







作者通过将图像重建任务引入为辅助任务,使得网络在训练过程中能够更全面地学习图像特征,从而在实际的二值分割任务(COD和SOD)中表现得更为出色。这种方法提高了网络的泛化能力和分割准确性,是这篇论文的一个重要创新点。
动机,贡献,创新点
这篇论文的动机、贡献和创新点总结如下:
动机
- 任务背景:伪装物体检测(COD)和显著物体检测(SOD)是计算机视觉中两个不同但密切相关的任务。两者的共同目标是将图像分割成前景和背景区域,区别在于COD关注隐藏在图像中的伪装物体,而SOD则关注图像中最显著的物体。
- 现有方法的局限:之前的工作通过堆叠各种手工设计的模块和多尺度特征来实现较好的性能,但这些复杂的网络结构通常在一个任务上表现良好,而在另一个任务上表现不佳。
- 设计简化:为了克服这些问题,该论文提出了一种基于视觉Transformer(ViT)的简单有效的网络(SENet),通过简单的设计实现对这两种任务的有效处理。
贡献
- 提出SENet:提出了一种基于ViT的简单有效的网络结构SENet,能够在COD和SOD任务上表现出色,比精心设计的复杂网络更具通用性。
- 局部信息捕捉模块(LICM):为提高Transformer在像素级二值分割任务中的局部信息建模能力,提出了一种局部信息捕捉模块(LICM),通过小卷积核捕捉局部信息,并与Transformer提取的全局信息融合。
- 动态加权损失(DW Loss):提出了一种基于二元交叉熵(BCE)和交并比(IoU)损失的动态加权损失函数,使网络根据目标对象的大小对更小、更难检测的目标对象给予更多关注。
- 联合训练:探讨了SOD和COD的联合训练问题,并提出了初步的解决方案,以优化联合训练性能,提高SOD任务的表现。
创新点
- 简单有效的网络结构:与之前复杂的多模块设计不同,SENet采用了对称的ViT编码器-解码器结构,通过简化设计在两个任务上均取得了优异的表现。
- LICM模块:通过并行于每个Transformer块中的多头自注意力层和多层感知机层,LICM模块能够有效捕捉局部信息,提高像素级分割任务的性能。
- DW损失函数:动态加权损失函数根据目标区域的大小动态调整权重,有助于网络更好地处理小目标,提高整体检测性能。
- 联合训练框架:提出了两种联合训练范式,并通过实验验证了其在解决联合训练中的任务冲突方面的有效性,为进一步研究联合训练提供了基础。
希望这些总结能帮助你更好地理解这篇论文的核心内容和创新点。如果还有其他问题,随时告诉我。
模型结构图
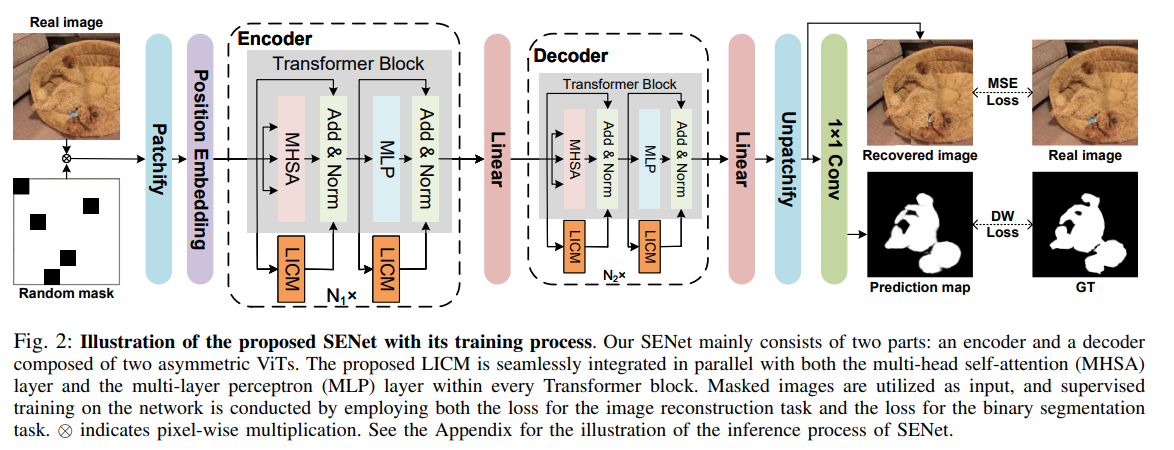
这张图展示了SENet的训练过程,以下是对图中各部分的详细解释:
左侧:输入图像和随机掩码
- Real image(真实图像):左上角显示的是输入的真实图像,图中是一个伪装物体。
- Patchify:真实图像首先被划分为若干个不重叠的小块(patch)。
- Position Embedding(位置嵌入):对每个小块进行位置编码,帮助模型理解每个小块在原图像中的位置。
- Random mask(随机掩码):部分小块被随机遮挡,即被掩码处理,仅保留一部分小块用于编码。
中间:编码器(Encoder)
- Transformer Block(Transformer块):编码器由多个Transformer块组成。每个块包含两个主要部分:
- MHSA(Multi-Head Self-Attention,多头自注意力):用于全局信息建模。
- MLP(Multi-Layer Perceptron,多层感知机):用于进一步处理和提取特征。
- Add & Norm(加法与归一化):每个子层之后进行加法与归一化处理。
- LICM(Local Information Capture Module,本地信息捕获模块):并行于MHSA和MLP层,用于捕获局部信息,使得Transformer块能够更好地处理像素级的二值分割任务。
中间:解码器(Decoder)
- Linear(线性层):编码器输出的特征经过线性层处理后进入解码器。
- Transformer Block(Transformer块):解码器同样由多个Transformer块组成,每个块包含与编码器相同的MHSA、MLP和Add & Norm层,并同样并行集成了LICM模块。
- Unpatchify:将解码器输出的特征恢复为图像的形状。
- 1×1 Conv(1×1卷积):通过1×1卷积生成单通道的预测图。
右侧:训练过程中的损失计算
- Recovered image(恢复图像):解码器输出的重建图像,用于计算图像重建任务的损失(MSE Loss)。
- Real image(真实图像):用于与恢复图像进行比较,计算均方误差(MSE)损失。
- Prediction map(预测图):解码器输出的二值分割图,用于预测伪装物体的位置。
- GT(Ground Truth,真实标签):真实的二值标签图像,用于计算分割任务的动态加权损失(DW Loss)。
损失函数
- MSE Loss:用于图像重建任务的损失计算,通过比较恢复图像和真实图像计算均方误差。
- DW Loss:用于二值分割任务的损失计算,根据目标区域的大小动态调整权重,提高网络对小目标的检测能力。
这张图整体展示了SENet在训练过程中如何利用编码器和解码器进行特征提取和图像重建,同时通过计算不同的损失函数来优化模型的性能。
LICM
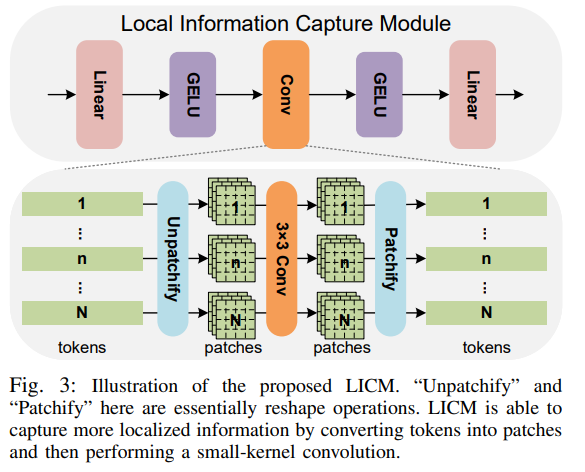
这张图展示了所提出的局部信息捕获模块(LICM)的结构和工作原理,以下是对图中各部分的详细解释:
上半部分:LICM的结构
- Linear(线性层):首先对输入的token进行线性变换。
- GELU(Gaussian Error Linear Unit,高斯误差线性单元):在每个线性层后面使用GELU激活函数,增加模型的非线性表达能力。
- Conv(卷积层):使用小卷积核(3×3)进行卷积操作,捕捉局部特征。
- Linear(线性层):最后再进行一次线性变换。
下半部分:LICM的工作流程
- 输入tokens:最左侧是输入的tokens,这些tokens是由图像patch经过位置编码后的结果。
- Unpatchify(反块化):将1D的tokens转换为2D的patches,目的是为后续的卷积操作做准备。这一步骤本质上是一个reshape操作。
- 3×3 Conv(3×3卷积):对2D的patches进行3×3的小卷积核卷积操作,以捕捉局部信息。每个patch内的像素进行信息交换,提取更细粒度的特征。
- Patchify(块化):将卷积后的2D patches重新转换为1D的tokens,这一步同样是一个reshape操作。
- 输出tokens:最右侧是经过LICM模块处理后的tokens,这些tokens包含了更丰富的局部信息。
详细工作原理
- 局部信息捕获:LICM通过3×3的小卷积核对patch内部的像素进行卷积操作,有效地捕捉局部信息。与传统的Transformer块不同,LICM不仅关注全局信息,还增强了对局部特征的提取。
- 并行集成:LICM模块并行于每个Transformer块中的多头自注意力层(MHSA)和多层感知机层(MLP),在保留全局信息建模能力的同时,增强了局部信息的建模能力。
- 残差连接:通过残差连接将LICM输出与MHSA和MLP的输出相加,有助于稳定训练并提升模型性能。
图中标注的内容
- tokens:输入和输出的tokens,在进入和离开LICM时分别进行patchify和unpatchify操作。
- patches:中间的patches是卷积操作的输入和输出,通过unpatchify和patchify进行转换。
- Linear、GELU、Conv:分别表示线性变换层、激活函数层和卷积层,是LICM内部的主要组成部分。
这张图整体展示了LICM模块的详细结构和数据流,通过这种设计,LICM能够在保持全局信息建模能力的同时,显著增强对局部细节的捕捉能力,从而提高像素级分割任务的性能。
Methodology
Section III: METHODOLOGY
A. Overall Architecture
-
架构概述:
- 图2展示了所提出的SENet的整体训练框架。SENet是一个简单的单路径模型,由一些基本模块组成,通过不对称的基于ViT的编码器-解码器结构,从输入的RGB图像生成单通道预测图。
- 使用图像重建和二值分割任务作为训练目标,其中图像重建是辅助任务。
-
流程:
- 输入图像首先被序列化为token,其中一小部分被随机掩码处理。
- 编码器对剩余的token进行操作,以建模全局和局部上下文。
- 解码器从潜在表示中恢复被移除的token。
- 最后,处理后的token被转换回原始图像形状,并通过1×1卷积操作获得所需的单通道预测图。
B. Local Information Capture Module (LICM)
-
动机:
- Transformer的核心注意力机制带来了强大的全局上下文建模能力,但缺乏在局部区域内的信息交换机制。
- COD和SOD是像素级分割任务,需要模型能够捕捉更细粒度的信息。
-
设计:
- LICM是一个即插即用的模块,应用于单个patch上,以增强局部特征表示,使基于ViT的SENet更适合像素级的COD和SOD任务。
- 如图3所示,LICM由三层可学习层组成:两层线性层用于改变1D token的维度,以及一层具有相同输入和输出通道的3×3卷积层。
- 在卷积之前,1D token被转换为具有2D结构的patch。然后,对每个独立的patch应用小卷积核卷积以提取更局部化的信息。最后,2D patch被还原为1D token。
-
集成:
- 将LICM并行插入每个Transformer块的MHSA层和MLP层。
C. Loss Function
-
图像重建损失:
- 参考ViT,原始图像被分割成规则的非重叠patch。然后从这些patch中抽样一个子集,掩码(即移除)其余部分。
- 编码器仅对抽样的patch(不包含掩码token)进行操作,解码器则恢复移除的部分,从而得到重建的图像。
- 使用均方误差(MSE)损失函数计算重建损失。
-
分割损失:
- 基于BCE和IoU损失提出了动态加权损失(DW Loss),使网络更关注那些目标区域较小且难以检测的实例。
- 为图像的边缘区域设置不同的权重,以根据目标对象的大小动态调整权重。
D. Joint Training
-
联合训练范式:
- 提出两种联合训练范式,如图4所示。
- 范式1:简单地混合COD和SOD数据进行训练,将两个任务视为相同的二值分割任务。
- 范式2:使用共享的编码器结构,并为两个任务使用独立的解码器。
-
训练过程:
- 在训练过程中同时使用COD和SOD数据。
- 分别计算两个前向过程的损失,然后基于这两个损失的平均值进行反向传播,以计算梯度并优化各自组件的参数。
这些方法和模块的设计目标是提高SENet在处理伪装物体检测(COD)和显著物体检测(SOD)任务时的性能,同时保持网络的简洁性和通用性。
实验细节
实验部分对COD任务的实现细节总结
数据集
论文在COD任务上使用了以下数据集:
- CAMO:包含1,000张训练图像和250张测试图像。
- CHAMELEON:包含76张测试图像,无训练图像。
- COD10K:包含3,040张训练图像和2,026张测试图像。
- NC4K:包含4,121张测试图像,无训练图像 。
实验设置
- 模型实现:SENet在PyTorch框架下实现,并在一台V100 GPU上优化。编码器和解码器的参数设置分别为:编码器维度768,头数12,深度12;解码器维度512,头数16,深度8。使用MAE预训练的编码器和解码器权重进行初始化。
- 图像预处理:所有输入图像大小调整为384×384,并随机水平翻转以进行数据增强。
- 掩码比例:训练时掩码比例设为5%,测试时设为0%。训练过程持续25个epoch,学习率初始化为0.0001,并通过poly策略调整,指数为0.9 。
性能比较
- 定量分析:在四个挑战性的COD基准数据集上的性能评估结果如表II所示。SENet在15项对比中取得了最佳结果,尤其是在最难的CAMO-Test数据集上,显著优于其他方法(例如,M指标比第二名小0.011)。SENet在这些数据集上的指标已经非常高,在更难的数据集上更能体现其优势 。
- 定性分析:图5展示了SENet与一些代表性竞争对手在典型伪装场景中的视觉比较,包括小型、多重、复杂形状和模糊边界伪装。可以看出,对比方法往往提供不正确的形状、不完整的目标区域,甚至完全错过目标,而SENet方法在这些方面表现出色,提供了更准确和完整的预测 。
消融实验
- LICM的有效性:在有无使用DW损失的两种情况下,添加LICM均有效提升了网络性能。LICM在COD任务中有更大的提升潜力,因为COD任务更具挑战性,改进空间更大 。
- DW损失的有效性:在有无使用LICM的两种情况下,添加DW损失均有效提升了网络性能。同样,DW损失在COD任务中带来了更大的改进。此外,与另一种广泛使用的加权损失比较,DW损失表现更好,证明了其有效性 。
- 双线性插值方法:双线性插值方法有效提升了网络性能,特别是在COD数据集上,因其解决了标注不确定性问题,从而提高了真实标签图像的质量 。
通过以上设置和实验,SENet在伪装物体检测任务上表现出了优异的性能和广泛的适用性。
联合训练范式
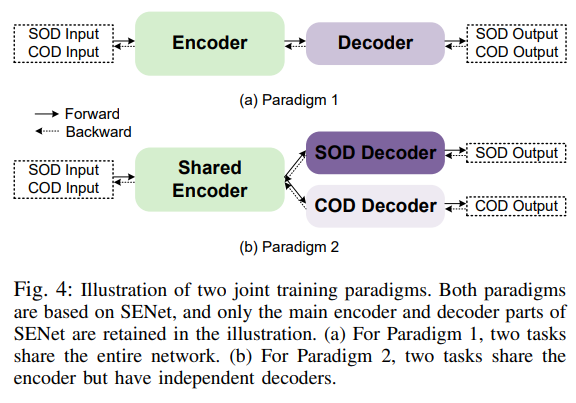
这张图展示了两种联合训练范式,用于同时处理显著物体检测(SOD)和伪装物体检测(COD)任务。以下是对图中各部分的详细解释:
范式1(Paradigm 1)
-
输入(SOD Input/COD Input):
- 同时接收SOD和COD任务的输入图像。
-
编码器(Encoder):
- 一个通用的编码器,用于处理来自SOD和COD的输入图像。编码器提取输入图像的特征表示。
-
解码器(Decoder):
- 编码器输出的特征被输入到解码器中,解码器生成SOD和COD任务的输出。
- 这里的解码器是共享的,即同一个解码器用于处理SOD和COD的特征。
-
输出(SOD Output/COD Output):
- 解码器生成的SOD和COD任务的结果。
优点:
- 这种范式简单,整个网络结构共享,有助于特征的融合和共享。
缺点:
- 由于SOD和COD任务的目标不同,这种完全共享的网络结构可能导致任务间的干扰,影响单个任务的性能。
范式2(Paradigm 2)
-
输入(SOD Input/COD Input):
- 同时接收SOD和COD任务的输入图像。
-
共享编码器(Shared Encoder):
- 一个共享的编码器,用于处理来自SOD和COD的输入图像。编码器提取输入图像的特征表示。
- 这里的编码器是共享的,即同一个编码器用于处理SOD和COD的输入。
-
独立解码器(SOD Decoder/COD Decoder):
- 编码器输出的特征分别输入到两个独立的解码器中,一个用于SOD任务,一个用于COD任务。
- 每个解码器专门处理一种任务,从而减少了任务间的干扰。
-
输出(SOD Output/COD Output):
- SOD解码器生成SOD任务的结果,COD解码器生成COD任务的结果。
优点:
- 这种范式在共享特征提取的同时,保留了任务特定的解码器,能够有效减少任务间的干扰,提高单个任务的性能。
缺点:
- 由于使用了独立的解码器,网络结构相对复杂一些,参数量也会增加。
总结
- Paradigm 1:整个网络共享同一个编码器和解码器,结构简单,但任务间可能互相干扰。
- Paradigm 2:共享编码器但使用独立的解码器,能够更好地处理任务间的干扰,提高单个任务的性能。
这两种范式提供了不同的策略来联合训练SOD和COD任务,具体选择哪种范式可以根据任务需求和实际表现进行调整。
作者如何生成随机掩码?
生成随机掩码的过程
在这篇论文中,作者提到了生成随机掩码的过程,主要参考了Masked Autoencoder(MAE)的思想。具体来说,步骤如下:
-
图像分块(Patchify):
- 输入图像首先被划分为若干个不重叠的小块(patch),这些小块通常是固定大小的,例如16×16像素。
-
随机抽样(Random Sampling):
- 从所有划分出的patch中随机抽样一个子集,并将其余的patch进行掩码处理,即将其移除。这意味着仅保留一部分patch用于编码器的处理,掩码比例在训练过程中一般设定为5%。
-
编码和解码(Encoding and Decoding):
- 编码器仅对未被掩码的patch进行特征提取,并生成一个潜在表示(latent representation)。
- 解码器从潜在表示中恢复被移除的patch,重建出完整的图像。
-
计算重建损失(Reconstruction Loss Calculation):
- 使用均方误差(MSE)损失函数计算重建图像与真实图像之间的差异。只计算被掩码部分的损失,确保模型能够有效学习被掩码部分的重建。
具体的掩码生成和应用过程如下图所示:
Original Image -> Patchify -> Random Sampling and Masking -> Encoder -> Latent Representation -> Decoder -> Reconstructed Image
这一步骤不仅帮助模型在特征提取时关注图像的细节和局部信息,同时通过图像重建任务提升了模型在伪装物体检测(COD)和显著物体检测(SOD)任务中的表现 。















 4609
4609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









