







动机
伪装物体检测(COD)因其在视觉上与背景高度相似,具有挑战性,尤其在对象尺寸较小、纹理模糊的情况下更为困难。现有的基于注意力机制的方法虽然取得了一定成果,但其高计算复杂度限制了应用。因此,论文作者希望开发一种高效且准确的方法来解决COD问题,同时减少计算资源的消耗。
贡献
- 提出了CamoFocus方法:通过特征分割和调制(FSM)模块和上下文细化(CRM)模块,显著提升了伪装物体检测的性能。
- 有效分离前景和背景特征:利用前景和背景调制器,以及监督掩码,精确地分离前景和背景特征,增强了对复杂视觉背景中物体的理解。
- 实现跨尺度特征细化:通过CRM模块,增强了跨尺度语义特征的理解,提高了特征表示的质量。
- 广泛实验验证:在多个基准数据集(CAMO、COD10K、CHAMELEON和NC4K)上进行评估,证明了CamoFocus在所有评估指标上均超越了现有的SOTA方法。
创新点
-
特征分割和调制模块(FSM):
- 前景和背景调制器:利用两个独立的调制器分别处理前景和背景特征,通过监督掩码引导,提升了特征分离的准确性。
- 深度卷积:采用深度卷积层进行特征投影和上下文理解,改善了对前景和背景对象的理解。
-
上下文细化模块(CRM):
- 跨尺度语义理解:通过处理不同尺度的输入特征并进行通道维度的拼接和卷积操作,增强了特征表示的语义理解。
- 跳跃连接:利用跳跃连接保持不同尺度特征之间的语义关系,提高了预测的准确性。
-
多损失函数结合:
- 加权交叉熵和IOU损失:结合了加权交叉熵损失和加权IOU损失,针对复杂样本进行优化,提高了模型对复杂场景中伪装物体的检测能力。
这些创新点使得CamoFocus在准确性和计算效率方面均优于现有方法,展示了其在伪装物体检测领域的潜力和有效性。
Method
方法概述
这篇论文提出了一种名为CamoFocus的新方法,用于检测伪装在背景中的物体。以下是对该方法的通俗总结:
研究背景
检测伪装物体非常困难,因为这些物体在视觉上与背景非常相似。这种检测在许多领域都有重要应用,比如野生动物保护、军事和医学影像分析。现有的方法虽然有效,但通常计算复杂度高,效率不够高。
方法概述
CamoFocus通过两个关键组件(特征分割和调制模块FSM,以及上下文细化模块CRM)来改进伪装物体的检测。
主要步骤
-
特征提取:
- 使用预训练的骨干网络从输入图像中提取多层次的特征。不同层次的特征代表不同尺度的信息。
-
掩码生成:
- 通过融合来自中间层的特征生成一个掩码。这掩码帮助区分图像中的前景(目标物体)和背景。
-
特征分割和调制模块(FSM):
- 分割特征:利用生成的掩码,将特征图分割为前景特征和背景特征。
- 调制特征:分别对前景和背景特征进行处理。前景调制器增强与物体相关的特征,背景调制器则抑制这些特征。
- 合并特征:将处理后的前景和背景特征重新组合,生成一个改进的特征图。
-
上下文细化模块(CRM):
- 跨尺度处理:将不同尺度的特征进行融合,通过卷积操作进一步提取和增强语义信息。
- 输出预测:生成多尺度的预测结果,用于伪装物体的最终检测。
-
损失函数:
- 使用加权交叉熵、加权交并比和Dice损失的组合,指导模型学习更准确地分割和检测伪装物体。
方法优势
- 更准确:通过将前景和背景特征分离并分别处理,模型能更好地识别伪装物体。
- 更高效:相比于一些依赖复杂注意力机制的方法,CamoFocus在保持高准确率的同时减少了计算资源的需求。
实验结果
- 在多个基准数据集(如CAMO、COD10K、CHAMELEON和NC4K)上的测试表明,CamoFocus在所有评估指标上都优于现有的最先进方法。
总结
CamoFocus是一种新颖且高效的伪装物体检测方法,通过特征分割和调制模块(FSM)以及上下文细化模块(CRM)的协同作用,显著提升了检测性能。这种方法在减少计算复杂度的同时,提供了更准确的检测结果,具有广泛的应用潜力。
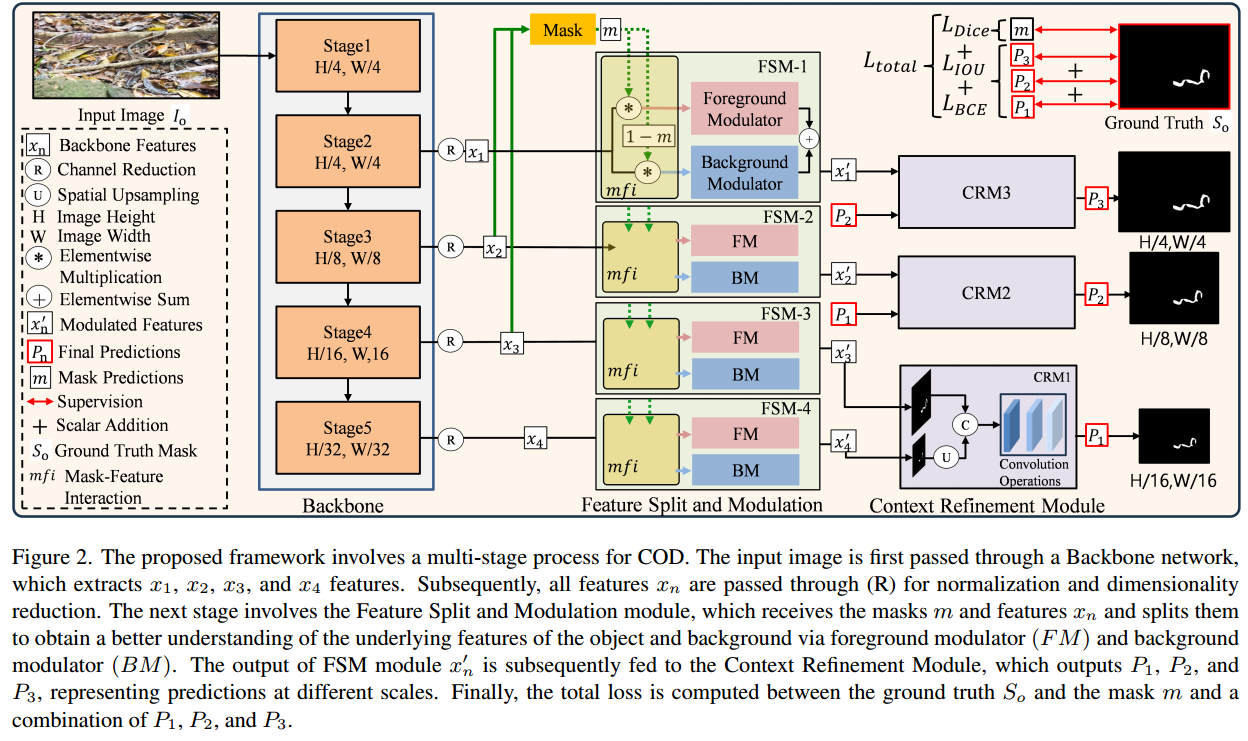
这张配图2展示了论文中CamoFocus模型的整体架构,包括各个模块和它们的相互作用。以下是对图中各个部分的详细解释:
输入和骨干网络
- Input Image I 0 I_0 I0: 输入图像。
- Backbone: 骨干网络,负责从输入图像中提取特征,包括五个阶段(Stage1到Stage5),每个阶段输出不同尺度的特征图:
- x 1 x_1 x1: 第一个阶段输出,空间尺寸为 H / 4 × W / 4 H/4 \times W/4 H/4×W/4。
- x 2 x_2 x2: 第二个阶段输出,空间尺寸为 H / 8 × W / 8 H/8 \times W/8 H/8×W/8。
- x 3 x_3 x3: 第三个阶段输出,空间尺寸为 H / 16 × W / 16 H/16 \times W/16 H/16×W/16。
- x 4 x_4 x4: 第四个阶段输出,空间尺寸为 H / 32 × W / 32 H/32 \times W/32 H/32×W/32。
这些特征图经过通道归一化和维度缩减操作(标记为 R R R)。
掩码生成
- Mask: 掩码 m m m 是通过融合 x 2 x_2 x2 和 x 3 x_3 x3 特征图生成的。掩码用于指导特征分割和调制模块中的前景和背景调制。
特征分割和调制模块(FSM)
- FSM-1到FSM-4: 特征分割和调制模块,通过前景调制器(FM)和背景调制器(BM)分别处理前景和背景特征:
- 前景调制器(FM): 处理前景特征,突出物体相关的激活。
- 背景调制器(BM): 处理背景特征,抑制物体相关的激活。
- m f i mfi mfi(Mask-Feature Interaction): 掩码特征交互,利用掩码 m m m 和 1 − m 1-m 1−m 分别乘以输入特征,生成前景特征 x f x_f xf 和背景特征 x b x_b xb。
每个FSM模块输出调制后的特征 x n ′ x'_n xn′,这些特征将被送入上下文细化模块进行进一步处理。
上下文细化模块(CRM)
- CRM1到CRM3: 上下文细化模块,接收来自FSM模块的调制特征,通过卷积操作进一步细化特征表示:
- 跨尺度操作:CRM模块接收不同尺度的输入特征,并通过双线性插值( U U U)和通道拼接( C C C)进行跨尺度特征处理。
- 卷积操作:每个CRM模块包含多个卷积层,用于提取更丰富的上下文信息。
预测和损失计算
- P 1 P_1 P1, P 2 P_2 P2, P 3 P_3 P3: 不同尺度的最终预测图。
- Supervision: 监督信号,包括掩码预测 m m m 和地面真实掩码 S 0 S_0 S0 的损失计算。
- 损失函数 L t o t a l L_{total} Ltotal: 总损失函数,包括加权二元交叉熵损失 L B C E L_{BCE} LBCE、加权IOU损失 L I O U L_{IOU} LIOU 和Dice损失 L d i c e L_{dice} Ldice。
处理流程总结
- 输入图像经过骨干网络提取多尺度特征。
- 生成掩码 m m m,并通过FSM模块分别调制前景和背景特征。
- 调制后的特征输入到CRM模块,进行跨尺度细化。
- 最终输出不同尺度的预测图 P 1 P_1 P1, P 2 P_2 P2, P 3 P_3 P3,并计算总损失 L t o t a l L_{total} Ltotal 进行监督学习。
这张图展示了CamoFocus模型如何通过多阶段处理、特征分割和上下文细化来提升伪装物体检测的性能。
3.2 Overall Architecture
这部分内容详细解释了CamoFocus模型的整体架构,包括骨干网络、特征分割和调制模块(FSM)以及上下文细化模块(CRM)的具体操作流程。下面是逐步解析:
总体架构
输入和特征提取
- 输入图像 I o ∈ R H × W × 3 I_o \in \mathbb{R}^{H \times W \times 3} Io∈RH×W×3:输入图像 I o I_o Io 的尺寸为 H × W × 3 H \times W \times 3 H×W×3。
- 骨干网络:骨干网络从输入图像中提取低层次和高层次特征,分为五个阶段:
- 第一个阶段(Stage 1):输出特征 x 0 x_0 x0 的空间尺寸为 H 4 × W 4 \frac{H}{4} \times \frac{W}{4} 4H×4W。由于这些特征包含的基本信息较少,不再进一步使用。
- 剩余阶段:提取低层到高层特征,分别为 x 1 , x 2 , x 3 , x 4 x_1, x_2, x_3, x_4 x1,x2,x3,x4,其空间尺寸分别为 H 4 × W 4 \frac{H}{4} \times \frac{W}{4} 4H×4W, H 8 × W 8 \frac{H}{8} \times \frac{W}{8} 8H×8W, H 16 × W 16 \frac{H}{16} \times \frac{W}{16} 16H×16W, H 32 × W 32 \frac{H}{32} \times \frac{W}{32} 32H×32W。这些特征经过通道归一化和ReLU激活。
掩码生成
- 掩码 m m m:掩码是通过融合 x 2 x_2 x2 和 x 3 x_3 x3 特征生成的。这个掩码用于指导后续的特征分割和调制。
特征分割和调制模块(FSM)
- 特征分割和调制模块(FSM-1到FSM-4):利用生成的掩码和骨干网络提取的特征,对前景和背景进行独立处理:
- 每个FSM模块输出处理后的特征图 x 1 ′ , x 2 ′ , x 3 ′ , x 4 ′ x'_1, x'_2, x'_3, x'_4 x1′,x2′,x3′,x4′。
上下文细化模块(CRM)
- 上下文细化模块(CRM-1到CRM-3):对FSM模块输出的特征图进行进一步细化,输出不同尺度的预测图 P 1 , P 2 , P 3 P_1, P_2, P_3 P1,P2,P3。
损失计算
- 总损失 L t o t a l L_{total} Ltotal:在所有阶段上计算累计损失,包括掩码预测 m m m 与GT 掩码 S o S_o So 之间的Dice损失 L d i c e L_{dice} Ldice,以及最终预测图 P 1 , P 2 , P 3 P_1, P_2, P_3 P1,P2,P3 与GT掩码 S o S_o So 之间的加权交叉熵损失 L B C E L_{BCE} LBCE 和加权IOU损失 L I O U L_{IOU} LIOU。
处理流程总结
- 输入图像经过骨干网络提取多尺度特征。
- 通过融合 x 2 x_2 x2 和 x 3 x_3 x3 生成掩码 m m m。
- 利用FSM模块分别处理前景和背景特征,输出调制后的特征图 x 1 ′ , x 2 ′ , x 3 ′ , x 4 ′ x'_1, x'_2, x'_3, x'_4 x1′,x2′,x3′,x4′。
- 调制后的特征图输入CRM模块进行跨尺度细化,输出最终预测图 P 1 , P 2 , P 3 P_1, P_2, P_3 P1,P2,P3。
- 计算总损失 L t o t a l L_{total} Ltotal,进行监督学习。
通过上述步骤,CamoFocus模型能够有效分离和调制前景与背景特征,增强了伪装物体检测的准确性和效率。
3.3 Mask Generation
为什么不直接使用Ground Truth作为掩码来分离前景和背景特征?
因为如果直接使用Ground Truth作为掩码来分离前景和背景特征,那就直接得到最完美最精确的结果了,后续各种操作各种模块没有意义了
掩码生成 (Mask Generation)
掩码生成部分负责从特定特征中提取信息密集且具有合理空间分辨率的掩码。具体步骤如下:
输入特征选择
- 输入特征
x
2
x_2
x2 和
x
3
x_3
x3:
- x 2 x_2 x2:来自骨干网络第二阶段的特征,具有较高的信息密度和适中的空间分辨率。
- x 3 x_3 x3:来自骨干网络第三阶段的特征,同样信息丰富且空间分辨率适中。
特征融合
- 空间均衡和拼接:
- 对 x 2 x_2 x2 和 x 3 x_3 x3 进行空间均衡操作,使它们在空间维度上具有相同的尺寸。
- 然后,将它们在通道维度上进行拼接,形成一个新的特征图。
卷积处理
- 两层卷积块:
- 第一个卷积块由一个3x3卷积层、L2归一化层和ReLU激活函数组成,其输出通道数等于 x 2 x_2 x2 和 x 3 x_3 x3 拼接后的通道总数。
- 第二个卷积块与第一个类似,但其输出通道数与第一个卷积块的输出通道数相同。
掩码生成
- Sigmoid激活:
- 经过两层卷积处理后的特征图,应用Sigmoid激活函数生成最终的掩码 m m m。
掩码应用
- 与骨干网络特征的交互:
- 生成的掩码 m m m 将与不同阶段的骨干网络特征 x n x_n xn 进行交互,通过 m f i mfi mfi 函数应用于特征分割和调制模块(FSM)。
具体操作步骤总结
- 提取特征:选择来自骨干网络第二和第三阶段的特征 x 2 x_2 x2 和 x 3 x_3 x3。
- 特征融合:通过空间均衡和通道拼接操作,结合 x 2 x_2 x2 和 x 3 x_3 x3 特征。
- 卷积处理:将融合后的特征通过两层卷积块处理,应用L2归一化和ReLU激活函数。
- 掩码生成:通过Sigmoid激活函数生成掩码 m m m。
- 应用掩码:将生成的掩码应用于骨干网络特征 x n x_n xn,用于指导特征分割和调制模块(FSM)的前景和背景调制。
详细解释
掩码生成过程的核心在于有效地融合来自不同尺度的信息密集特征,从而生成能够准确区分前景和背景的掩码。这一过程通过一系列卷积、归一化和激活操作,确保掩码具有高信息含量和准确性,最终提高了伪装物体检测的效果。
3.4 Feature Split and Modulation
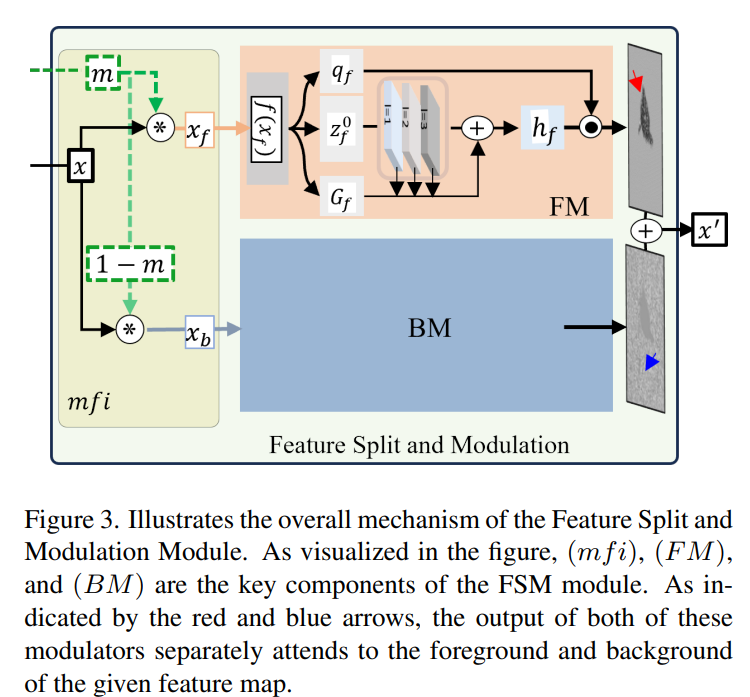
这张图展示了特征分割和调制模块(FSM)的整体机制,具体说明了如何通过前景调制器(FM)和背景调制器(BM)分别处理前景和背景特征。以下是对图中各个部分的详细解释:
图中各个部分解释
-
输入特征图 x x x:
- 输入特征图 x x x 来自骨干网络的某一阶段。
-
掩码生成和特征分割:
- 掩码 m m m:通过前文提到的掩码生成模块生成,用于指导前景和背景特征的分割。
- 前景特征
x
f
x_f
xf:将输入特征图
x
x
x 与掩码
m
m
m 进行元素乘积操作,得到前景特征。
x f = x ⊙ m x_f = x \odot m xf=x⊙m - 背景特征
x
b
x_b
xb:将输入特征图
x
x
x 与掩码的补集
1
−
m
1 - m
1−m 进行元素乘积操作,得到背景特征。
x b = x ⊙ ( 1 − m ) x_b = x \odot (1 - m) xb=x⊙(1−m)
-
前景调制器(FM):
- 特征投影:前景特征
x
f
x_f
xf 经过线性层投影得到
Z
f
0
Z_f^0
Zf0。
Z f 0 = f ( x f ) Z_f^0 = f(x_f) Zf0=f(xf) - 深度卷积处理:投影后的特征
Z
f
0
Z_f^0
Zf0 经过一系列深度卷积层处理,每层卷积层具有不同的感受野。
Z f l = ReLU ( DWConv ( Z f l − 1 ) ) Z_f^l = \text{ReLU}(\text{DWConv}(Z_f^{l-1})) Zfl=ReLU(DWConv(Zfl−1)) - 门控聚合:通过门控机制
G
f
G_f
Gf 聚合不同深度的特征。
Z out f = ∑ l = 1 L + 1 G l ⊙ Z f l Z_{\text{out}}^f = \sum_{l=1}^{L+1} G^l \odot Z_f^l Zoutf=l=1∑L+1Gl⊙Zfl - 最终输出:聚合后的特征通过前景调制 q f q_f qf 和特征合并 h f h_f hf 生成最终前景调制特征。
- 特征投影:前景特征
x
f
x_f
xf 经过线性层投影得到
Z
f
0
Z_f^0
Zf0。
-
背景调制器(BM):
- 特征投影:背景特征
x
b
x_b
xb 经过线性层投影得到
Z
b
0
Z_b^0
Zb0。
Z b 0 = f ( x b ) Z_b^0 = f(x_b) Zb0=f(xb) - 深度卷积处理:投影后的特征
Z
b
0
Z_b^0
Zb0 经过一系列深度卷积层处理。
Z b l = ReLU ( DWConv ( Z b l − 1 ) ) Z_b^l = \text{ReLU}(\text{DWConv}(Z_b^{l-1})) Zbl=ReLU(DWConv(Zbl−1)) - 门控聚合:通过门控机制
G
b
G_b
Gb 聚合不同深度的特征。
Z out b = ∑ l = 1 L + 1 G l ⊙ Z b l Z_{\text{out}}^b = \sum_{l=1}^{L+1} G^l \odot Z_b^l Zoutb=l=1∑L+1Gl⊙Zbl - 最终输出:聚合后的特征通过背景调制 q b q_b qb 和特征合并 h b h_b hb 生成最终背景调制特征。
- 特征投影:背景特征
x
b
x_b
xb 经过线性层投影得到
Z
b
0
Z_b^0
Zb0。
-
特征合并:
- 前景和背景特征在处理后进行元素相加,生成最终的调制特征图
x
′
x'
x′。
x ′ = Z out f + Z out b x' = Z_{\text{out}}^f + Z_{\text{out}}^b x′=Zoutf+Zoutb
- 前景和背景特征在处理后进行元素相加,生成最终的调制特征图
x
′
x'
x′。
主要功能总结
- 特征分割:通过掩码 m m m 将输入特征图 x x x 分割为前景特征 x f x_f xf 和背景特征 x b x_b xb。
- 特征调制:前景特征和背景特征分别经过前景调制器(FM)和背景调制器(BM)处理。
- 前景调制器(FM):处理前景特征,增强物体相关的激活。
- 背景调制器(BM):处理背景特征,抑制物体相关的激活。
- 特征合并:前景和背景特征在处理后进行合并,生成最终的调制特征图 x ′ x' x′。
通过这种方法,FSM模块能够更好地分离和处理前景和背景特征,从而提高伪装物体检测的准确性。
如果你有更多具体问题,或者需要进一步的解释,请告诉我!
在论文的Section 3.4 "Feature Split and Modulation"部分,作者详细描述了特征分割和调制模块(FSM)的具体设计和功能。以下是对该部分内容的详细解释:
特征分割和调制 (Feature Split and Modulation)
目的
为了更好地理解输入特征,并在复杂的背景中有效地分离物体,FSM模块基于焦点调制(Focal Modulation)方法,采用两个独立的调制器分别处理前景和背景特征。
具体步骤
-
输入特征和掩码交互
- 输入特征 x n x_n xn 与生成的掩码 m m m 进行元素乘积操作,分别得到前景特征 x f x_f xf 和背景特征 x b x_b xb。
- x f = x n ⊙ m x_f = x_n \odot m xf=xn⊙m
- x b = x n ⊙ ( 1 − m ) x_b = x_n \odot (1 - m) xb=xn⊙(1−m)
-
特征投影
- 前景特征
x
f
x_f
xf 和背景特征
x
b
x_b
xb 经过线性层投影,分别得到投影后的特征
Z
f
0
Z_f^0
Zf0 和
Z
b
0
Z_b^0
Zb0:
- Z f 0 = f ( x f ) ∈ R H × W × C Z_f^0 = f(x_f) \in \mathbb{R}^{H \times W \times C} Zf0=f(xf)∈RH×W×C
- Z b 0 = f ( x b ) ∈ R H × W × C Z_b^0 = f(x_b) \in \mathbb{R}^{H \times W \times C} Zb0=f(xb)∈RH×W×C
- 前景特征
x
f
x_f
xf 和背景特征
x
b
x_b
xb 经过线性层投影,分别得到投影后的特征
Z
f
0
Z_f^0
Zf0 和
Z
b
0
Z_b^0
Zb0:
-
深度卷积处理
- 投影后的特征
Z
f
0
Z_f^0
Zf0 和
Z
b
0
Z_b^0
Zb0 经过一系列的深度卷积层(DWConv),每一层都有不同的感受野,以便于更好地理解前景和背景的上下文信息:
- Z f l = ReLU ( DWConv ( Z f l − 1 ) ) Z_f^l = \text{ReLU}(\text{DWConv}(Z_f^{l-1})) Zfl=ReLU(DWConv(Zfl−1))
- Z b l = ReLU ( DWConv ( Z b l − 1 ) ) Z_b^l = \text{ReLU}(\text{DWConv}(Z_b^{l-1})) Zbl=ReLU(DWConv(Zbl−1))
- 投影后的特征
Z
f
0
Z_f^0
Zf0 和
Z
b
0
Z_b^0
Zb0 经过一系列的深度卷积层(DWConv),每一层都有不同的感受野,以便于更好地理解前景和背景的上下文信息:
-
特征聚合
- 在每一层卷积之后,前景和背景特征通过门控聚合机制(Gating Mechanism)进行特征聚合:
- 对于背景特征,门控聚合得到
G
b
G_b
Gb,聚合特征为:
- Z out b = ∑ l = 1 L + 1 G l ⊙ Z b l Z_{\text{out}}^b = \sum_{l=1}^{L+1} G^l \odot Z_b^l Zoutb=∑l=1L+1Gl⊙Zbl
- 对于前景特征,门控聚合得到
G
f
G_f
Gf,聚合特征为:
- Z out f = ∑ l = 1 L + 1 G l ⊙ Z f l Z_{\text{out}}^f = \sum_{l=1}^{L+1} G^l \odot Z_f^l Zoutf=∑l=1L+1Gl⊙Zfl
- 对于背景特征,门控聚合得到
G
b
G_b
Gb,聚合特征为:
- 在每一层卷积之后,前景和背景特征通过门控聚合机制(Gating Mechanism)进行特征聚合:
-
最终输出特征
- 将前景和背景特征聚合后,通过特征合并得到最终的调制特征图
x
n
′
x'_n
xn′:
- x n ′ = y f + y b x'_n = y_f + y_b xn′=yf+yb
- 将前景和背景特征聚合后,通过特征合并得到最终的调制特征图
x
n
′
x'_n
xn′:
主要功能总结
- 特征分割:通过掩码 m m m 将输入特征 x n x_n xn 分割成前景特征 x f x_f xf 和背景特征 x b x_b xb,使得模型能够分别处理前景和背景。
- 特征调制:分别处理前景和背景特征,通过深度卷积和门控聚合机制,增强特征的语义理解和上下文信息。
- 特征聚合:将处理后的前景和背景特征进行聚合,生成最终的调制特征图 x n ′ x'_n xn′。
图示解释
根据图2中的示意图,FSM模块包含前景调制器(FM)和背景调制器(BM),通过掩码 m m m 和特征图 x n x_n xn 的交互,实现特征的分割和调制,最终生成调制后的特征 x n ′ x'_n xn′。
通过这种方法,FSM模块能够更好地分离和处理前景和背景特征,提高伪装物体检测的准确性。
Section 3.5. Context Refinement Module
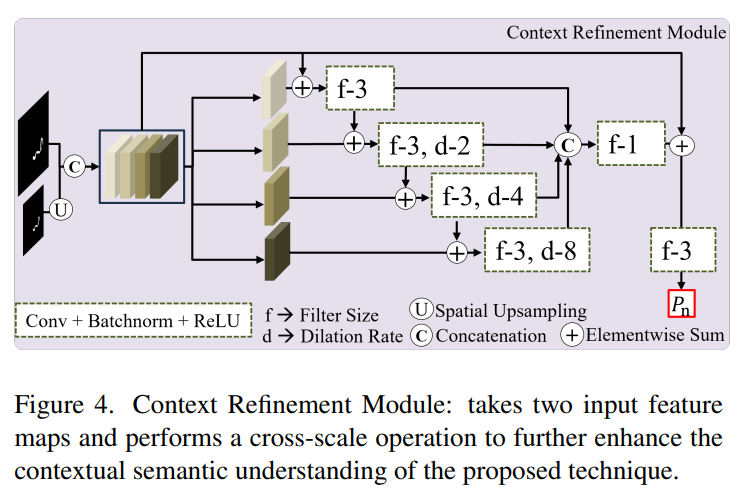
这张图展示了上下文细化模块(Context Refinement Module,CRM)的具体设计和操作流程。以下是对图中各个部分的详细解释:
上下文细化模块(CRM)的详细解释
输入特征
- 两个输入特征图:CRM接收两个输入特征图,一个是来自上一级的特征图,另一个是经过上采样后的特征图。
- 左侧特征图:直接来自上一级特征分割和调制模块(FSM)的输出特征。
- 下方特征图:经过双线性上采样(Spatial Upsampling,标记为 U U U)以匹配上一级特征图的空间尺寸。
空间对齐和通道拼接
- 通道拼接:通过通道拼接(Concatenation,标记为 C C C)操作,将这两个输入特征图在通道维度上拼接在一起,形成一个新的特征图。
卷积处理
- 卷积层:拼接后的特征图通过多个卷积层进行处理,每个卷积层具有不同的卷积核大小和膨胀率,以提取不同尺度的特征信息。
- 卷积层参数:
- f f f:卷积核大小。例如,图中显示了卷积核大小为3的卷积层。
- d d d:膨胀率(Dilation Rate)。例如,图中显示了膨胀率为2、4和8的卷积层。
- 卷积层参数:
跨尺度特征融合
- 跨尺度操作:
- 元素和:卷积处理后的特征图通过元素和操作(Elementwise Sum,标记为 + + +)进行融合,以结合不同尺度的特征信息。
- 跳跃连接:卷积层之间通过跳跃连接(Skip Connections)保持特征图的语义关系。
输出预测图
- 最终卷积层:经过多个卷积层和跨尺度融合后的特征图,最终通过一个卷积核大小为1的卷积层,生成最终的预测图
P
n
P_n
Pn。
- 预测图 P n P_n Pn:表示在不同尺度下的伪装物体检测结果,用于与地面真实掩码 S o S_o So 进行比较,计算损失并用于监督学习。
主要功能总结
- 跨尺度特征处理:CRM通过处理不同尺度的输入特征,增强了特征表示的多尺度语义信息。
- 语义增强:通过卷积操作和跳跃连接,保持和增强了不同尺度特征之间的语义关系。
- 监督学习:生成的预测图 P n P_n Pn 用于与地面真实掩码 S o S_o So 进行比较,计算损失,指导模型训练。
图示解释
- 输入:两个输入特征图,一个来自上一级,一个经过上采样。
- 空间对齐:通过上采样对齐不同尺度特征的空间尺寸。
- 通道拼接:在通道维度上拼接对齐后的特征图。
- 卷积处理:通过多个卷积层提取不同尺度的信息,卷积核大小和膨胀率不同。
- 跨尺度融合:通过元素和操作和跳跃连接,实现不同尺度特征的融合。
- 输出:最终通过卷积层生成预测图 P n P_n Pn。
通过这种方法,CRM模块能够有效提取和增强跨尺度语义信息,提高伪装物体检测的准确性。
在论文的Section 3.5 "Context Refinement Module"部分,作者详细描述了上下文细化模块(CRM)的设计和功能。以下是对该部分内容的详细解释:
上下文细化模块 (Context Refinement Module)
目的
上下文细化模块(CRM)旨在进一步提取和增强由特征分割和调制模块(FSM)生成的特征中的跨尺度语义信息。通过处理不同尺度的输入特征,CRM能够提高特征表示的质量,从而更准确地检测伪装物体。
具体步骤
-
输入特征
- CRM模块接收来自不同阶段的特征,例如,接收从FSM模块输出的调制特征 x n ′ x'_n xn′ 和其后一个阶段的特征 x n + 1 ′ x'_{n+1} xn+1′。
-
空间对齐
- 通过双线性上采样(Bilinear Upsampling)将较小尺度的特征 x n + 1 ′ x'_{n+1} xn+1′ 上采样至与较大尺度的特征 x n ′ x'_n xn′ 相同的空间尺寸: x n + 1 ′ = Upsample ( x n + 1 ′ ) x'_{n+1} = \text{Upsample}(x'_{n+1}) xn+1′=Upsample(xn+1′)
-
通道拼接
- 将上采样后的特征
x
n
+
1
′
x'_{n+1}
xn+1′ 与特征
x
n
′
x'_n
xn′ 在通道维度上进行拼接(Concatenation),形成一个新的特征图:
x concat = Concat ( x n ′ , x n + 1 ′ ) x_{\text{concat}} = \text{Concat}(x'_n,x'_{n+1}) xconcat=Concat(xn′,xn+1′)
- 将上采样后的特征
x
n
+
1
′
x'_{n+1}
xn+1′ 与特征
x
n
′
x'_n
xn′ 在通道维度上进行拼接(Concatenation),形成一个新的特征图:
-
卷积处理
- 拼接后的特征图
x
concat
x_{\text{concat}}
xconcat 经过一系列卷积操作,这些卷积层具有不同的卷积核大小和膨胀率,以便从特征中提取不同尺度的信息:
- 每个卷积层之后,应用ReLU激活函数和L2归一化。
- 例如,使用6个卷积层,每个卷积层的卷积核大小(f)和膨胀率(d)可能不同,以处理特征中的多尺度信息。
- 拼接后的特征图
x
concat
x_{\text{concat}}
xconcat 经过一系列卷积操作,这些卷积层具有不同的卷积核大小和膨胀率,以便从特征中提取不同尺度的信息:
-
跨尺度交互
- CRM模块通过对不同尺度特征的交互处理,进一步增强特征的语义理解。
- 跨尺度操作通过卷积层和跳跃连接实现,跳跃连接用于保持不同尺度特征之间的语义关系,增强特征表示的质量。
-
预测输出
- 每个CRM模块生成一个预测图 P n P_n Pn,用于表示在不同尺度下的伪装物体检测结果。
- CRM模块中的最终预测图 P n P_n Pn 与地面真实掩码 S o S_o So 进行比较,计算损失并用于监督学习。
具体操作总结
- 输入特征:接收来自FSM模块的调制特征 x n ′ x'_n xn′ 和其后一个阶段的特征 x n + 1 ′ x'_{n+1} xn+1′。
- 空间对齐:通过上采样对齐不同尺度特征的空间尺寸。
- 通道拼接:在通道维度上拼接对齐后的特征。
- 卷积处理:通过一系列卷积操作,提取不同尺度的信息。
- 跨尺度交互:通过卷积层和跳跃连接增强特征的语义理解。
- 预测输出:生成不同尺度的预测图 P n P_n Pn,用于伪装物体检测。
主要功能总结
- 跨尺度特征处理:CRM模块通过处理不同尺度的输入特征,增强了特征表示的多尺度语义信息。
- 上下文语义增强:通过卷积操作和跳跃连接,保持和增强了不同尺度特征之间的语义关系。
- 监督学习:生成的预测图 P n P_n Pn 用于与地面真实掩码 S o S_o So 进行比较,计算损失,指导模型训练。
图示解释
根据图2中的示意图,CRM模块接收来自不同尺度的特征,通过上采样、拼接、卷积处理和跨尺度交互,最终生成预测图 P 1 , P 2 , P 3 P_1, P_2, P_3 P1,P2,P3。
通过这种方法,CRM模块能够有效提取和增强跨尺度语义信息,提高伪装物体检测的准确性。
Section 3.6. Loss Function
在论文的Section 3.6 "Loss Function"部分,作者详细描述了用于监督CamoFocus模型训练的损失函数设计。以下是该部分内容的详细解释:
损失函数 (Loss Function)
目的
设计合理的损失函数是为了指导模型在训练过程中更有效地学习,从而提高伪装物体检测的准确性。在CamoFocus模型中,作者采用了加权交叉熵损失(Weighted Binary Cross-Entropy Loss, L B C E L_{BCE} LBCE)、加权交并比损失(Weighted Intersection Over Union Loss, L I O U L_{IOU} LIOU)和Dice损失(Dice Loss, L D i c e L_{Dice} LDice)的组合来监督模型的学习。
具体损失函数
-
加权交叉熵损失 ( L B C E L_{BCE} LBCE)
- 作用:加权交叉熵损失在图像分割任务中常用于像素级分类。通过为不同类别的像素赋予不同的权重,能够更好地处理类别不平衡问题。
- 公式:
L B C E = − ∑ i = 1 N w i [ y i log ( p i ) + ( 1 − y i ) log ( 1 − p i ) ] L_{BCE} = -\sum_{i=1}^N w_i \left[y_i \log(p_i) + (1 - y_i) \log(1 - p_i)\right] LBCE=−i=1∑Nwi[yilog(pi)+(1−yi)log(1−pi)]其中, w i w_i wi 是像素 i i i 的权重, y i y_i yi 是真实标签, p i p_i pi 是预测概率。
-
加权交并比损失 ( L I O U L_{IOU} LIOU)
- 作用:交并比损失用于衡量预测分割结果与真实分割结果之间的重叠程度,适用于维护预测图与真实图的结构一致性。
- 公式:
L I O U = 1 − ∑ i = 1 N w i ⋅ y i ⋅ p i ∑ i = 1 N w i ⋅ ( y i + p i − y i ⋅ p i ) L_{IOU} = 1 - \frac{\sum_{i=1}^N w_i \cdot y_i \cdot p_i}{\sum_{i=1}^N w_i \cdot (y_i + p_i - y_i \cdot p_i)} LIOU=1−∑i=1Nwi⋅(yi+pi−yi⋅pi)∑i=1Nwi⋅yi⋅pi
其中,分子表示预测与真实之间的交集,分母表示二者的并集, w i w_i wi 是权重。
-
Dice损失 ( L D i c e L_{Dice} LDice)
- 作用:Dice损失常用于分割任务,尤其是在处理样本类别不平衡问题时效果显著。Dice损失通过计算预测与真实标签的重叠度,优化分割效果。
- 公式:
L D i c e = 1 − 2 ∑ i = 1 N y i ⋅ p i ∑ i = 1 N y i + ∑ i = 1 N p i L_{Dice} = 1 - \frac{2 \sum_{i=1}^N y_i \cdot p_i}{\sum_{i=1}^N y_i + \sum_{i=1}^N p_i} LDice=1−∑i=1Nyi+∑i=1Npi2∑i=1Nyi⋅pi
其中,分子是预测与真实标签的两倍交集,分母是预测与真实标签的总和。
总损失函数
- 累计损失 (
L
t
o
t
a
l
L_{total}
Ltotal):总损失函数结合了加权交叉熵损失、加权交并比损失和Dice损失,通过在不同阶段的监督信号,指导模型在训练过程中优化伪装物体检测性能。
- 公式:
L t o t a l = ∑ i = 1 3 ( L B C E ( P i , S o ) + L I O U ( P i , S o ) ) + L D i c e ( m , S o ) L_{total} = \sum_{i=1}^3 \left(L_{BCE}(P_i, S_o) + L_{IOU}(P_i, S_o)\right) + L_{Dice}(m, S_o) Ltotal=i=1∑3(LBCE(Pi,So)+LIOU(Pi,So))+LDice(m,So)其中, P i P_i Pi 是不同尺度的预测图, S o S_o So 是地面真实掩码, m m m 是生成的掩码。
- 公式:
损失函数的设计意图
- 多尺度监督:通过在不同尺度( P 1 , P 2 , P 3 P_1, P_2, P_3 P1,P2,P3)上计算损失,确保模型在各个尺度上都能够准确检测伪装物体。
- 类别不平衡处理:加权交叉熵和加权交并比损失通过赋予不同类别像素不同的权重,处理类别不平衡问题。
- 结构一致性:交并比损失和Dice损失通过强调预测图与真实图的结构一致性,优化模型的分割效果。
总结
在Section 3.6中,作者通过结合加权交叉熵损失、加权交并比损失和Dice损失,设计了一个综合的损失函数 L t o t a l L_{total} Ltotal,用于指导CamoFocus模型在训练过程中优化伪装物体检测性能。这个综合损失函数能够处理类别不平衡问题,确保多尺度监督,并维护预测图与真实图的结构一致性。
实验实现细节
在论文的Section 4.1 "Training Settings and Reproducibility"部分,作者详细描述了CamoFocus模型的训练设置和可重复性。以下是该部分内容的详细解释:
训练设置和可重复性 (Training Settings and Reproducibility)
训练框架和工具
- 实现框架:CamoFocus模型的实现使用了PyTorch深度学习库。
- 预训练模型:骨干网络使用在ImageNet数据库上预训练的PVTv2(Pyramid Vision Transformer v2)。
数据处理
- 图像大小:所有输入图像都被调整为416x416的大小。
- 数据增强:在训练过程中可能使用了数据增强技术(文中未明确提及,但通常包括随机裁剪、翻转、旋转等)。
训练超参数
- 优化器:使用Adam优化器,初始学习率设置为1e-4。
- 训练周期:模型的训练周期为90个epoch。
- 批量大小:在整个实验过程中,批量大小设置为24。
- 学习率调度:采用“poly”学习率调度策略,这种策略随着训练的进行逐渐减少学习率,有助于模型更好地收敛。
防止过拟合
- 学习率调度器:通过逐渐减少学习率的方法(poly策略),防止模型在训练过程中过拟合,并提高模型的收敛性。
训练环境
- 硬件配置:训练在双NVIDIA A100 GPU(每个40G显存)上进行。
- 训练时间:根据超参数选择的不同,单个模型的完整训练时间记录在2到3小时之间。
骨干网络对比
- 其他骨干网络:除了PVTv2,作者还使用了其他骨干网络进行实验,包括Res2Net和EfficientNet-B1,以确保与SOTA(State Of The Art)技术的公平比较。
主要内容总结
- 实现框架和工具:使用PyTorch深度学习库实现模型,采用在ImageNet上预训练的PVTv2作为骨干网络。
- 数据处理和增强:所有输入图像调整为416x416大小,可能进行了数据增强处理。
- 训练超参数:使用Adam优化器,初始学习率为1e-4,训练90个epoch,批量大小为24。
- 防止过拟合:采用“poly”学习率调度策略,逐渐减少学习率以防止过拟合。
- 训练环境:在双NVIDIA A100 GPU上训练,单个模型训练时间为2到3小时。
- 骨干网络对比:除了PVTv2,还使用了Res2Net和EfficientNet-B1进行实验,以确保与其他SOTA技术的公平比较。
可重复性
为了确保实验结果的可重复性,论文中详细描述了训练设置和超参数。这些信息使得其他研究人员能够在相同或相似的环境中复现实验结果,并进行进一步研究。
通过这些详细的训练设置和实验条件,作者展示了CamoFocus模型在不同条件下的性能,并确保了实验结果的可靠性和可重复性。















 1139
1139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









