时刻app i 的卸载或迁移情况。
算法测试:
可得到整个T时间内的总trunaround time
得到该算法的offloading time, computation time, migration time
Predict
S-OAMC中调用predict函数进行预测,该方法主要基于矩阵补全来获得下w个时隙内的app 特征值。
矩阵补全(matrix completion)是一种机器学习方法,通过矩阵分解能够补全部分缺失值。常用的分解方法有奇异值分解(Singular Value Decomposition, SVD)。利用SVD实现,能够用小得多的数据集来表示原始数据集,基于这个视角,我们可以把SVD看成是从有噪声的数据中抽取相关特征。
对原矩阵进行分解,使用SVD分解时,将其分解为三个矩阵,此时会构建出矩阵
Σ
\Sigma
Σ,该矩阵只有对角元素,其他元素均为0,且
Σ
\Sigma
Σ的对角元素是从大到小排列的,这些对角元素称为奇异值。在科学和工程中,一直存在这样一个普遍事实:在某个奇异值的数目(r 个)之后,其他的奇异值都为0,则意味着数据集中仅有r个重要特征,其余特征都是噪声或冗余特征。
假设对矩阵B进行分解,分解为U,
Σ
\Sigma
Σ,V三个矩阵,
可以采用凸优化、梯度下降等方法估计出缺失值。文章采用TFOCS工具来估计矩阵X。

在进行矩阵分解时,每个矩阵都是一个特征值,row为app的编号,column为时隙编号。将补全后的矩阵直接写入文件。
Assign
S-OAMC调用assign求解GAP问题,通过采样能够加快动态规划寻找近似解的过程。
算法如下:

算法流程:
- 使用矩阵G与N存储V的中间变量。
- 对于所有的cloudnet cj来说,调用一次DP-APC函数,得到在cj 上的app分配情况,分配完成后,对代价V进行更新,利用g存储这次v卸载的代价。对于卸载到cj上的app而言,g=v;对于cj来说,调用DP-APC已经将其尽可能利用,不再接收其他的app分配,所以g=v;对于其他的而言,没有实行卸载,则g=0。
- 用原来的代价减去分配过程中的代价,将其赋值给N。再将N赋值给V,表示V在一轮分配后的代价更新。这里需要注意:新的V中vij有可能会小于0,因为DP-APC只考虑了如何尽可能多地将app分配到cj上,没有考虑卸载到cj上对于ui来说是否是最小的代价,若不是最小代价,那么在v-g时,得到的结果为负值。
- S为t时刻所有cloudlet的分配情况,由于算法在assign函数后才会更新R的值,所以无法确保每个app都被分配到了一个cloudlet上。所以需要对被分配到多个cloudlet上的app做调整。
- 最后返回的S,表示t时刻的cj分配情况。
DP-APC
DP-APC基于采样策略对cj做卸载分配。
算法如下:

算法流程:
- 按照代价值v升序的方式对所有的app进行排序,选择出前 η \eta η个v值不为无穷的app。(v值无穷的情况,对应在S-OAMC中计算v值时,v为负值的情形,个人认为不存在这种情况)。
- 在这些app中,用M记录其中v值最大的app的v,对于所有选出的app,重新计算赋值v’=M+1-v,保证了v’都是正值。此时app的排序成为了按照v’降序排列。用M’记录最大的v’。
- 计算 λ \lambda λ,,若 λ \lambda λ小于1,则令其等于1。【关于为何要计算 λ \lambda λ不太清楚,可能需要参考文献】
- 对于选中的app,计算r(r含义等同于代价值,只是对原来的v进行了调整)。用r’记录最大的r,即最大的代价值。
- 接下来也运用动态规划的方法进行求解。数组A[i]含义是代价为i的结构,A[i].p是代价为i时需要的处理速度,A[i].b是代价为i时需要的带宽。
- A的大小为采样数*最大代价,将A[i]初始化为无穷,表示此时还没有进行分配。令A[0].p=A[0].b=0,表示无代价时不需要处理速度和带宽这些资源。
- 外层循环为i=1到采样数,内层循环为(i-1)r*到0,对于A[k+r]来说,若A[k+r].p > A[k].p + pi,那么更新A[k+r].p = A[k].p + pi,表示代价为k+r时需要的处理速度是代价为k时的处理速度+代价为r的app所需的处理速度,此时表明了代价为k+r时,被分配到cj上的app是代价为k时被分配到cj上的app+ 当前r对应的app。
- 找到满足A[k].p <= cj.p && A[k].b <= cj.b的最大k,得到代价为k时的分配结果,返回该分配结果。
动态规划的过程举例:
假设采样数为3,采样的app编号、对应的r、对应的b、对应的p如下表所示:
| 索引 | 1 | 2 | 3 |
| app编号 | 160 | 196 | 143 |
| r值 | 11 | 10 | 8 |
| 对应的b | 3 | 6 | 4 |
| 对应的p | 9 | 5 | 1 |
A[k + rij] = A[0 + 11] = A[11]
A[11].b = A[0].b + bi = 3,A[11].p = A[0].p + pi = 9
当i = 2时,k = (i - 1)r* = 11, rij = 10,
| k | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| k+ rij | 21 | 20 | 19 | 18 | 17 | 16 | 15 | 14 | 13 | 12 | 11 | 10 |
| A[k].b | 3 | inf | inf | inf | inf | inf | inf | inf | inf | inf | inf | 0 |
| A[k+rij].b | 9 | inf | inf | inf | inf | inf | inf | inf | inf | inf | inf | 6 |
| A[k].p | 9 | inf | inf | inf | inf | inf | inf | inf | inf | inf | inf | 0 |
| A[k+rij].p | 14 | inf | inf | inf | inf | inf | inf | inf | inf | inf | inf | 5 |
A[21]:代价为21时,分配策略为app160和app196。
A[11]:代价为11时,分配策略为app160。
A[10]:代价为10时,分配策略为为app196。
当i = 3时,k = (i - 1) r* = 22, rij = 8,
A[22 + 8] = inf,with A[22] = inf
A[21 + 8].b = A[21].b + b3 = 9 + 4 = 13,A[21 + 8].p = A[21].p + p3 = 14 + 1 = 15,代价为29时,分配策略为app160、app196和app143。
A[11 + 8].b = A[11].b + b3 = 3 + 4 = 7,A[11 + 8].p = A[11].p + p3 = 9 + 1 = 10,代价为19时,分配策略为app160、app143。
A[10 + 8].b = A[10].b + b3 = 6 + 4 = 10,A[10 + 8].p = A[10].p + p3 = 5 + 1 = 6,代价为18时,分配策略为app196、app143。
Greedy offloading to cloudlets
G-OAMC基于贪心的策略,通过将app分配到已经使用过的cloudlet上,来尽可能减少使用的cloudlets。能够快速求解,但无法保证近似最优解。
算法如下:

算法流程:
- 当t mod w = 0时,预测ui在下w个时隙的特征值,用bmax记录下w个时隙内预测到的最大带宽,用pmax记录下w个时隙内预测到的最大处理速度,用以确保分配了足够多的资源供卸载使用。
- 以下式作为优先级排序标准式子的值越小,优先级越高,即代价v越小、bmax和pmax越大,优先级越高。

- 对每一个cj,将app们按照上述公式进行升序排序,遍历所有app,若当前app的bmax和pmax在cj.b和cj.p的范围内,则马上分配,更新cj,继续下一个app,直至当前的cj被全部占用。
- t mod w != 0时,表明该段时间里未发生卸载或迁移,更新R。
比较S-OAMC和G-OAMC
- 都是一个一个cloudlet进行分配,不同在于S-OAMC进行了采样,使得每个cloudlet上面的app负载是均衡的;而G-OAMC则贪心尽可能少用cloudlet使得负载不均衡。
- 都采用了预测得到未来特征值,不同在于S-OAMC将代价值作为一个关键的影响因素去动态规划,考虑了迁移情况,目标为尽可能减少迁移的数量;G-OAMC则只使用预测值中的最大值进行贪心求解,无法得到全局最优,目标为尽可能减少使用的cloudlet数量。
(未完待续,参考文献下一篇列出)















 1584
1584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









