






Camouflaged Object Detection
摘要
什么是Camouflaged Object Detection?
CV领域的一个新的子方向,致力于识别出“无缝”嵌入在周围环境中的目标
难点和挑战
high intrinsic similarities
目标物体和背景的高度内在相似性,所以比传统的目标检测更困难
作者的贡献
COD10数据集的制作
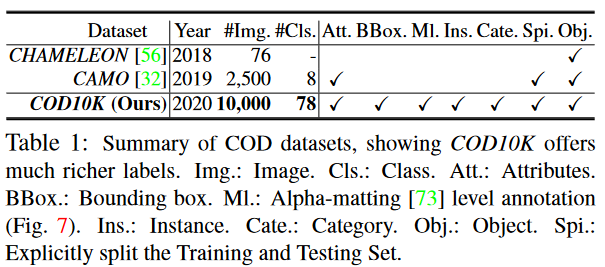
包含78种类别共10000余张不同自然场景下的包含伪装目标的图像,所有图像都用类别、边界框、对象/实例级和抠图级(matting-level)标签进行了密集标注。
备注:在计算机视觉中,“matting-level” 图像标注是一种高级的图像处理技术,用于精确地分割图像中的前景和背景。这种技术通常被称为 “图像抠图” 或 “alpha matting”。其核心目标是为图像中的每个像素分配一个alpha值,这个值表示该像素属于前景的概率。
这里的关键特点是:
- Alpha通道:Matting技术涉及到创建一个alpha通道,它是一种表示透明度的额外通道。Alpha值介于0(完全透明,即完全属于背景)到1(完全不透明,即完全属于前景)之间。
- 高精度分割:与传统的二值(前景/背景)分割不同,matting允许更细致的过渡,这对于处理复杂背景或模糊边缘(如头发、烟雾等)特别有用。
- 应用场景:这种技术广泛应用于图像编辑、视觉特效制作、合成现实等领域,特别是在需要精确控制图像元素如何与其他元素或背景混合时。
提出了 SINet(Search Identification Network)
SINet 在所有测试的数据集上都优于各种目标检测 SOTA Baseline,使其成为一个强大的通用框架,可以促进 COD 的未来研究。最后,作者进行了一项大规模的 COD 研究,评估了 13 个前沿模型,提供了一些有趣的发现,并展示了 COD 一些潜在的应用。
1. 导言

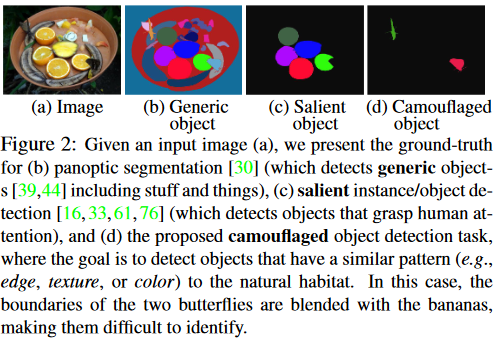
你能从图1中找到隐藏的物体吗?生物学家将其称为 background matching camouflage ,也就是说动物尝试将其身体的颜色完美地和周围环境物融合,来避免被识别出。感官生态学家发现,这种伪装策略主要是通过欺骗观察者的视觉感知系统, 因此,伪装目标检测需要大量的视觉感知知识。
正如图 2 所示,目标对象与背景之间的高度内在相似性使得 COD 比传统的显著对象检测或一般的目标检测更具挑战性。
除了科研价值,COD 在应用领域也很有用,比如搜救工作,医学图像分割,稀有物种探索,农业(害虫检测),艺术领域。
 然而,目前该领域由于数据集的缺乏并未很好得到研究,作者做了 2 项贡献,首先是精心制作的 COD10K 数据集,
然而,目前该领域由于数据集的缺乏并未很好得到研究,作者做了 2 项贡献,首先是精心制作的 COD10K 数据集,
COD10K
- 10K张覆盖78多种不同伪装目标的图像,包括水生动物、飞行动物、两栖动物、以及陆地等
- 所有伪装图像都用类别、边界框、对象级和实例级标签进行分层标注,促进许多视觉任务,例如定位、对象提议、语义边缘检测、任务迁移学习等。
- 每张伪装图像都被分配了现实世界中具有挑战性的属性和抠图级标签(每张图像需要约 60 分钟)。这些高质量的注释可以帮助提供
其次,提出了简单却有效的框架 SINet (搜索和识别网络),使用收集的 COD10K 和两个现有数据集,我们对 12 个 SOTA baselines 进行了严格评估,使我们的研究成为最大的 COD 研究。 值得注意的是,SINet 的整体训练时间仅为 1 小时左右,并且在所有现有的 COD 数据集上实现了 SOTA 性能,这表明它可能是 COD 的潜在解决方案。 我们的工作构成了深度学习时代 COD 任务的第一个完整 benchmark,从伪装的角度为物体检测带来了新颖的视角。
2. 相关工作
目标可以大致分为 3 类:通用目标,显着目标,伪装目标
通用目标和显着性目标
通用目标检测
通用目标既可以是显著性目标也可以是伪装目标,只不过伪装目标可以认为是一种困难情形。典型的通用目标检测包含语义分割和全景分割(如图 2b)
显着性目标检测
旨在识别图像中最引人注目的对象,然后分割它们的像素级轮廓。
尽管术语“显着”本质上与“伪装”相反(突出与沉浸),但显着物体仍然可以为伪装物体检测提供重要信息,例如 通过使用包含显着对象的图像作为负样本。 也就是说,显着性目标检测的正样本(包含显着对象的图像)可以用作 COD 数据集中的负样本。
伪装目标检测
数据集
CHAMELEON 一个未发布的数据集,仅包含 76 张带有手动注释的对象级真实值 (GT) 的图像。 这些图像是通过谷歌搜索引擎使用“伪装动物”作为关键词从互联网上收集的。 另一个当代数据集是 CAMO,它有 2500 张图像(2K 用于训练,0.5K 用于测试),涵盖八个类别。 它有两个子数据集,CAMO 和 MS-COCO,每个子数据集包含 1.25K 图像。
COD10K 致力于设计高质量的伪装目标检测数据集,就作者所知,COD10K 是截至论文发表时最大的伪装目标检测数据集。
伪装图像类型
伪装图像大致可分为两种类型:包含自然伪装的图像和包含人工伪装的图像。 动物(例如昆虫、头足类动物)使用天然伪装作为一种生存技能,以避免被捕食者识别。
相比之下,人工伪装通常出现在制造过程中的产品中(所谓的缺陷),或者用于游戏/艺术中以隐藏信息。
伪装目标检测公式标记
与语义分割等类相关任务不同,COD 是类无关任务。
因此,COD 的公式简单且易于定义。
给定图像,该任务需要一种伪装目标检测方法来为每个像素 i i i 分配一个置信度 p i ∈ [ 0 , 1 ] p_i∈ [0,1] pi∈[0,1] ,其中 p i p_i pi表示像素 i i i 的概率得分。 不属于伪装对象的像素得分为 0,而得分为 1 表示像素完全分配给伪装对象。
本文重点关注对象级 COD 任务,实例级COD 留给未来的工作。
评价指标
平均绝对误差 (MAE) 广泛应用于 SOD 任务中。我们也采用 MAE ( M M M) 指标来评估 predicted map C C C 和 ground-truth G G G 之间的像素级精度。
然而,尽管 MAE 在评估误差的出现和数量上很有用,但是不能确定误差在哪里发生。最近,Fan 等人提出了基于人类视觉感知的 E-measure( E ϕ E_\phi Eϕ),能够同时评估像素级匹配和图像级统计,该指标自然适合评估伪装目标检测结果的整体和局部准确性。
由于伪装目标经常包含复杂的形状,COD 也需要一个指标能够度量结构相似性,所以作者也使用 S-measure( S α S_\alpha Sα) 指标。最近的研究表明带权 F-measure( F β w F_{\beta}^{w} Fβw) 比传统的 F β F_{\beta} Fβ 可提供更可靠的评估结果,作者也使用该指标。
3. 提出的数据集

图像收集
标注质量和数据集大小是其作为 benchmark 的生命周期的决定性因素。
COD10 包含 10000 张图像,5066 张伪装图像,3000 张背景图像,1934 张非伪装图像。10000 张图像分为 10 个父类,78个子类(69 个伪装,9 个非伪装),这些图像收集自多个摄影网站。
大多数伪装图像来自 Flicker,并已应用于学术用途,关键词如下:伪装动物、不引人注目的动物、伪装鱼、伪装蝴蝶、隐藏狼蛛、手杖、死叶螳螂、鸟、海马、猫、侏儒海马等(见图 4e)
其余的伪装图像(大约 200 张图像)来自其他网站,包括 Visual Hunt、Pixabay、Unsplash、Free-images 等,这些网站发布公共领域的库存照片,不受版权的影响。
为了避免选择偏差,我们还从 Flickr 收集了 3,000 张显着图像。 为了进一步丰富负样本,从互联网上选取了 1934 张非伪装图片,包括森林、雪地、草原、天空、海水等类别的背景场景。
专业标注
分类系统在创建大规模数据集时至关重要
建立分类系统的重要性:分类系统有助于组织和理解数据集中的信息。在伪装目标检测的情境中,这可能意味着按类型、位置、伪装特征等对目标进行分类。
注释的层次结构:
category -> bounding box -> attribute -> object/instance
- 类别:这可能是最广泛的层次,比如车辆、人物、动物等。
- 边界框:这是目标检测中常用的,用于指定图像中对象的具体位置。
- 属性:这可能涉及目标的特定特征,如颜色、大小或特定于伪装的属性。
- 对象/实例:这指的是数据集中的具体对象或实例。
通过众包获得的注释(obtained via crowdsourcing):这表明数据集的标记是通过大量人员的共同努力完成的,可能涵盖了广泛的视角和解释。
Categories
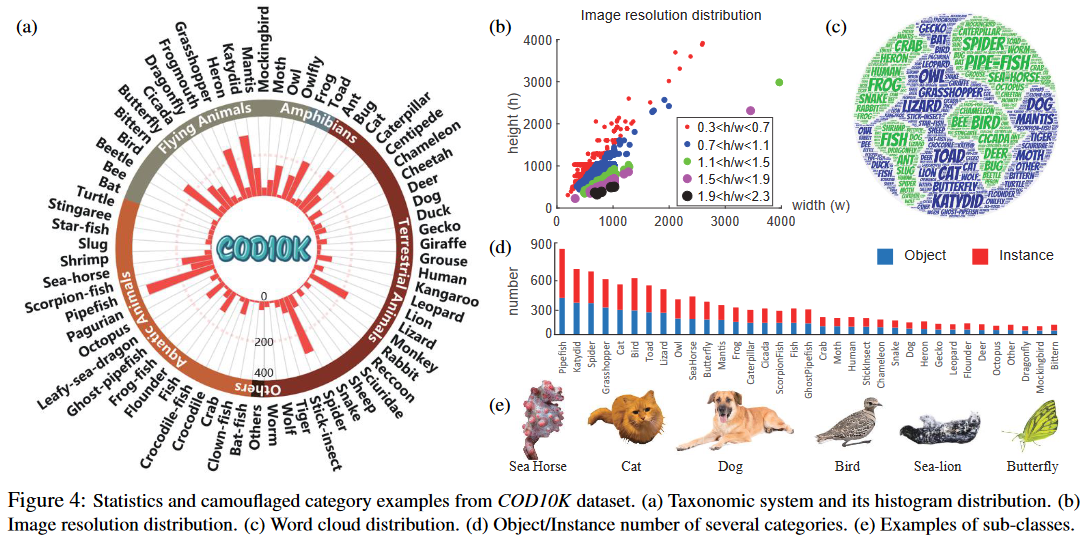
如图 4a 所示,首先创建了 5 个父类,然后根据作者收集到的数据将最频繁出现的69个子类别进行总结。
我们标记每个图像的子类和父类。 如果候选图像不属于任何既定类别,我们将其分类为“其他”。
Bounding boxes
为了使 COD10K 能够用于提出的伪装目标检测任务,作者也对每张图像的 bounding boxes 进行了仔细标注
Attributes
根据相关文献,作者为每个伪装图像标记了自然场景中面临的极具挑战性的属性,例如遮挡、无法定义的边界。
表 2 中提供了属性描述,co-attribute distribution 如图 5 所示

Objects/Instances
现有的 COD 数据集仅关注 object-level 对象级标签(表 1)。
然而,能够将 object (目标)解析成对应 instances (实例)对于 CV 研究人员能够编辑和理解场景非常重要。
为此,和 COCO 数据集一样,作者进一步在 instance-level 对目标进行注释,得到 5,069 个对象级别掩码和 5,930 个实例级别 Ground-Truth。
数据集特征和统计

-
Object size
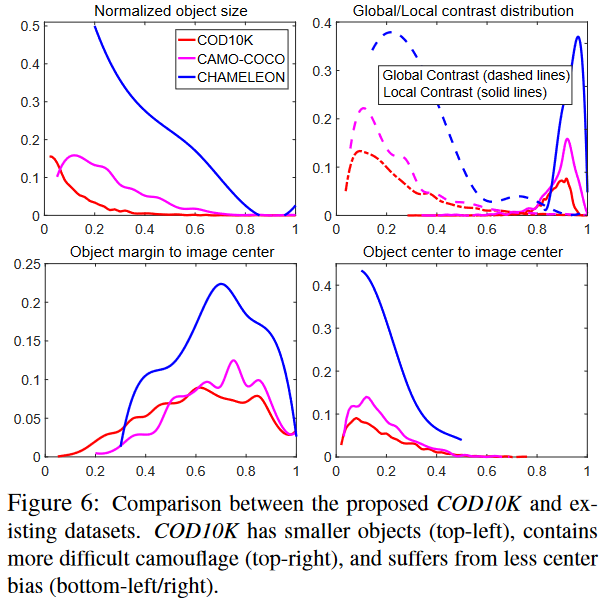
图 6(左上)绘制了标准化对象尺寸,即尺寸分布从 0.01%∼80.74%(平均值:8.94%),与CAMO-COCO 和 CHAMELEO 相比,显示出更广泛的范围。 -
Global/Local contrast
为了评估一个对象是否易于检测,作者使用全局/局部对比策略来描述。 图 6(右上)显示 COD10K 中的对象比其他数据集中的对象更具挑战性。 -
Center bias
通常发生在拍照时,因为人类倾向于聚焦一幅场景的中央。作者采取了其他论文中的策略,图 6 下半部分显示 COD10K 数据集的 center bias 更小 -
Quality control
为了确保高质量的标注,作者邀请了三位观众参与标注过程,进行 10 折交叉验证。 图 7 显示了通过/拒绝的示例。 这种实例级标注平均每张图像花费约 60 分钟。 -
Super/Sub-class distribution
COD10K 包括 5 个超类(陆生、大气、水生、两栖、其他)和 69 个子类(例如蝙蝠鱼、狮子、蝙蝠、青蛙等)。
各种类别的词云 (wordcloud) 和对象/实例数量的示例分别如图 4 c 和 d 所示。 -
Resolution distribution
高分辨率数据为模型训练提供更多的对象边界细节,并在测试时产生更好的性能。 图4(b)展示了 COD10K 的分辨率分布,其中包含大量全高清 1080p 图像。 -
Dataset splits
为了给深度学习模型提供大量的训练数据,COD10K 被分成 6,000 张图像用于训练,4,000 张用于测试,从每个子类中随机选择。
4. 提出的框架
动机
生物学研究表明,捕食者在捕猎时,首先会判断是否存在潜在的猎物,即寻找猎物; 然后,可以识别目标动物; 最后,它可以被捕获。
总览
所提出的 SINet 框架的灵感来自于狩猎的前两个阶段。 它包括两个主要模块:搜索模块(SM)和识别模块(IM)
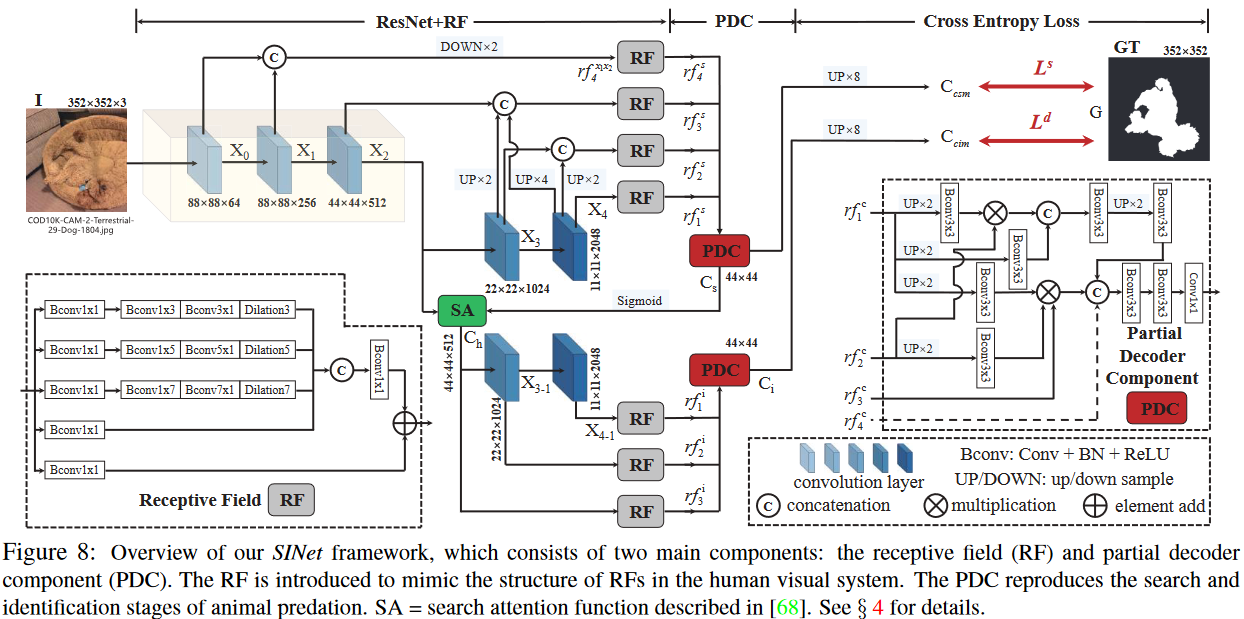
Search Module (SM)
神经科学实验已经证实,在人类视觉系统中,一组不同大小的群体感受野(pRF)有助于突出靠近视网膜中央凹的区域,该区域对微小的空间变化很敏感。 这促使我们在搜索阶段(通常在小/局部空间中)使用 RF 组件来合并更具辨别力的特征表示。
具体而言,对一个输入图像
I
∈
\rm{I}\in
I∈
R
W
×
H
×
3
\mathbb{R}^{W\times H\times 3}
RW×H×3,
{
X
k
}
k
=
0
4
\{\mathcal{X}_k\}_{k=0}^{4}
{Xk}k=04是从 ResNet-50 提取的一组特征,为了保留更多信息,作者修改参数 stride = 1,以在第二层中具有相同的分辨率。
因此,每层的分辨率为
{
[
H
k
,
W
k
]
,
k
=
4
,
4
,
8
,
16
,
32
}
\{[\frac{H}{k},\frac{W}{k}], k=4,4,8,16,32\}
{[kH,kW],k=4,4,8,16,32}
最近的证据表明,网络浅层的低级特征保留用于创建目标边界的空间细节,深层的高级特征保留用于定位目标的语义信息。由于神经网络的这种自然特性,作者将提取到的特征分为低级特征
{
X
0
,
X
1
}
\{\mathcal{X}_0,\mathcal{X}_1\}
{X0,X1},中级特征
X
2
\mathcal{X}_2
X2,高级特征
{
X
3
,
X
4
}
\{\mathcal{X}_3,\mathcal{X}_4\}
{X3,X4},
并且将这些特征进行 concatenation,up-sampling, down-sampling.
SINet 利用密集连接策略来保留来自不同层的更多信息,然后使用修改后的 RF 组件来扩大感受野。作者使用 concatenation 串联操作融合低级特征 { X 0 , X 1 } \{\mathcal{X}_0,\mathcal{X}_1\} {X0,X1},然后将分辨率下采样一半。这个新的特征 r f 4 x 1 x 2 rf_{4}^{x1x2} rf4x1x2 接下来送入 RF 组件来生成输出特征 r f 4 s rf_{4}^{s} rf4s . 正如图 8 所示,在结合 3 种级别的特征后,现在有了一组增强的特征 { r f k s } \{rf_{k}^{s}\} {rfks} 用于学习强大的线索
Receptive Field (RF)
RF 组件包含 5 个分支, { b k , k = 1 , . . . , 5 } \{b_{k},k=1,...,5\} {bk,k=1,...,5},在每个分支中,第一个卷积层 (Bconv) 的维度是 1 × 1 1\times 1 1×1 用于降低通道大小到 32,紧下来是另外 2 个层:一个 ( 2 k − 1 ) × ( 2 k − 1 ) (2k-1)\times(2k-1) (2k−1)×(2k−1) 的 Bconv 层和一个 当 k > 2 k > 2 k>2 时具有特定膨胀率 ( 2 k − 1 ) (2k − 1) (2k−1) 的 3 × 3 3\times 3 3×3 Bconv 层。
前四个分支被连接 concatenation 起来,然后通过 1 × 1 1 × 1 1×1 Bconv 操作将它们的通道大小减少到 32。
最后,添加第 5 个分支,并将整个模块输入 ReLU 函数以获得特征 r f k rf_k rfk
Identification Module (IM)
从前面的搜索模块获得候选特征后,在识别模块中,需要精确地检测伪装对象。 作者用密集连接的特征扩展了部分解码器组件(PDC)。 更具体地说,PDC 集成了 SM 模块的四个级别的特征。
因此,粗略伪装图 camouflage map C s C_s Cs 可以通过以下方式计算:
C s = P D s ( r f 1 s , r f 2 s , r f 3 s , r f 4 s ) ~~~~~~~~~~~~~C_s=PD_s(rf_{1}^{s},rf_{2}^{s},rf_{3}^{s},rf_{4}^{s}) Cs=PDs(rf1s,rf2s,rf3s,rf4s)
这里 { r f k s = r f k , k = 1 , 2 , 3 , 4 } \{rf_{k}^{s}=rf_k,k=1,2,3,4\} {rfks=rfk,k=1,2,3,4}
现有文献表明,注意力机制可有效消除不相关特征的干扰。作者
引入搜索注意力(SA)模块来增强中级特征
X
2
\mathcal{X}_2
X2 获得增强的伪装图
C
h
C_h
Ch
C h = f m a x ( g ( X 2 , σ , λ ) , C s ) ~~~~~~~~~~~~~C_h=f_{max}(g(\mathcal{X}_2,\sigma,\lambda),C_s) Ch=fmax(g(X2,σ,λ),Cs)
这里 g ( ⋅ ) g(\cdot) g(⋅) 是 SA 搜索注意力函数,实际上是一个典型的高斯滤波器,标准差 σ = 32 σ = 32 σ=32,kernel size λ = 4 λ = 4 λ=4,然后进行归一化操作。
f m a x ( ⋅ ) f_{max}(·) fmax(⋅)是一个最大值函数,用于突出 C s C_s Cs 的原始伪装区域。
为了全面获得高级特征,作者进一步利用 PDC 聚合另外三层特征,并通过 RF 功能增强,并获得最终的伪装图 C i C_i Ci
C i = P D i ( r f 1 i , r f 2 i , r f 3 i ) ~~~~~~~~~~~~~C_i=PD_i(rf_{1}^{i},rf_{2}^{i},rf_{3}^{i}) Ci=PDi(rf1i,rf2i,rf3i)
这里 { r f k i = r f k , k = 1 , 2 , 3 } \{rf_{k}^{i}=rf_k,k=1,2,3\} {rfki=rfk,k=1,2,3}
P D s PD_s PDs 和 P D i PD_i PDi 的区别是输入特征的数量
Partial Decoder Component (PDC)
形式上,给定搜索和识别阶段的特征
{
r
f
k
c
,
k
∈
[
m
,
.
.
.
,
M
]
,
c
∈
[
s
,
i
]
}
\{rf_{k}^{c},k\in[m,...,M],c\in[s,i]\}
{rfkc,k∈[m,...,M],c∈[s,i]},作者使用上下文模块生成新的特征
{
r
f
k
c
1
}
\{rf_{k}^{c1}\}
{rfkc1}。采用逐元素乘法 (Element-wise multiplication) 来减少相邻特征之间的差距。
具体而言,对于像是
r
f
4
s
rf_{4}^{s}
rf4s 的浅层特征,当
k
=
M
k=M
k=M 时作者设置
r
f
M
c
1
=
r
f
M
c
2
rf_{M}^{c1} = rf_{M}^{c2}
rfMc1=rfMc2,对于深层特征像是
r
f
k
c
1
,
k
<
M
rf_{k}^{c1}, k<M
rfkc1,k<M,作者更新其为
r
f
k
c
2
rf_{k}^{c2}
rfkc2
r f k c 2 = r f k c 1 ⊗ Π j = k + 1 M B c o n v ( U P ( f j c 1 ) ) ~~~~~~~~~~~~~rf_{k}^{c2}=rf_{k}^{c1}⊗ Π_{j=k+1}^{M}Bconv(UP(f_{j}^{c1})) rfkc2=rfkc1⊗Πj=k+1MBconv(UP(fjc1))
这里,
k
∈
[
m
,
.
.
.
,
M
]
,
B
c
o
n
v
(
⋅
)
k\in[m,...,M], Bconv(\cdot)
k∈[m,...,M],Bconv(⋅) 是一个顺序运算,结合了一个
3
×
3
3 × 3
3×3 卷积、批归一化和 ReLU 函数。
U
P
(
⋅
)
UP(\cdot)
UP(⋅) 是比例为
2
j
−
k
2^{j-k}
2j−k 的上采样操作。
最后,通过串联操作组合这些判别特征。
作者用于训练 SINet 的损失函数是交叉熵损失 L C E L_{CE} LCE 。 总损失函数 L L L 为:
L = L C E s ( C c s m , G ) + L C E i ( C c i m , G ) ~~~~~~~~L = L_{CE}^{s}(C_{csm},G)+ L_{CE}^{\mathcal{i}}(C_{cim},G) L=LCEs(Ccsm,G)+LCEi(Ccim,G)
其中 C c s m C_{csm} Ccsm和 C c i m C_{cim} Ccim是 C s C_s Cs 和 C i C_i Ci 上采样到 352 × 352 352×352 352×352分辨率后得到的两个伪装物体图。
实现细节
SINet 在 PyTorch 中实现,并使用 Adam 优化器进行训练。 在训练阶段,batch size 设置为 36,学习率从1e-4 开始。 整个训练时间仅 70 分钟左右,30 个 epoch(早停策略)。 运行时间是在Intel i9-9820X CPU @3.30GHz × 20和TITAN RTX 平台上测得。 对于 352 × \times × 352 的图像,测试时间为 0.2s。
5. Benchmark Experiments
实验设置
训练/测试细节
为了验证 SINet 的泛化能力,作者使用 3 组训练设置,使用的训练集(伪装图像)包括:CAMO,COD10K,CAMO + COD10K + EXTRA
对于 CAMO,作者使用默认训练集,对于 COD10K,作者使用默认的训练伪装图像。作者在整个 CHAMELEON 数据集以及 CAMO 和 COD10K 的测试集上评估他们的模型。
Baselines
据作者所知,还没有公开的基于深度网络的 COD 模型。
因此,作者根据以下标准选择 12 个深度学习 baselines:(1) 经典架构,(2) 最近发表,(3) 在特定领域,例如 GOD 或 SOD 已实现 SOTA 性能。
使用 (iv) 训练设置,使用推荐的参数设置对这些基线进行训练,这些 baselines 是使用推荐的参数设置进行训练的
结果和数据分析
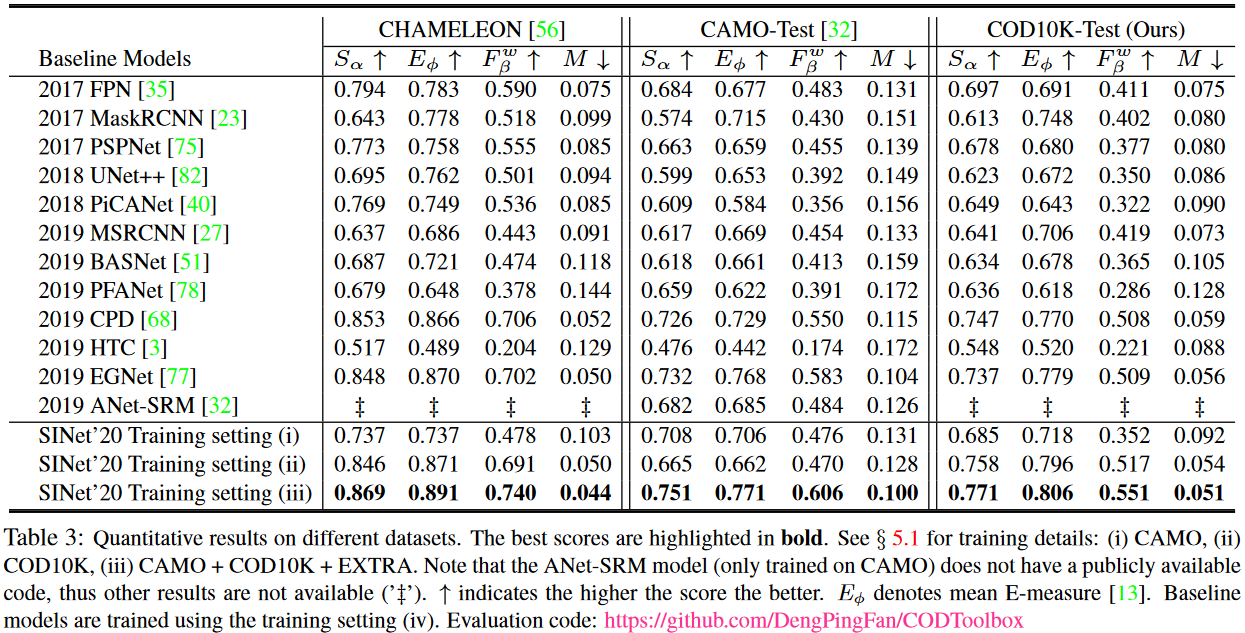
Performance on CHAMELEON
从表 3 可看出,与 12 个 SOTA 目标检测模型的 baselines 相比,SINet 在所有指标上达到了最佳。作者的模型不应用任何辅助边缘/边界特征、预处理技术或后处理策略。
Performance on CAMO
作者也在最近提出的 CAMO 数据集上测试其模型,其中包括各种伪装物体。 基于表 3 中报告的总体表现,作者发现 CAMO 数据集比之前的数据集更具挑战性。 SINet 再次获得最佳性能,进一步证明了其鲁棒性。
Performance on COD10K
通过 COD10K 数据集的测试集(2,026 张图像),作者再次观察到所提出的 SINet 始终优于其他竞争对手。 这是因为其专门设计的搜索和识别
模块可以自动学习丰富的高/中/低级特征,这对于克服对象边界中具有挑战性的模糊性至关重要(见图9)
GOD vs. SOD Baselines
值得注意的发现是,在 top 3 模型中,GOD 模型比 SOD 表现得差,意味着 SOD 模型可能更适合拓展于 COD 任务。与其他的 GOD 或 SOD 模型相比,SINet 明显降低训练时长,并且在所有数据集上实现了 SOTA 性能。
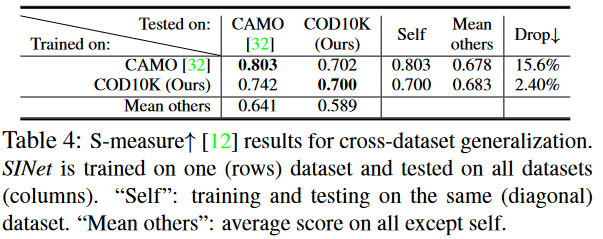
Cross-dataset Generalization
数据集的通用性和难度在训练和评估不同算法时起着至关重要的作用。
因此,作者使用跨数据集分析方法研究现有 COD 数据集,即在一个数据集上训练模型,并在其他数据集上测试模型。 作者选择两个数据集,包括 CAMO 和 COD10K。 按照其他论文的做法,对于每个数据集,随机选择 800 张图像作为训练集,200 张图像作为测试集。 为了公平比较,作者在每个数据集上训练 SINet,直到损失稳定。
表 4 提供了 Cross-dataset Generalization 的 S-measure 结果。
每行列出一个在一个数据集上训练并在所有其他数据集上进行测试的模型,表明用于训练的数据集的通用性。
每列显示一个模型在特定数据集上测试并在所有其他数据集上训练的性能,表明测试数据集的难度。
注意,训练/测试设置与表 3 中使用的设置不同,因此性能不具有可比性。 正如预期的那样,作者发现 COD10K 是最困难的(例如,最后一行)。 这是因为作者的数据集包含各种具有挑战性的伪装对象。可以看到 COD10K 数据集适合更具挑战性的场景。
Qualitative Analysis
图 9 展示了 SINet 和两个 baselines 之间的定性比较。 可以看出,PFANet 能够定位伪装的物体,但输出总是不准确。
通过进一步利用边缘特征,EGNet 实现了比 PFANet 相对更准确的定位。尽管如此,它仍然错过了物体的细节,尤其是第一排的鱼。 对于所有这些具有挑战性的情况(例如,无法定义的边界、遮挡和小物体),SINet 能够推断出具有精细细节的真实伪装物体,证明了作者提出的框架的稳健性。

6. 潜在的应用
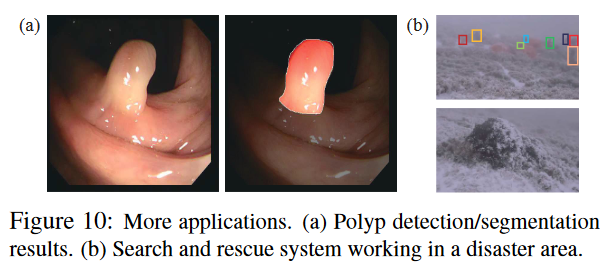
医学图像分割
如果医学图像分割方法配备了针对特定对象(例如息肉)进行训练的伪装检测系统,则可以用于自动分割息肉(图10a)。
在自然界中寻找和保护稀有物种,甚至在灾区进行搜救。
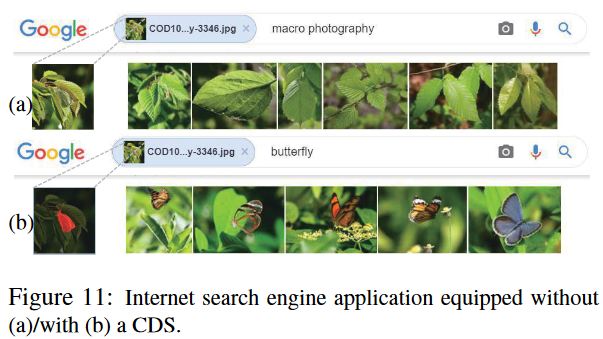
搜索引擎
图 11 显示了 Google 搜索结果的示例。 从结果(图11a)中,注意到搜索引擎无法检测到隐藏的蝴蝶,因此仅提供具有相似特征的图像
背景。
有趣的是,当搜索引擎配备伪装检测系统时(这里,只是简单地改变关键词),引擎可以识别出伪装的物体,然后反馈几张蝴蝶图像(图11b)。
7. 结论
作者从伪装的角度提出了第一个完整的目标检测基准。
具体而言,作者提供了一个新的具有挑战性的并且密集标注的 COD10K 数据集,进行了大规模评估,开发了一个简单但高效的端到端 SINet 框架,并提供了几个潜在的应用。 与现有的顶尖 baselines 相比,SINet 具有竞争力,并且可以产生更美观的结果。
上述贡献为社区提供了为 COD 任务设计新模型的机会。
在未来的工作中,作者计划扩展 COD10K 数据集以提供各种形式的输入,例如 RGB-D 伪装物体检测(类似于 RGB-D 显着物体检测)等。
还可以探索弱监督学习、零样本学习、变分自编码器 VAE 和多尺度骨干等新技术。















 777
777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









