






论文名为《Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV)》,由Google的一些研究人员于2018年发表在ICML(International Conference on Machine Learning)上。
1.Introduction
理解现代机器学习(ML)模型(如神经网络)的行为仍然是一个重大挑战。然而,考虑到机器学习应用的广度和重要性,解决这一挑战很重要。除了确保准确的预测,并为科学家和工程师提供更好的设计、开发和调试模型的方法外,可解释性对于确保ML模型反映我们的价值观也很重要。
一种自然的可解释性方法是根据它考虑的输入特征来描述ML模型的预测。例如,在逻辑回归分类器中,系数权重通常被解释为每个特征的重要性。类似地,显著性映射基于一阶导数为像素赋予权重。
然而,一个关键的困难是,大多数ML模型操作的特征,如像素值,不对应于人类容易理解的高级概念。此外,模型的内部值(例如,神经激活)可能看起来难以理解。我们可以用数学的方式来表达这个困难,将ML模型的状态看作是一个向量空间Em,它由基向量Em张成,这些基向量Em对应于输入特征和神经激活等数据。人类在一个不同的向量空间Eh中工作,该空间由隐式向量Eh张成,对应于一组未知的人类可解释的概念。
从这个角度来看,对ML模型的“解释”可以看作是函数g: Em➡Eh。当g是线性时,我们称之为线性可解释性。本文提出的TCAV是一种新的线性可解释性方法。(TCAV:Testing with Concept Activation Vectors)
2.Related work
众多挑战之一是确保解释正确地反映了模型的复杂内部。解决这个问题的一种方法是使用生成的解释作为输入,并检查网络的输出以进行验证。这通常用于基于扰动/基于敏感性分析的可解释性方法,要么使用数据点(Koh & Liang, 2017),要么使用特征(Ribeiro等人,2016;Lundberg & Lee, 2017)作为扰动的一种形式,并检查网络的响应如何变化。它们通过构造维持局部一致性(即,对一个数据点及其相邻点的解释为真)或全局一致性(即,对一个类中的大多数数据点的解释为真)。TCAV是一种全局扰动方法,因为它将数据点扰动到与人类相关的概念以产生解释。
文章提到 “ saliency map(显著性图)通常识别相关区域并提供一种量化(即每个像素的重要性),但存在一些限制:1)由于saliency map仅基于一张图片(即局部解释),因此人类必须手动评估每张图片以得出类范围的结论;2)用户无法控制这些saliency map所选取的感兴趣的概念(缺乏定制)。例如,考虑两张不同猫图片的两张显著性图,其中一张图片的猫耳朵亮度更高。我们能评估耳朵在预测“猫”中的重要性吗? ”
这其实是变相讲TCAV解决的问题,TCAV是全局解释方法,并且可以训练得到定制的目标CAV,稍后提出了定量指标TCAV score用以衡量网络对概念的理解和表示程度。
3.Method
我们方法的第一步是定义兴趣的概念。我们只需选择一组代表这个概念的例子,或者找到一个独立的数据集,标记这个概念。这种策略的关键好处是,它没有将模型解释限制为只使用模型的预先存在的特征、标签或训练数据进行解释。CAV(Concept Activation Vectors),指的是决策边界线的正交向量。
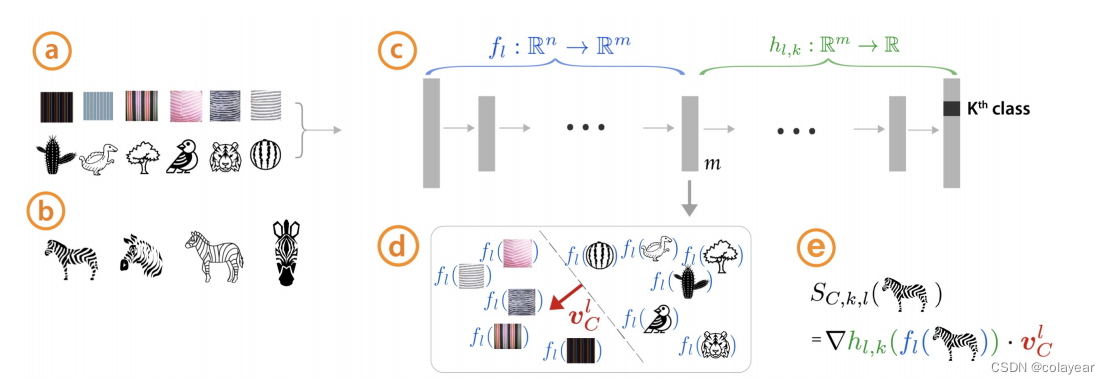
如图一所示,首先选择一组概念(比如条纹),然后在随机选择其他的图片(比如仙人掌、树、鸟、老虎、西瓜),用这些图片输进训练好的网络。b是已标记的训练数据示例(斑马)。网络中 fl : Rn➡Rm 代表从输入传播到网络的第m层,hl,k : Rm➡R 代表从第m层传播到输出。(其隐含意思是可以计算网络任何一层。)然后用a的图片传播到m层后,可以训练一个线性分类器,那么CAV就是这个线性分类器决策边界线的正交向量。最后输入斑马类的所有图片,得到的Sckl代表条纹概念在斑马类的敏感性。
Sckl公式:
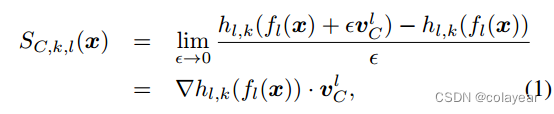
然后是TCAV公式:
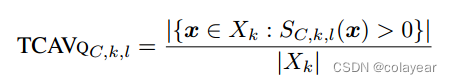
其中Xk表示所有的k类标签输入。TCAV Qckl表示k类中所有输入的Sckl>0的百分比,其值∈[0,1]。TCAVQ度量可以很容易地解释概念敏感性,对标签中的所有输入进行全局解释。
相对TCAV:
之前是概念C和其他随机图片进入模型训练,相对TCAV是概念C和概念D进入模型训练,训练得到的线性分类器只能判断输入x是对C还是D更靠近、更相关。
统计显著性检验:
TCAV技术的一个缺陷是有可能学习一个无意义的CAV。毕竟,使用随机选择的一组图像仍然会产生CAV。基于这种随机概念的测试不太可能有意义。
为了防止在针对特定CAV测试类时产生虚假结果,我们提出以下简单的统计显著性检验。我们不是针对单个随机样本N训练CAV一次,而是执行多次训练,通常是500次。一个有意义的概念应该导致TCAV分数在整个训练中表现一致。具体而言,我们基于这些多个样本对TCAV分数进行了双侧t检验。文中显示的所有结果都是通过测试的CAV。
4. Results
本节中做了许多实验。
4.1. Validating the learned CAVs
4.1.1. SORTING IMAGES WITH CAVS
我们可以计算一组感兴趣的图片与CAV之间的余弦相似度来对图片进行排序。

如图二所示,用一组条纹图片与CEO的CAV计算余弦相似度排序,发现最接近的是左上,很像领带的条纹;最不接近的是左下,很像衣服的条纹。用一组人物图片与Model Women的CAV计算余弦相似度排序,发现最接近的是右上,图中是系着领带的女性;最不接近的是左下,图中是系着领带的男性。这也表明CAV可以作为一个独立的相似性排序器,对图像进行排序,以揭示CAV从中学习的示例图像中的任何偏差。
4.1.2. EMPIRICAL DEEP DREAM

随后使用Empirical Deep Dream进行验证。Empirical Deep Dream的基本原理是通过最大化神经网络中特定层的激活模式来改变图像。在每次迭代中,算法将图像传入网络,然后通过计算梯度来找到使得特定层激活最大化的输入图像。通过反复迭代这个过程,图像逐渐被改变,并且在每一次迭代中特定的视觉特征被强化。使用这种技术,我们展示了CAV确实反映了它们感兴趣的潜在概念。
4.2. Insights and biases: TCAV for widely used image classifications networks
4.2.1. GAINING INSIGHTS USING TCAV
我们将TCAV应用于两种广泛使用的网络(Szegedy等,2015;2016)。我们尝试了各种类型的CAV,包括颜色、纹理、对象、性别和种族。请注意,这些概念都不在网络的类标签集合中;而是全部从(Bau等人,2017;Huang et al .,2007;Russakovsky等人,2015)或一个流行的图像搜索引擎。我们使用从所有层(对于GoogleNet)或一个子集(对于Inception V3)学习的CAV来展示TCAV结果。
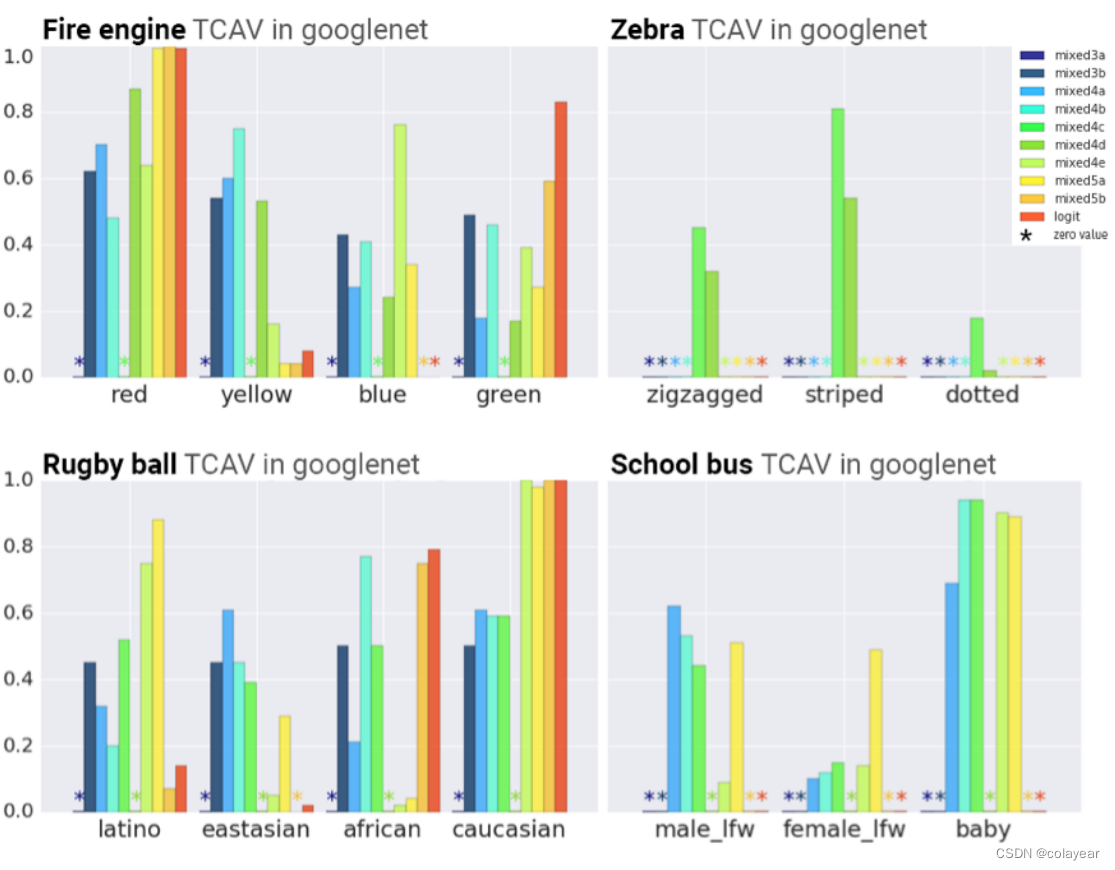
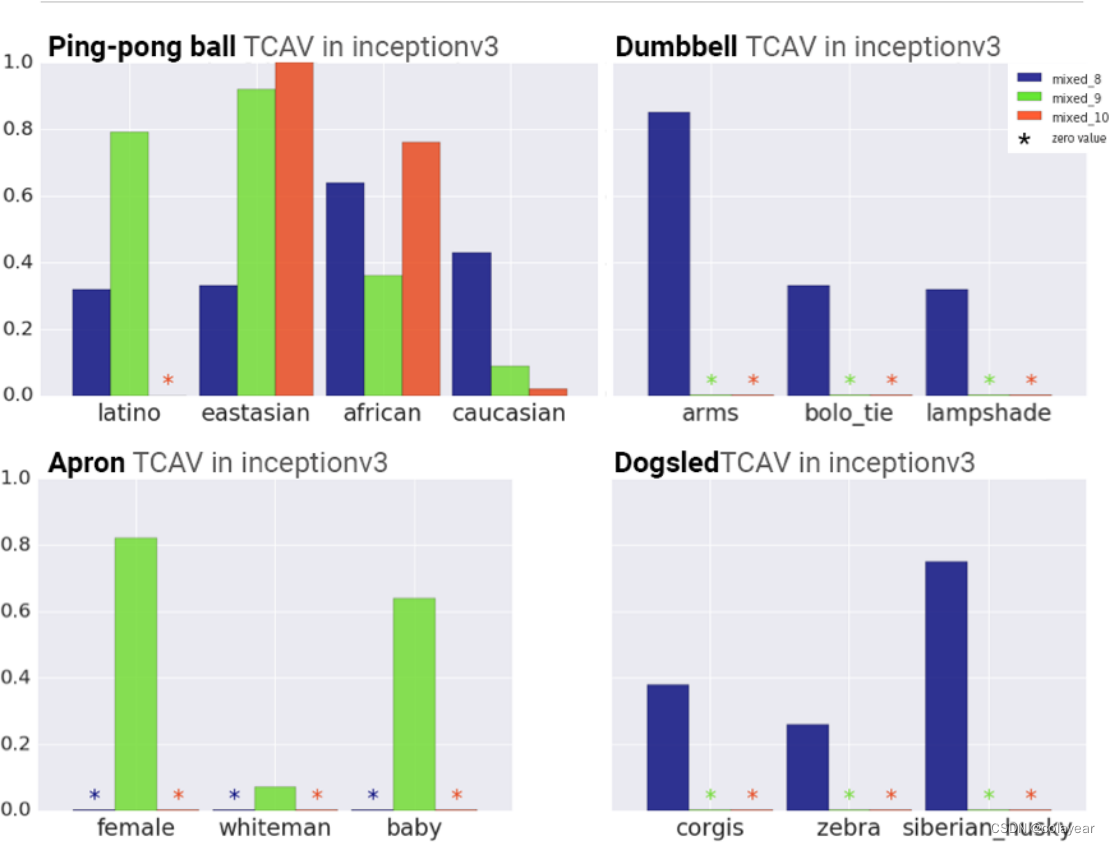
(图四表示计算了GoogleNet的十个层和Inceptionv3的三个层的TCAV。TCAV越接近1,表示全局敏感性更高。)
如图四所示,一些结果证实了我们的常识性直觉,例如红色概念对于消防车的重要性,条纹概念对于斑马的重要性,以及西伯利亚哈士奇概念对于狗拉雪橇的重要性。一些结果也证实了我们的怀疑,即这些网络对性别和种族很敏感,尽管没有被明确地训练过这些类别。例如,TCAV为(Stock & Cisse, 2017)的定性研究结果提供了定量证实,该研究发现乒乓球与特定种族高度相关。TCAV还发现,“女性”概念与“围裙”阶层高度相关。请注意,种族概念(乒乓球类)在接近最终预测层时显示出更强的信号,而纹理概念(例如条纹)在较早的层(斑马类)中影响TCAVQ。
4.2.2. TCAV FOR WHERE CONCEPTS ARE LEARNED
在学习CAV的过程中,我们训练一个线性分类器来分离每个概念,关注这些线性分类器的性能。
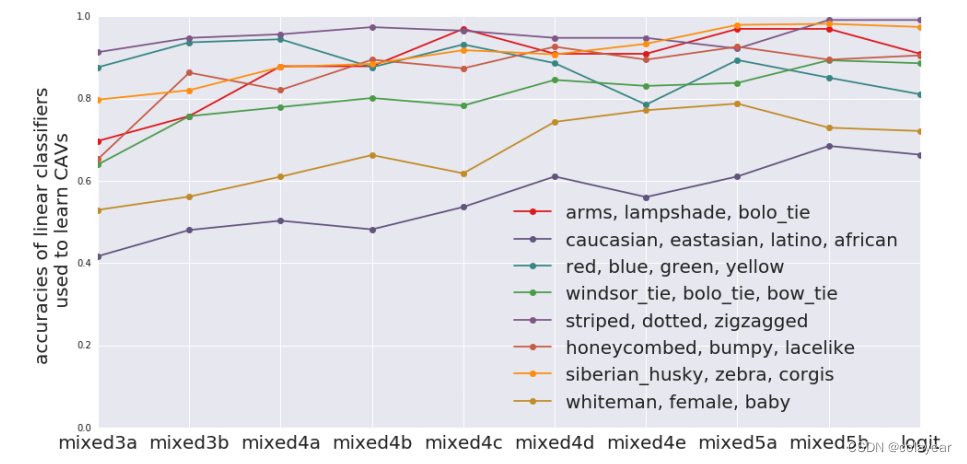
(横坐标是GoogleNet的十个层,纵坐标是每层CAV的准确率)
图五显示,在网络的更高层中,更抽象的概念(例如,对象)的准确性会提高。更简单的概念,如颜色,在整个网络中准确率很高。这证实了许多先前的发现(Zeiler & Fergus, 2014),即较低的层作为较低级别的特征检测器(例如,边缘),而较高的层使用较低级别特征的这些组合来推断较高级别的特征(例如,类)。准确度由训练集大小的1/3的测试集来测量。
4.3. A controlled experiment with ground truth
本实验的目的是证明TCAV可以成功地用于解释由神经网络在已知基础真理的精心控制设置中学习的函数。我们展示了TCAV的定量结果,并将这些结果与我们对显著性图的评估进行了比较。

为此,我们创建了一个包含三个任意类别(斑马、出租车和黄瓜)的数据集,并在图像中写入可能带有噪声的标题(示例如图六所示)。噪音参数p∈[0,1]控制图像标题与图像类一致的概率。如果没有噪声(p = 0),标题总是与图像标签一致,例如,一辆出租车的图片总是在底部包含单词“cab”。在p =0.3时,每张图片都有30%的几率将正确的标题替换为随机单词(例如“兔子”)。
然后,我们训练4个网络,每个网络在一个数据集上使用不同的噪声参数p∈[0;1]。在分类任务中,每个网络都可以学习关注图像或标题(或两者都关注)。为了获得每个网络关注的概念的近似基础真理,我们可以测试网络在没有标题的图像上的性能。如果网络使用图像概念进行分类,性能应该仍然很高。否则,网络性能将受到影响。我们使用每个类的图像创建图像CAV,并使用图像中随机打乱其他像素的标题CAV。
4.3.1. QUANTITATIVE EVALUATION OF TCAV
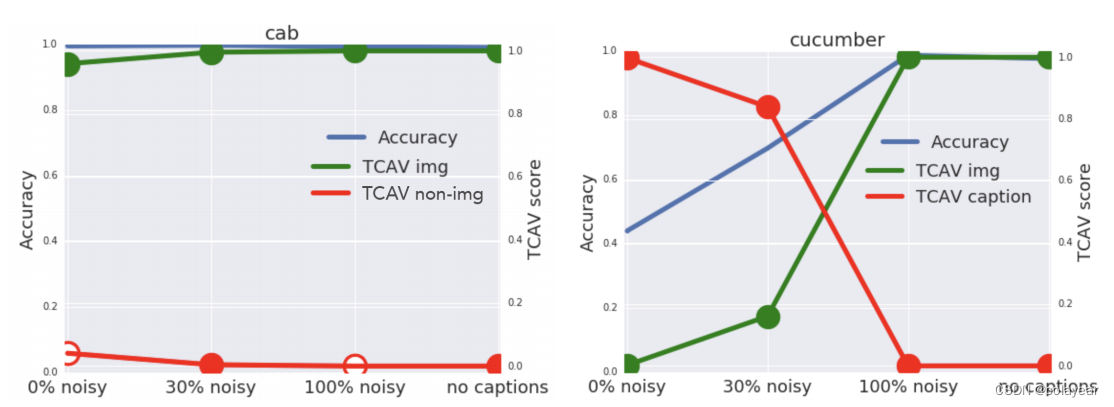
总体而言,我们发现TCAV分数紧密反映了网络所关注的概念(图七)。准确率结果表明,在对出租车进行分类时,无论噪声参数如何,网络更多地使用图像概念而不是标题概念。然而,在对黄瓜进行分类时,网络有时会关注标题概念,有时会关注图像概念。图七显示TCAVQ与这个基本事实非常吻合。在驾驶室类别中,图像概念的TCAVQ很高,与它在无字幕图像上的高测试性能一致。在黄瓜类中,图像概念的TCAVQ随着噪声水平的增加而增加,这与精度也随着噪声的增加而增加的观察结果一致。(在黄瓜类中,随着噪音加大,标题变得越来越不可信,于是模型更加关注图像,此时图像TCAV score提高,标题TCAV score降低,准确率提高)
4.3.2. EVALUATION OF SALIENCY MAPS WITH HUMAN SUBJECTS
然后对比一下Saliency maps方法:(论文前已经提到Saliency maps有缺点,但作者一个人说主观意见没说服力,那就直接来一个多人的问卷调查)
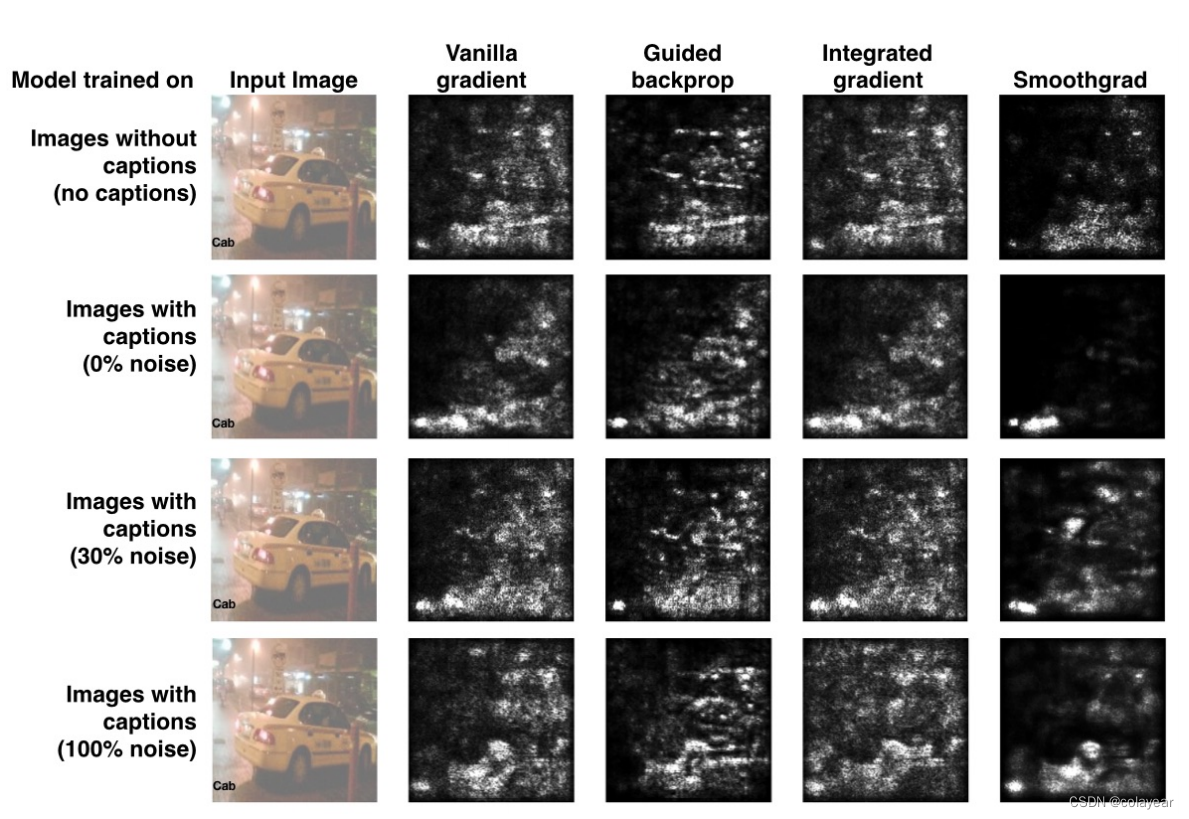
图八,具有近似真值的Saliency map结果:给出了在具有不同噪声参数p(行)和不同Saliency map方法(列)的数据集上训练的模型。近似的基本事实是,在所有情况下,网络对图像的关注都远远超过对标题的关注,这一点从Saliency map上看不出来。
在本节中,我们通过一个人类受试者实验来定量地评估Saliency map能够与人类交流的信息。我们利用前一节生成的Saliency map,在亚马逊土耳其机器人上进行了一个50人的人体实验。为简单起见,我们评估了四种噪音水平中的两种(0%和100%噪音),以及两种Saliency map((Sundararajan et al ., 2017)和(Smilkov et al ., 2017))。每个worker执行一系列6个任务(3个对象类×2个Saliency map类),全部用于单个模型。任务顺序是随机的。在每个任务中,工作人员首先看到四幅图像以及相应的显著性掩模。然后,他们对图像对模型的重要程度(10分制)、标题对模型的重要程度(10分制)以及他们对答案的信心程度(5分制)进行评分。总共,土耳其人对60张独特的图片(120张独特的Saliency map)进行了评分。
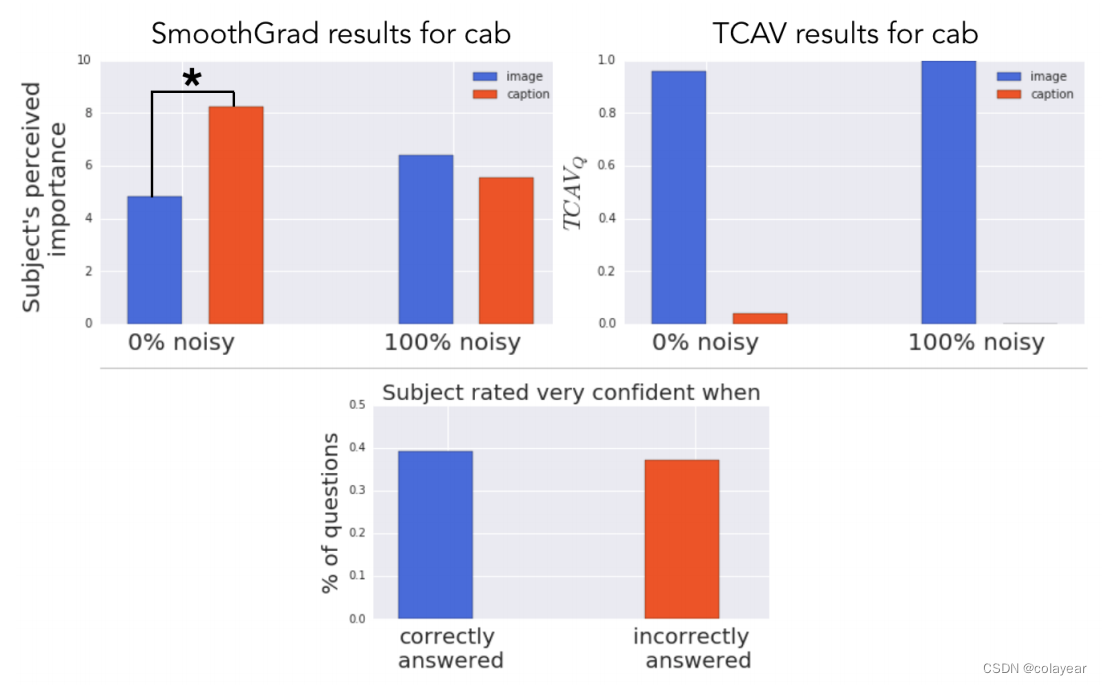
(上图左:认为图片还是标题更重要,上图右:实际上的TCAV值。意思是,从TCAV看,模型明明高度关注图像,但人们看了显著性图后,大多认为0噪音下模型关注标题更多。下图:当人们表示他们对答案非常有信心时,所回答的正确率和错误率)
总的来说,显著性图正确传达哪个概念更重要的概率只有52%(两个选项的随机概率是50%)。Wilcox签名秩检验表明,在超过一半的情况下,要么在感知到的两个概念的重要性上没有显著差异,要么错误的概念被认为更重要。图九(顶部)显示了一个显著性图传达错误概念重要性的例子。尽管如此,被评为非常自信的正确答案的百分比与不正确答案的百分比相似(图九底部),这表明单独使用显著性图进行解释可能会产生误导。此外,当一种显著性图方法正确地传达了更重要的概念时,另一种显著性图方法往往没有,反之亦然。
4.4. TCAV for a medical application
我们现在将TCAV应用于从视网膜眼底图像预测糖尿病视网膜病变(DR)的现实问题(DR是一种可治疗但威胁视力的疾病)(Krause et al, 2017)。
我们就结果咨询了医学专家。兴趣模型使用基于复杂标准的5点评分量表预测DR水平,从0级(无DR)到4级(增殖)。医生对DR水平的诊断依赖于对一组诊断概念的评价,如微动脉瘤(micro -动脉瘤,MA)或泛视网膜激光疤痕(pan-retinal laser scars, PRP),不同DR水平的诊断概念更加突出。我们试图使用TCAV来测试这些概念对模型的重要性。
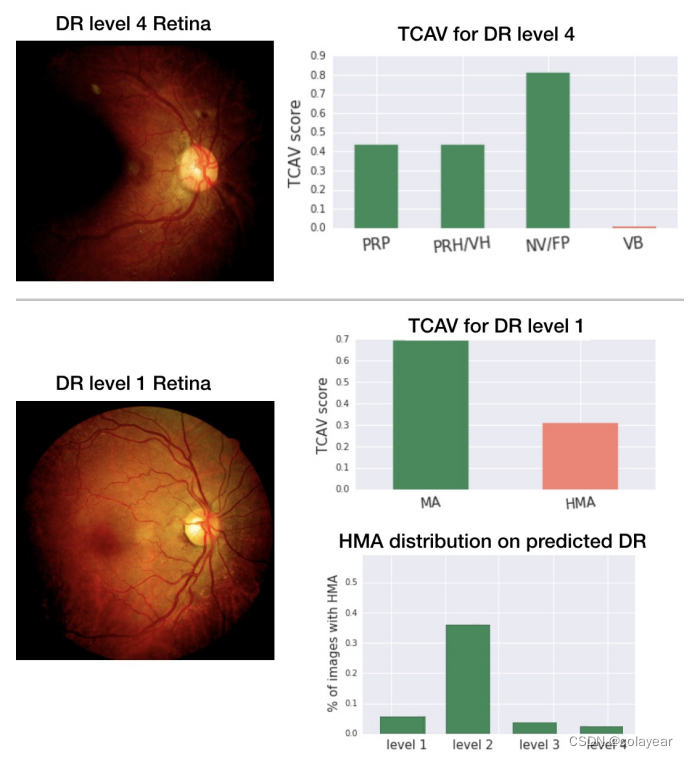
(图十,上图:DR4级图像和TCAV结果。TCAVQ高表示与该级别相关的特征(绿色),低表示不相关的概念(红色)。中图:DR1级(轻度)TCAV结果。该模型经常错误地将DR1级预测为DR2级,使用TCAV可以使这个模型错误更易于解释:除了与DR2级相关的概念(红色,HMA)之外,通常与DR1级相关的概念(绿色,MA)的TCAVQ也很高。下图:HMA特性在DR2级中出现的频率高于DR1级。)
对于某些DR级别,TCAV认为正确的诊断概念很重要。如图十所示,与DR级别4相关的概念的TCAV得分较高,而非诊断性概念的TCAV得分较低。
对于1级DR, TCAV结果有时与医生的启发式不同(图十底部)。例如,动脉瘤(HMA)具有相对较高的TCAV评分,尽管它们被诊断为更高的DR级别(见图十中的HMA分布)。然而,与这一发现一致的是,该模型经常将第1级(轻度)的预测过度为第2级(中度)。
鉴于此,医生说她想告诉模型不要强调HMA对1级的重要性。因此,当专家不同意模型预测时,TCAV可能有助于他们解释和修正模型错误。
5. Conclusion and Future Work
这里提出的TCAV方法是朝着创建对人类友好的深度学习模型内部状态的线性解释迈出的一步,这样关于模型决策的问题就可以用自然的高级概念来回答。至关重要的是,这些概念不需要在训练时知道,并且可以在事后分析中通过一组示例轻松指定。
我们的实验表明,TCAV可能是分析师工具箱中有用的技术。我们提供了证据,证明CAV确实符合其预期的概念。然后,我们展示了如何使用它们来洞察各种分类模型所做的预测,从标准图像分类网络到专门的医疗应用。
基于概念归因方法,未来的工作有几个有希望的途径。当我们专注于图像分类系统时,将TCAV应用于其他类型的数据(音频,视频,序列等)可能会产生新的见解。除了可解释性之外,TCAV也可能有其他应用:例如,在识别神经网络的对抗性示例(见附录)。最后,人们可以要求自动识别概念的方法,对于一个表现出超人表现的网络,概念归因可以帮助人类提高自己的能力。
ps:小白理解,如有错误,欢迎指正

















 2767
2767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









