






MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
MobileNets:用于移动视觉应用的高效卷积神经网络
Mobile:可以指手机等移动端;
MobileNet是Google在2017年提出的轻量级深度神经网络,专门用于移动端、嵌入式这种计算力不高、要求速度、实时性的设备。
发表时间:[Submitted on 17 Apr 2017];
发表期刊/会议:Computer Vision and Pattern Recognition;
论文地址:https://arxiv.org/abs/1704.04861
代码地址:;
关键词:移动端 轻量级 深度可分离卷积‘
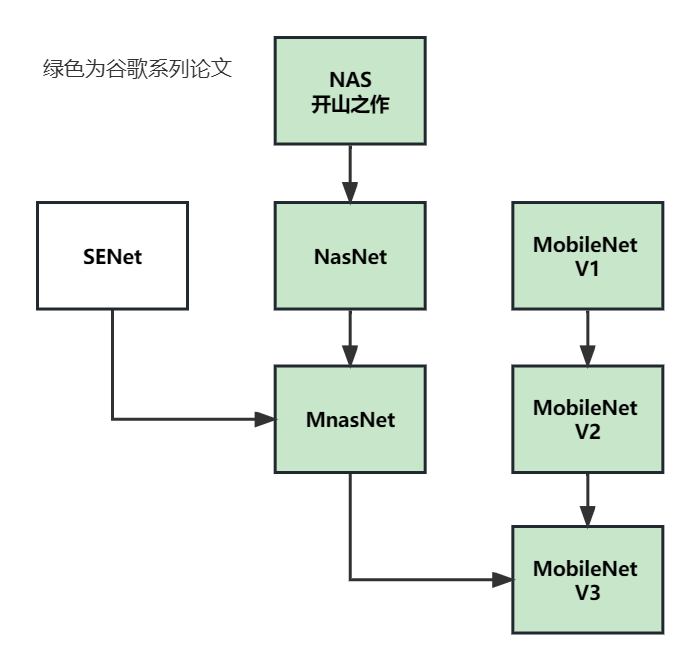
VAN模型建立在此文章基础上;
系列论文阅读顺序:
0 摘要
本文为移动端和嵌入式视觉应用程序提供了一类称为MobileNets的高效模型。MobileNets基于一种简化的架构,该架构使用深度可分离卷积(depth-wise separable convolutions)来构建轻量级深度神经网络;
本文引入了两个简单的全局超参数,可以有效地在延迟(latency)和准确性(accuracy)之间进行权衡。这些超参数允许根据问题的约束条件为应用程序选择合适大小的模型;
进行广泛实验,如包括分类问题、对象检测、细粒度分类、人脸属性和大规模地理定位等,MobileNet性能均优;
1 简介
CNN总的趋势是通过更深更复杂的网络来实现更高的精度,但这并不总是有效的,更深更复杂的网络带来更高的计算复杂度,不适合自动驾驶等真实场所;
本文介绍一种更为高效的网络架构和两个超参数,来建议效率高,延迟低的小模型,可以轻松应用于移动端和嵌入式视觉。
2 相关工作
小而有效的神经网络:许多方法通常通过压缩预训练网络或直接训练小网络来实现;
(本文的方法允许开发人员为其应用程序专门选择符合延迟、大小的网络模型)
【其他相关网络】
Factorized Networks[34]引入了类似的因子化卷积(factorized convolution)以及拓扑连接;
Xception network[3]演示了如何放大深度可分离滤波器,以超越InceptionV3网络;
Squezenet[12],使用瓶颈方法设计一个非常小的网络。
MobileNets的应用,见图1:

3 方法
3.1 深度可分离卷积
MobileNet模型基于深度可分离卷积,这是一种分解卷积的形式,就是将标准卷积分解为深度卷积(depthwise convolution)和1×1卷积(1×1卷积又称为逐点卷积)。见下图示例:

对于MobileNets,深度卷积将单个滤波器应用于每个输入通道。然后应用1×1卷积来组合深度卷积的输出。标准卷积在一个步骤中将输入滤波并组合成一组新的输出。深度可分离卷积将其分为两层,一层用于滤波,另一层用于合并。这种因子分解具有显著减少计算和模型大小的效果。
变量解释
输入:图像F:( D F × D F × M D_F × D_F × M DF×DF×M),M是输入通道数量,假设 D F = 5 D_F = 5 DF=5;
输出:特征图G:( D F × D F × N D_F × D_F × N DF×DF×N),N是输出通道数量;
卷积核K:( D K × D K × M × N D_K × D_K × M × N DK×DK×M×N), D K D_K DK是卷积核大小;
标准卷积的计算成本为:

深度卷积计算成本:

深度可分离卷积计算成本:

c o s t s t d = 3 ∗ 3 ∗ 3 ∗ 4 ∗ 5 ∗ 5 = 2700 cost_{std} = 3 * 3 * 3 * 4 * 5 * 5 = 2700 coststd=3∗3∗3∗4∗5∗5=2700
c o s t d w = 3 ∗ 3 ∗ 3 ∗ 5 ∗ 5 = 675 cost_{dw}=3*3*3*5*5=675 costdw=3∗3∗3∗5∗5=675
c o s t p w = 3 ∗ 4 ∗ 5 ∗ 5 = 300 cost_{pw}=3*4*5*5=300 costpw=3∗4∗5∗5=300
c o s t s e p a r a b l e = c o s t d w + c o s t p w = 675 + 300 = 975 < c o s t s t d = 2700 cost_{separable} = cost_{dw} + cost_{pw} = 675 + 300 = 975 < cost_{std}=2700 costseparable=costdw+costpw=675+300=975<coststd=2700
MobileNet使用3 * 3 卷积核,实验部分证明,可以比标准卷积核快8~9倍;
3.2 网络架构与训练
3.2.1 网络架构
MobileNet体系结构定义见表1。
所有层之后都是 batch Norm和ReLU激活,除了最后的FC层,FC层之后接入softmax(见图3);
MobileNet有28层;


对应代码:
import torch
import torch.nn as nn
class MobleNetV1(nn.Module):
def __init__(self, num_classes):
super(MobleNetV1, self).__init__()
self.conv1 = self._conv_st(3, 32, 2)
self.conv_dw1 = self._conv_dw(32, 64, 1)
self.conv_dw2 = self._conv_dw(64, 128, 2)
self.conv_dw3 = self._conv_dw(128, 128, 1)
self.conv_dw4 = self._conv_dw(128, 256, 2)
self.conv_dw5 = self._conv_dw(256, 256, 1)
self.conv_dw6 = self._conv_dw(256, 512, 2)
self.conv_dw_x5 = self._conv_x5(512, 512, 5)
self.conv_dw7 = self._conv_dw(512, 1024, 2)
self.conv_dw8 = self._conv_dw(1024, 1024, 1)
self.avgpool = nn.AvgPool2d(kernel_size=7, stride=1)
self.fc = nn.Linear(1024, num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.conv_dw1(x)
x = self.conv_dw2(x)
x = self.conv_dw3(x)
x = self.conv_dw4(x)
x = self.conv_dw5(x)
x = self.conv_dw6(x)
x = self.conv_dw_x5(x)
x = self.conv_dw7(x)
x = self.conv_dw8(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
y = torch.softmax(x)
return x, y
def _conv_x5(self, in_channel, out_channel, blocks):
layers = []
for i in range(blocks):
layers.append(self._conv_dw(in_channel, out_channel, 1))
return nn.Sequential(*layers)
def _conv_st(self, in_channels, out_channels, stride):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
)
def _conv_dw(self, in_channels, out_channels, stride):
return nn.Sequential(
nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=stride, padding=1, groups=in_channels, bias=False),
nn.BatchNorm2d(in_channels),
nn.ReLU(),
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
)
net = MobleNetV1(1000)
x = torch.rand(1,3,224,224)
for name,layer in net.named_children():
if name != "fc":
x = layer(x)
print(name, 'output shape:', x.shape)
else:
x = x.view(x.size(0), -1)
x = layer(x)
print(name, 'output shape:', x.shape)
# conv1 output shape: torch.Size([1, 32, 112, 112])
# conv_dw1 output shape: torch.Size([1, 64, 112, 112])
# conv_dw2 output shape: torch.Size([1, 128, 56, 56])
# conv_dw3 output shape: torch.Size([1, 128, 56, 56])
# conv_dw4 output shape: torch.Size([1, 256, 28, 28])
# conv_dw5 output shape: torch.Size([1, 256, 28, 28])
# conv_dw6 output shape: torch.Size([1, 512, 14, 14])
# conv_dw_x5 output shape: torch.Size([1, 512, 14, 14])
# conv_dw7 output shape: torch.Size([1, 1024, 7, 7])
# conv_dw8 output shape: torch.Size([1, 1024, 7, 7])
# avgpool output shape: torch.Size([1, 1024, 1, 1])
# fc output shape: torch.Size([1, 1000])
3.2.2 训练细节
MobileNet模型在TensorFlow中使用RMSprop(优化器)进行训练,异步梯度下降算法。
与训练大型模型相反,本文使用较少的正则化和数据增强,因为小型模型较少出现过拟合问题。
在训练MobileNets时,不使用side heads?或标签平滑,通过限制大型初始训练中使用的small crop的大小,减少图像失真的数量。
此外,本文发现在深度滤波器上放置很少或没有权重衰减(l2正则化)非常重要,因为它们中的参数太少。
3.3 第一个参数α:Thinner Models
尽管基本的MobileNet架构已经很小,延迟也很低,但很多时候特定的应用程序可能需要模型更小、更快。
为了构建这些较小且计算成本较低的模型,本文引入了一个非常简单的参数 α α α,称为宽度乘数。宽度乘数 α α α的作用是在每一层均匀地薄化网络(降低每层的维度,在MobileNet V2中有具体解释)。
对于给定的层和宽度乘数α,输入通道的数量M变为αM,输出通道的数量N变为αN。
其中 α ∈ ( 0 , 1 ] α∈(0,1] α∈(0,1],一般选择0.75,0.5,0.25,α=1时就是base MobileNet;
计算代价变为:

α可以用在任何一个模型结构上,来定义一个带有合理准确性、延迟和尺寸的新的更小的模型。它用于定义一个新的简化的、需要重新训练的结构。
3.4 第二个参数ρ: Reduced Representation
降低CNN计算成本的第二个超参数是分辨率乘数ρ。
本文将此应用于输入图像,然后通过相同的乘数减少每个层的内部表示。
现在可以将网络核心层的计算成本表示为具有宽度乘数α和分辨率乘数ρ的深度可分离卷积:

其中 ρ ∈ ( 0 , 1 ] ρ∈(0,1] ρ∈(0,1],一般使得图像分辨率为224/192/160/128,ρ=1时就是base MobileNet;
表3显示了两个参数降低参数数量的效果:

4 实验
【实验4.1】
全卷积与深度可分离卷积效果对比;结果见表4;
正确率只下降1%左右,参数里大大减少;

【实验4.2,4.3】
α的影响:见表6;

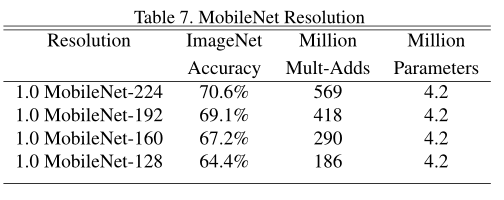
ρ的影响:见表7;
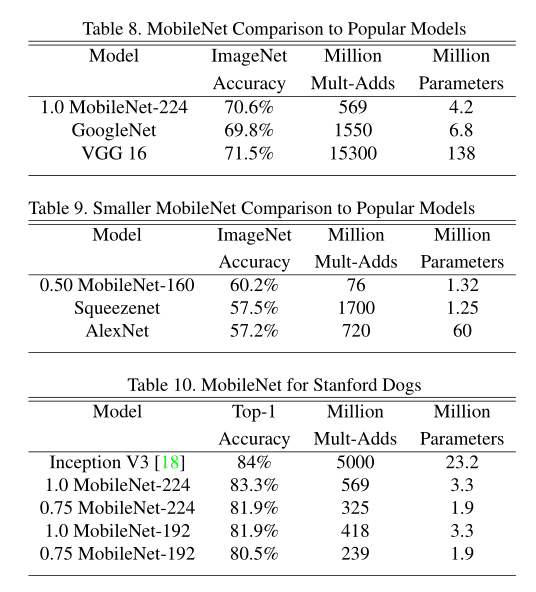
MobileNet与其他模型的比较结构:见表8,9,10;
表10:在Stanford Dogs 数据集上训练MobileNet进行细粒度识别;
【实验4.4】大规模地理定位任务;
【实验4.5】人脸属性任务(分类);
【实验4.6】目标检测任务;
【实验4.7】Face Embeddings任务(人脸识别);














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









