







YOLO系列
摘要
1. 将目标检测视为一个回归问题
YOLO 将目标检测视为一个空间上分离的边界框(bounding boxes)和与之关联的类别概率回归问题,而非之前 two stage 算法的分类问题。单个神经网络在一次评估中直接从整张图像中预测边界框和类别概率。所以可以直接优化端到端的检测性能。
2. 定位准确率不如 SOTA,但背景错误率更低
YOLO makes more localization errors. but is less likely to predict false positives on background
如何理解 less likely to predict false positives on background?
首先在YOLOv1目标检测模型中,训练时,首先根据训练集图像中物体真实边界框的坐标计算每个物体的中心坐标,中心坐标所落在的 grid cells(网格) 被认为是训练过程中的正样本(positives)候选区域,也就是前景。正样本以外的网格就是负样本,也就是背景(background),predict false positives on background 就是说模型在预测时,更少地将背景预测为存在目标的区域,误把背景当作前景的概率更低。
3. 泛化能力强
YOLO学习物体的非常一般的特征表示。当从自然图像推广到其他领域(如艺术品)时,其优于其他检测方法。
1.引言
1.1 YOLO 速度很快
We reframe object detection as a single regression problem, straight from image pixels to bounding box coordinates and class probabilities.
A single convolutional network simultaneously predicts multiple bounding boxes and class probabilities for those boxes.
单个神经网络同时预测整张图像中的多个边界框和对应的类别概率。
与之前的 two stage 算法形成鲜明对比,two stage 算法通常有多个神经网络分别负责不同的功能(比如专门生成候选区域/感兴趣区域的神经网络,对感兴趣区域进行预测的神经网络),并且一些 two stage 算法例如 RNN 并非同时,而是逐个将 RoI \text{RoI} RoI 区域送往分类器中进行预测,并且 RNN 也并非在整张图像上预测,而是在 RoI \text{RoI} RoI 区域上进行预测。
YOLO trains on full images and directly optimizes detection performance.
YOLO 在整张图像上进行训练,可以直接优化检测性能。

1.2 全局推理
Second, YOLO reasons globally about the image when making predictions.
Unlike sliding window and region proposal-based techniques, YOLO sees the entire image during training and test time so it implicitly encodes contextual information about classes as well as their appearance.
不像滑动窗口和基于候选区域的方法,YOLO 在训练和测试时都是能够看到整张图像的,这意味着,YOLO 不是只在图像的一个局部窗口中检测对象。这样做可以帮助模型更好地理解图像中对象的全局布局和相互关系。
隐式编码上下文信息:由于YOLO一次性看到整个图像,它能够隐式地学习和编码有关对象类别的上下文信息。例如,它可以学习到某些对象类别通常出现在某些特定的环境中(比如汽车通常在道路上),而这些上下文信息对于识别这些对象是非常有帮助的。
类别及其外观的编码:YOLO不仅仅学习对象的上下文信息,它还学习对象的外观。通过观察整个图像,YOLO可以更全面地理解不同对象的视觉特征和它们如何在不同的环境中表现,从而在后续的检测任务中更准确地识别这些对象。
Fast R-CNN, a top detection method, mistakes background patches in an image for objects because it can’t see the larger context. YOLO makes less than half the number of background errors compared to Fast R-CNN.
Fast R-CNN 由于看不到更大的上下文信息所以背景错误率较高。YOLO 的背景错误率大大降低。
YOLOv1 still lags behind state-of-the-art detection systems in accuracy.
虽然YOLOv1可以快速识别图像中的物体,但很难精确定位某些物体,尤其是小物体。
2. Unified Detection
Our network uses features from the entire image to predict each bounding box. It also predicts all bounding boxes across all classes for an image simultaneously.
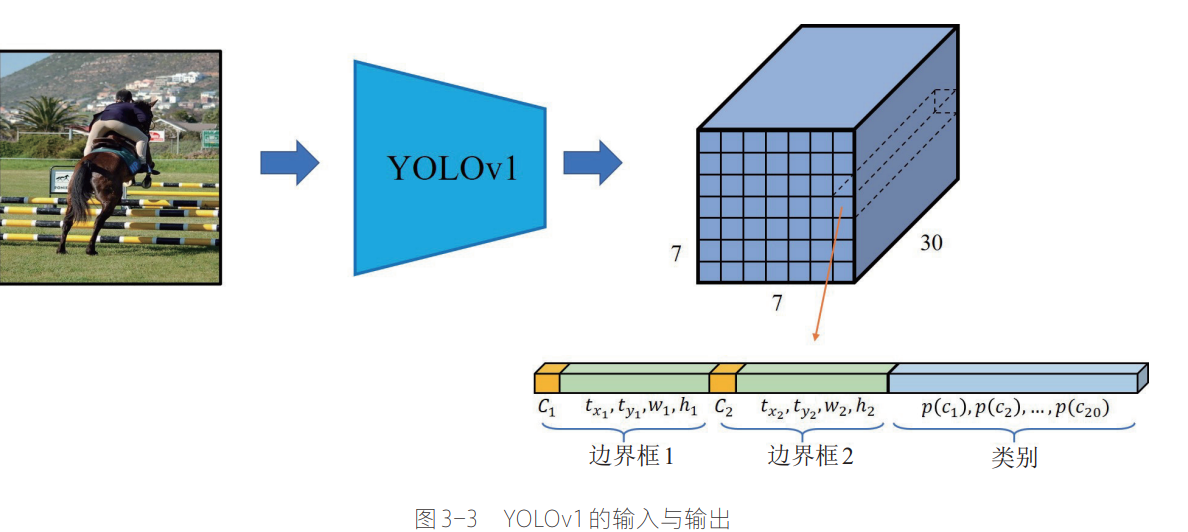
Our system divides the input image into an S × S S × S S×S grid. If the center of an object falls into a grid cell, that grid cell is responsible for detecting that object.
系统将输入图像划分成 S × S S × S S×S 网格(grid cells),某个物体的中心坐标落在某个网格时,该网格负责检测该物体。
例如,下图中,黄色这个 grid cell 负责检测这只狗。这里
S
=
7
S = 7
S=7,也就是输出的特征图的空间尺寸是
7
×
7
7×7
7×7

这张图中最终输出的特征图
7
×
7
×
30
7×7×30
7×7×30,其中特征图上的每个位置对应于上面那张图中的每个网格(grid cell),而通道维度
30
30
30 代表模型对于这个位置的预测输出(参数),
30
30
30 是这么来的,如下图 :
30
=
5
B
+
C
30 = 5B+C
30=5B+C其中,
B
B
B 是每个网格预测的边界框数量,YOLOv1中
B
=
2
B = 2
B=2 ,而
C
C
C 是每个训练集中物体类别总数,YOLOv1 所用的 PASCAL VOC 数据集总共有
20
20
20 种类别。
问题:那么不包含物体中心的那些网格,是否会预测边界框和对应的类别呢?
不包含物体中心的那些网格也就是负样本候选区域,在训练和推理时也是会预测边界框和对应的类别的,在训练时,YOLO为每个边界框设定了一个对象置信度 Pr(objectness) \text{Pr(objectness)} Pr(objectness),包含物体中心的那些网格,也就是正样本候选区域 Pr(objectness) = 1 \text{Pr(objectness)} = 1 Pr(objectness)=1, 而负样本候选区域 Pr(objectness) = 0 \text{Pr(objectness)} = 0 Pr(objectness)=0
这意味着,在训练过程中,只有这些正样本候选区域 Pr(objectness) = 1 \text{Pr(objectness)} = 1 Pr(objectness)=1 会被训练学习边界框回归和类别预测(意味着其预测结果会被用于更新模型参数)。其他网格的预测结果不会被用于更新模型参数。
其实这种思想类似于注意力机制,让模型把注意力更多地放在正样本候选区域,也就是实际包含物体的区域(前景)。也有点类似 two stage 算法,例如 Faster R-CNN 通过 RPN 首先生成 ROI \text{ROI} ROI 候选区域,然后对 ROI \text{ROI} ROI 候选区域池化之后固定大小,被送往分类器。
顺便说一下, Faster R-CNN 中 anchor boxes(先验框) 的主要作用是生成 proposals 候选区域。
Each grid cell predicts B B B bounding boxes and confidence scores for those boxes. These confidence scores reflect how confident the model is that the box contains an object and also how accurate it thinks the box is that it predicts. Formally we define confidence as Pr(Object) ∗ IOU p r e d t r u t h \text{Pr(Object)} ∗ \text{IOU}^{truth}_{pred} Pr(Object)∗IOUpredtruth . If no object exists in that cell, the confidence scores should be zero. Otherwise we want the confidence score to equal the intersection over union ( IOU \text{IOU} IOU) between the predicted box and the ground truth.
训练时,每个网格预测 B B B 个边界框和每个边界框对应的 置信度分数(confidence scores)。
将置信度分数(confidence scores)定义为: Pr(Object) ∗ IOU p r e d t r u t h \text{Pr(Object)} ∗ \text{IOU}^{truth}_{pred} Pr(Object)∗IOUpredtruth
置信度分数反应了:
- 模型对于预测的边界框内存在物体的信心(概率值) , 也就是 Pr(Object) \text{Pr(Object)} Pr(Object)
- 模型认为所预测的边界框有多么精确,也就是 IOU p r e d t r u t h \text{IOU}^{truth}_{pred} IOUpredtruth
注意,只有训练过程可以计算出 IOU p r e d t r u t h \text{IOU}^{truth}_{pred} IOUpredtruth,因为训练数据集是有真实边界框标注信息的,所以可以知道 Ground Truth \text{Ground Truth} Ground Truth 的区域和面积
而到了推理(测试)阶段,没有 Ground Truth \text{Ground Truth} Ground Truth 信息,这个置信度分数不再是根据上面的公式计算出来的,而是模型根据训练过程所学到的知识,会根据经验给出一个置信度分数。
Each bounding box consists of 5 predictions: x , y , w , h x, y, w, h x,y,w,h, and confidence. The ( x , y ) (x, y) (x,y) coordinates represent the center of the box relative to the bounds of the grid cell. The width and height are predicted relative to the whole image. Finally the confidence prediction represents the IOU \text{IOU} IOU between the predicted box and any ground truth box.
每个边界框由 5 个预测值组成: x , y , w , h x, y, w, h x,y,w,h 和 confidence, ( x , y ) (x, y) (x,y) 坐标表示相对于网格(grid cell)边界的边界框中心, w , h w,h w,h 宽度和高度 相对于整张图像 进行预测。所预测的 confidence 代表预测的边界框和真实边界框的 IOU \text{IOU} IOU 交并比。
Each grid cell also predicts C C C conditional class probabilities, Pr ( Class i ∣ Object ) \text{Pr}(\text{Class}_i |\text{Object}) Pr(Classi∣Object). These probabilities are conditioned on the grid cell containing an object.
每个网格还预测 C C C 个条件类别概率 Pr ( Class i ∣ Object ) \text{Pr}(\text{Class}_i |\text{Object}) Pr(Classi∣Object),只有网格中包含物体时,才会给出这些条件类别概率。如果网格的对象置信度(即格子内包含对象的概率)较高,这些条件类别概率将被用来判断对象可能属于哪个类别。
也就是说,在训练过程时,只有正样本候选区域会预测条件类别概率,测试时,对象置信度分数较高的网格才会应用条件类别概率。具体来说,这些条件概率与对象置信度相乘,结果是针对每个类别的最终置信度
We only predict one set of class probabilities per grid cell, regardless of the number of boxes B B B.
尽管每个网格通常会预测多个边界框,但YOLO为每个网格只预测一组类别概率。这意味着无论一个网格预测多少个边界框( B B B),该网格对于是否包含某一类别的对象的预测(即类别概率)只有一套。
At test time we multiply the conditional class probabilities and the individual box confidence predictions, Pr ( Class i ∣ Object ) × Pr ( Object ) × IOU pred truth = Pr ( Class i ) × IOU pred truth ( 1 ) \text{Pr}(\text{Class}_i | \text{Object}) \times \text{Pr}(\text{Object}) \times \text{IOU}^\text{truth}_\text{pred} = \text{Pr}(\text{Class}_i) \times \text{IOU}^\text{truth}_\text{pred} \quad (1) Pr(Classi∣Object)×Pr(Object)×IOUpredtruth=Pr(Classi)×IOUpredtruth(1)
which gives us class-specific confidence scores for each box. These scores encode both the probability of that class appearing in the box and how well the predicted box fits the object.
意思是,
测试时,将条件类别概率
Pr
(
Class
i
∣
Object
)
\text{Pr}(\text{Class}_i |\text{Object})
Pr(Classi∣Object) 和
边界框置信度分数 (confidence scores) Pr(Object) ∗ IOU p r e d t r u t h \text{Pr(Object)} ∗ \text{IOU}^{truth}_{pred} Pr(Object)∗IOUpredtruth 相乘,
得到每个边界框的 特定类别置信度分数 class-specific confidence scores,也就是 Pr ( Class i ) × IOU pred truth \text{Pr}(\text{Class}_i) \times \text{IOU}^\text{truth}_\text{pred} Pr(Classi)×IOUpredtruth
These scores encode both the probability of that class appearing in the box and how well the predicted box fits the object.
这些特定类别置信度分数既编码了该类别出现在预测边界框中的概率,也编码了这些预测的边界框对于适应真实目标预测得有多好(也就是和真实边界框多么接近)。
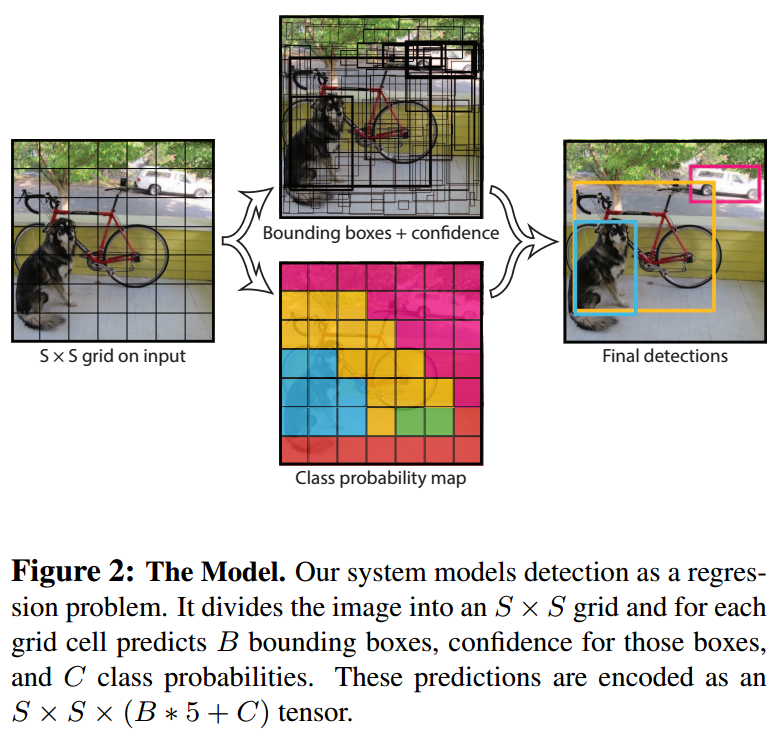
For evaluating YOLO on PASCAL VOC, we use S = 7 , B = 2 S = 7, B = 2 S=7,B=2. PASCAL VOC has 20 20 20 labelled classes so C = 20 C = 20 C=20.
Our final prediction is a 7 × 7 × 30 7 × 7 × 30 7×7×30 tensor.
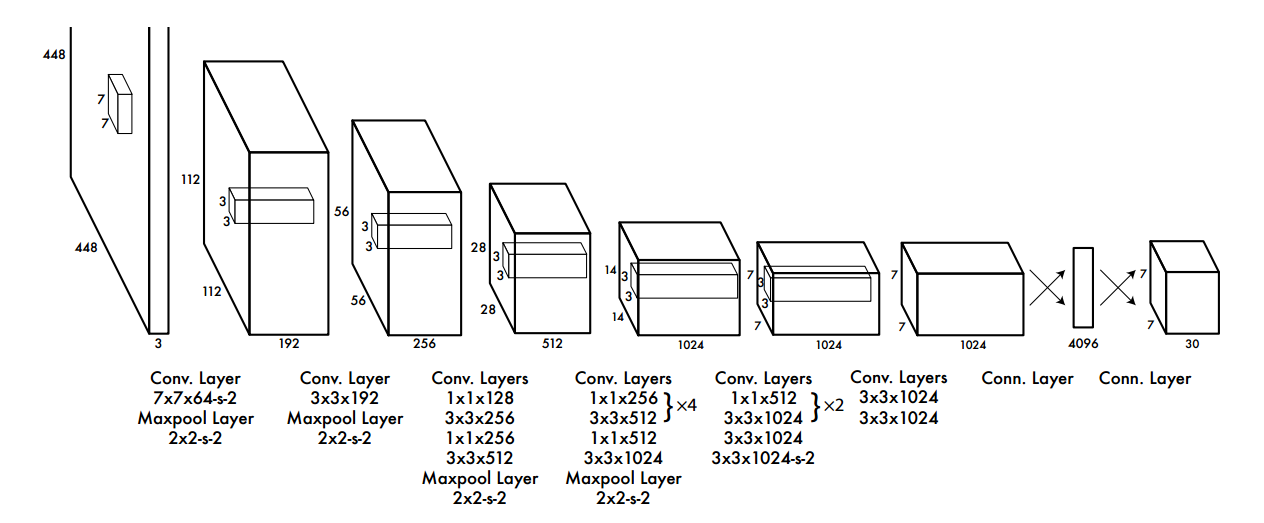
2.1 网络设计
The initial convolutional layers of the network extract features from the image while the fully connected layers predict the output probabilities and coordinates.
卷积层提取图像特征,全连接层预测输出概率和坐标。
Our network architecture is inspired by the GoogLeNet model for image classification. Our network has 24 convolutional layers followed by 2 fully connected layers.
YOLOv1 网络有 24 个卷积层和 2 个全连接层。

We pretrain the convolutional layers on the ImageNet classification task at half the resolution (224 × 224 input image) and then double the resolution for detection.
作者在 ImageNet 分类任务上以 224 × 224 224 × 224 224×224 分辨率的图像对卷积层进行了预训练,然后以 448 × 448 448 × 448 448×448 分辨率的图像进行目标检测。
2.2 训练
-
预训练阶段:作者提到他们使用ImageNet 1000类竞赛数据集对卷积层进行预训练。预训练是深度学习中常见的做法,目的是在进行特定任务之前,在一个大规模数据集上训练模型,从而学会提取有效特征。在这里,他们使用的是从另一幅图(图3)中看到的前20个卷积层,然后是平均池化层和一个全连接层。
-
模型转换和微调:作者随后将预训练的模型转换为检测模型。他们参考了Ren等人的工作,增加了额外的卷积层和全连接层,以改善性能。新添加的层使用随机初始化的权重。此外,由于检测任务通常需要更精细的视觉信息,他们提高了网络的输入分辨率,从224x224增加到448x448。
-
最终层的设计:最终输出层预测类别概率和边界框坐标。边界框的宽度和高度通过图像宽度和高度进行归一化,使值落在0到1之间。边界框的中心坐标x和y被参数化为相对于所在grid cell网格位置的偏移量,也是在0到1的范围内。
-
激活函数:最终层使用线性激活函数,而所有其他层使用泄露的修正线性激活函数(Leaky ReLU)。这种激活函数相比于传统的ReLU激活函数在x<0时仍然允许一小部分梯度流过,这有助于缓解神经元“死亡”的问题。
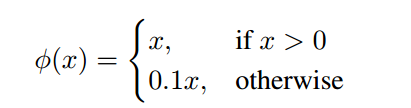
YOLOv1模型损失函数的选择和其潜在的问题
作者提到模型输出的优化是基于平方和误差(sum-squared error)。平方和误差是机器学习中常用的损失函数,然而,这个选择并不是没有缺点的:
-
平方和误差不完全符合模型设计的初衷,即最大化平均精度(average precision)。平均精度是评估目标检测模型性能的常用指标,它考虑了模型检测到的所有正类别实例的排序质量。
-
在损失函数中,平方和误差将定位错误(localization error)和分类错误(classification error)给予了相同的权重。这可能并不理想,因为在某些情况下,我们可能更希望模型更精确地定位物体,而不是仅仅准确分类。举例来说,对于一个检测行人的模型,准确的定位比区分行人的具体类型更为重要。
-
另外,由于在大多数图像中,许多网格单元并不包含任何目标对象,这会导致这些单元的“置信度”分数趋向于零。这种情况往往会压倒那些确实包含目标的网格单元的梯度。换句话说,在学习过程中,模型更倾向于预测没有对象,因为这种情况在数据集中更为常见。
-
这种置信度分数的失衡可能导致模型的不稳定性,尤其是在训练的早期阶段,这可能会导致训练过程早期就发散,即模型的损失变得非常大,无法收敛到一个好的解。
YOLOv1模型如何改进其损失函数来更好地反映检测任务的实际需求。
-
调整损失权重:为了解决之前提到的问题,即平方和误差可能导致没有包含对象的单元过度惩罚损失函数的问题,作者调整了损失函数中各部分的权重。他们增加了对边界框坐标预测误差的权重( λ c o o r d \lambda_{coord} λcoord),并减少了对不包含对象的边界框置信度预测的权重( λ n o o b j \lambda_{noobj} λnoobj)。在这个上下文中, λ c o o r d \lambda_{coord} λcoord被设置为5,而 λ n o o b j \lambda_{noobj} λnoobj被设置为0.5。这样的设置加大了模型对边界框位置精度的关注,并减少了对空网格单元的关注,因为空网格单元的数量远多于包含对象的单元(前景区域)。
-
平方根转换:平方和误差对大框和小框中的误差赋予相同的权重,这可能不理想,因为在大框中的小偏差对整体性能的影响要小于在小框中的同等偏差。为了缓解这个问题,YOLO预测边界框宽度和高度的平方根而不是直接预测宽度和高度。这意味着模型对小框中的偏差更加敏感,而对大框中的偏差不那么敏感。
-
边界框预测器的负责制:YOLO在每个网格单元中预测多个边界框,但在训练时,他们希望每个对象只由一个边界框预测器来负责预测。因此,它们为每个对象分配一个“负责”预测的边界框预测器,基于当前与真实边界框的交并比(IOU)最高的预测器。这导致每个预测器在预测特定大小、纵横比或对象类别上逐渐变得更加擅长,从而提高了模型的整体召回率。
这里第三点所述的"负责"是体现在模型训练过程中的损失函数中的。例如下面的损失函数中的指示函数 1 i j o b j \mathbb{1}^{obj}_{ij} 1ijobj,如果网格 i i i 的第 j j j 个边界框预测器的预测边界框与实际边界框有最高的IOU,那么它就被认为是“负责”这个预测的, 1 i j o b j \mathbb{1}^{obj}_{ij} 1ijobj就会被设置为 1 1 1,意味着误差值会被计入损失函数中,否则就是 0 0 0,不计入损失函数也就对模型参数更新无影响。
通过这些改进,YOLOv1在其模型设计中更好地平衡了定位精度与分类准确性,并且增强了模型对不同类型对象的检测能力。这些调整直接影响到模型在目标检测任务中的表现,尤其是在准确性和召回率方面。
损失函数:
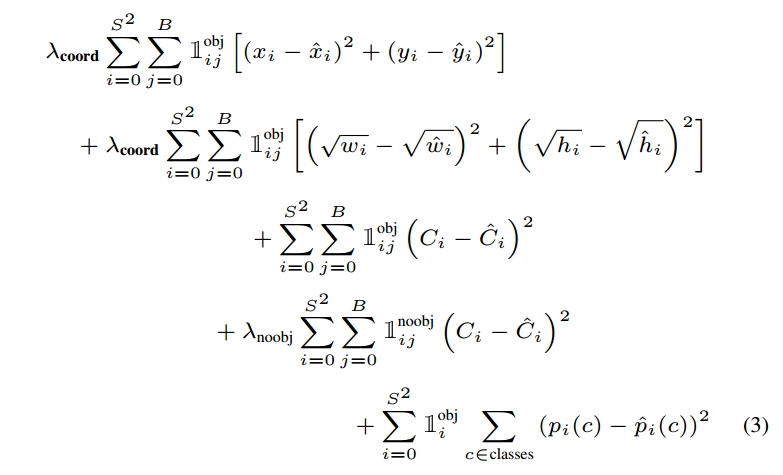
where 1 i o b j \mathbb{1}^{obj}_{i} 1iobj denotes if object appears in cell i i i and 1 i j o b j \mathbb{1}^{obj}_{ij} 1ijobjdenotes that the j j jth bounding box predictor in cell i i i is “responsible” for that prediction.
Note that the loss function only penalizes classification error if an object is present in that grid cell (hence the conditional class probability discussed earlier). It also only penalizes bounding box coordinate error if that predictor is “responsible” for the ground truth box (i.e. has the highest IOU of any predictor in that grid cell).
1 i o b j \mathbb{1}^{obj}_{i} 1iobj 和 1 i j o b j \mathbb{1}^{obj}_{ij} 1ijobj 是指示函数,对于所有的网格:
-
1 i o b j \mathbb{1}^{obj}_{i} 1iobj 表示如果对象出现在网格单元 i i i 中,这个变量就是 1 1 1,否则就是 0 0 0 。这意味着如果单元 i i i 中有一个对象,那么这个条件将触发,并在损失函数中激活与类别预测相关的项。
-
1 i j o b j \mathbb{1}^{obj}_{ij} 1ijobj 表示在网格单元 i i i 中,第 j j j 个边界框预测器是否负责预测该对象。"负责"是基于预测器的预测边界框和实际边界框(ground truth box)之间的交并比(IOU)来确定的。IOU是两个边界框重叠区域与它们联合区域的比值。如果第 j j j 个预测器的预测边界框与实际边界框有最高的IOU,那么它就被认为是“负责”这个预测的, 1 i j o b j \mathbb{1}^{obj}_{ij} 1ijobj就是 1 1 1,否则就是 0 0 0。
-
1 i n o o b j \mathbb{1}^{noobj}_{i} 1inoobj 表示如果网格单元 i i i 中没有对象存在,这个变量就是 1 1 1,否则就是 0 0 0
-
1 i j n o o b j \mathbb{1}^{noobj}_{ij} 1ijnoobj 是一个指示函数,用于指示在网格单元 i i i 中第 j j j 个预测的边界框是否没有对象(即“no object”)。具体来说:
当网格单元 i i i 中的第 j j j 个边界框没有包含对象时, 1 i j n o o b j = 1 \mathbb{1}^{noobj}_{ij} = 1 1ijnoobj=1。
如果该边界框包含一个对象,那么 1 i j n o o b j = 0 \mathbb{1}^{noobj}_{ij} = 0 1ijnoobj=0。
该指示函数用于确保模型只对那些不应该有对象检测的边界框预测的置信度进行惩罚。因为大部分边界框是空的(不包含对象),所以此项有助于平衡损失函数,防止由于存在大量空边界框而导致模型对有对象的边界框预测的置信度不足。换句话说,它减少了模型因预测出很多错误的“有对象”的边界框(背景被预测为前景)而受到的惩罚。
λ n o o b j \lambda_{noobj} λnoobj 是用来平衡没有对象的边界框预测对总损失的贡献的权重因子。由于没有对象的边界框在数据集中很常见,这个权重通常设置得较低,以减少它们对损失函数的影响,允许模型更多地关注那些包含对象的边界框的预测。
这样的设计意味着损失函数在计算时具有以下特性:
-
分类误差:仅当网格单元 i i i 确实包含对象时,才会惩罚该单元的分类误差。也就是说,如果没有对象,即使分类器预测了某个类别,这个预测不会对损失函数有贡献。
-
边界框坐标误差:只有当一个预测器被认为是对一个实际边界框“负责”时,才惩罚其边界框坐标的预测误差。这意味着仅当预测边界框与实际边界框有最高IOU时,预测器的位置误差才会影响损失函数。
这种设计的目的是减少模型预测中的冗余并提高效率,同时确保模型专注于准确预测具有最高IOU的那些边界框,因为它们最有可能是正确的检测。
YOLOv1的损失函数由几个部分组成,主要是为了同时优化边界框的位置,尺寸,以及分类的准确性:
-
边界框位置(中心坐标)的平方误差:用于比较预测的边界框位置( x i , y i x_i, y_i xi,yi)与真实值( x ^ i , y ^ i \hat{x}_i, \hat{y}_i x^i,y^i)。只有当对象出现在网格单元 i 时,这部分损失才会计算(由 1 i j o b j 1_{ij}^{obj} 1ijobj指示)。
-
边界框尺寸的平方误差:计算预测的边界框宽度( w i w_i wi)和高度( h i h_i hi)与真实值的误差。这部分也仅当对象出现在网格单元i并且由j个边界框预测器负责预测时计算。
-
条件类别损失:如果网格单元中有对象,只惩罚分类误差。
-
无对象损失:如果网格单元中没有对象,会惩罚预测有对象但实际上没有的情况。
-
分类损失:对每个网格单元和类别,计算预测的类别概率( p i ( c ) p_i(c) pi(c))和真实类别概率( p ^ i ( c ) \hat{p}_i(c) p^i(c))之间的误差。
损失函数中包括了几个参数( λ c o o r d , λ n o o b j \lambda_{coord}, \lambda_{noobj} λcoord,λnoobj)用来加权不同类型的误差,以解决不同误差对损失贡献的不平衡问题。
训练细节
-
迭代次数:作者提到模型在PASCAL VOC 2007和2012数据集上训练了大约135个epoch。
-
学习率调整:他们使用了一个逐渐调整的学习率策略。从 1 0 − 3 10^{-3} 10−3慢慢提高到 1 0 − 2 10^{-2} 10−2,如果直接开始用高学习率,模型通常会因为梯度不稳定而发散。
-
批量大小和动量:训练过程中使用的是批量大小为64,动量为0.9,衰减为0.0005。
防止过拟合
为了防止过拟合,YOLOv1采取了几个措施:
-
使用dropout:在第一个全连接层后加入了dropout,比率为0.5。
-
数据增强:包括随机缩放和平移原始图像最多20%,并且在HSV色彩空间中随机调整图像曝光和饱和度。
总体来说,这部分详细阐述了YOLOv1如何在目标检测任务中平衡位置、尺寸以及分类的准确性,并且解释了训练过程中如何避免过拟合以及如何稳定和优化模型性能的一些策略。
2.3 推理
YOLOv1模型在测试阶段的效率和它如何处理多个边界框的问题。
-
测试时间效率:与训练时类似,YOLO模型在测试图像时仅需要进行一次网络评估。这是因为YOLO直接在整个图像上一次性进行预测,不需要对图像的多个部分或不同尺寸分别进行评估。这与基于分类器的方法(如R-CNN系列)形成对比,后者通常需要在测试时对图像的多个候选区域进行多次评估。
-
边界框和类别概率的预测:在PASCAL VOC数据集上,YOLO网络为每幅图像预测了98个边界框,并为每个框预测了类别概率。这是由于每个 S × S S \times S S×S网格单元预测 B B B 个边界框,并为每个类别计算概率。
-
空间多样性:YOLO的网格设计强制实现边界框预测的空间多样性。通常情况下,很容易确定一个对象落在哪个网格单元内,网络对每个对象只预测一个框。然而,一些大型对象或者位于多个网格单元边界的对象可能会被多个网格单元定位。
-
非极大值抑制(Non-maximal Suppression, NMS):为了解决一个对象可能被多个网格单元预测的问题,可以使用非极大值抑制。NMS的工作原理是在多个重叠的预测框中只保留最有可能的一个框(即置信度最高的),并移除其他重叠的框。在YOLO中,虽然NMS对性能提升不像在R-CNN或DPM(两种其他的目标检测方法)中那样关键,但仍能在平均精度均值(mAP)上增加约23%。这说明,尽管YOLO不依赖于NMS来进行准确的单一检测,NMS的应用仍能显著提高模型的整体性能。
2.1 YOLOv1 的不足
-
空间约束:YOLOv1的设计中,每个 S × S S \times S S×S 网格单元只预测两个边界框,并且每个单元只能预测一个类别。这意味着如果多个对象靠近彼此位于同一网格单元内,YOLO可能无法正确分辨它们,因为单个网格单元的预测能力有限。这导致模型在检测小对象群体(如鸟群)时遇到困难,因为这些对象往往相互靠近。
-
泛化能力限制:YOLOv1从数据中学习预测边界框,因此,对于那些具有新颖或不寻常长宽比或配置的对象,模型的泛化能力受限。简而言之,如果训练数据中没有足够的例子来代表某些特定的对象属性,模型可能无法学会准确预测它们。
-
粗糙的特征表示:由于YOLO架构包含多个下采样层次,这会导致从输入图像中提取的特征较为粗糙。下采样可以导致精细的视觉信息丢失,这对预测精确的边界框不利。
-
损失函数的误差处理:YOLO的损失函数在处理小边界框和大边界框中的误差时采取了相同的方式。然而,在实践中,对于大边界框的小误差通常不会对检测性能产生太大影响,但对于小边界框,即使是小误差也会显著影响到交并比(IOU)的计算,从而对性能产生较大影响。
-
主要错误源:由于上述问题,YOLOv1的主要错误源是定位错误(localization errors),这意味着模型可能会生成不准确的边界框,无法紧密地围绕对象。
总之,这段内容说明YOLOv1在设计时为了实现高速检测牺牲了一些准确性,特别是在处理群体中的小对象、不常见的对象形状或尺寸以及不同大小边界框的误差时。这些问题在YOLO后续的版本中得到了一定程度的改进。














 105
105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









