







 该文介绍了一个使用BERT进行命名实体识别的任务,包括数据集格式、样本构造、模型创建和训练过程。数据集由token_data.txt和label_data.txt构成,标签包括疾病、症状、检查等。首先,通过Sequence_Labeling_Processor处理数据,然后转化为InputExample,再将其转换为适合模型的InputFeatures。模型创建中,利用BERT的预训练模型,添加额外的网络层进行分类,并定义损失函数。最后,对模型进行训练和评估。
该文介绍了一个使用BERT进行命名实体识别的任务,包括数据集格式、样本构造、模型创建和训练过程。数据集由token_data.txt和label_data.txt构成,标签包括疾病、症状、检查等。首先,通过Sequence_Labeling_Processor处理数据,然后转化为InputExample,再将其转换为适合模型的InputFeatures。模型创建中,利用BERT的预训练模型,添加额外的网络层进行分类,并定义损失函数。最后,对模型进行训练和评估。
基于BERT的命名实体识别
目标任务
针对提供的数据进行命名实体识别,标注出每个token对应的label。
其中label包括
BIO_token_labels = ['TREATMENT-I', 'TREATMENT-B', 'BODY-B', 'BODY-I','SIGNS-I', 'SIGNS-B',\
'CHECK-B', 'CHECK-I', 'DISEASE-I', 'DISEASE-B', 'O', '[CLS]', '[SEP]','[Padding]']
数据集格式
训练集分为两个文件,格式如下:
token_data.txt
左 膝 摔 伤 后 疼 痛 约 2 小 时 入 院 。
label_data.txt
BODY-B BODY-I O O O SIGNS-B SIGNS-I O O O O O O O
构造训练样本
仿照DataProcessor定义Sequence_Labeling_Processor,对其中的函数进行修改,将数据转换为规定格式。
get_examples
def get_examples(self, data_dir): # 获取数据集的token和label
with open(os.path.join(data_dir, "token_data.txt"), encoding='utf-8') as token_data_f:
with open(os.path.join(data_dir, "label_data.txt"), encoding='utf-8') as label_data_f:
token_list = [seq.replace("\n", '') for seq in token_data_f.readlines()]
token_label_list = [seq.replace("\n", '') for seq in label_data_f.readlines()]
assert len(token_list) == len(token_label_list)
examples = list(zip(token_list, token_label_list))
return examples
InputExample
class InputExample(object): # 构建一个输入样本
"""A single training/test example for simple sequence classification."""
def __init__(self, guid, text_token, token_label):
self.guid = guid # 编号 如train-1
self.text_token = text_token # 一组token列表
self.token_label = token_label # token对应的标签列表
_create_example
def _create_example(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
# guid = train-1/train-2...
guid = "%s-%s" % (set_type, i)
if set_type == "test":
text_token = line
token_label = None
else:
text_token = line[0]
token_label = line[1]
examples.append(
InputExample(guid=guid, text_token=text_token, token_label=token_label))
return examples
get_train_examples
def get_train_examples(self, data_dir): # 构建训练样本集
return self._create_example(self.get_examples(os.path.join(data_dir, "train")), "train")
测试集、验证集构造与此类似。
将token和label转为id并结构化
convert_single_example
将token和label转换为id,结构化到InputFeature对象。
def convert_single_example(ex_index, example, token_label_list, max_seq_length,
tokenizer):
"""Converts a single `InputExample` into a single `InputFeatures`."""
token_label_map = {}
for (i, label) in enumerate(token_label_list):
# 建立标签字典
token_label_map[label] = i
text_token = example.text_token.split("\t")[0].split(" ")
# text_token:['入', '院', '后', '完', '善', '相', '关', '辅', '助', '检', '查', ',', '给', '予',
# '静', '点','抗', '生', '素', ',', '患', '处', '外', '敷', '。', '休', '息', '。']
if example.token_label is not None:
token_label = example.token_label.split("\t")[0].split(" ")
else:
token_label = ["O"] * len(text_token)
# token_label:['O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O',
# 'TREATMENT-B', 'TREATMENT-I', 'TREATMENT-I', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']
assert len(text_token) == len(token_label)
if len(text_token) >= max_seq_length - 1:
text_token = text_token[0:(max_seq_length - 2)]
token_label = token_label[0:(max_seq_length - 2)]
tokens = []
token_label_ids = []
segment_ids = []
# 句首添加[CLS]
tokens.append("[CLS]")
segment_ids.append(0)
token_label_ids.append(token_label_map['[CLS]'])
for token in text_token:
tokens.append(token)
segment_ids.append(0)
for label in token_label:
token_label_ids.append(token_label_map[label])
# 句尾添加[SEP]
tokens.append("[SEP]")
segment_ids.append(0)
token_label_ids.append(token_label_map['[SEP]'])
input_ids = tokenizer.convert_tokens_to_ids(tokens)
# The mask has 1 for real tokens and 0 for padding tokens. Only real
# tokens are attended to.
input_mask = [1] * len(input_ids)
# 填充至max_seq_length
while len(input_ids) < max_seq_length:
input_ids.append(0)
input_mask.append(0) # 填充标志
segment_ids.append(0)
token_label_ids.append(token_label_map['[Padding]'])
tokens.append("[Padding]")
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
assert len(token_label_ids) == max_seq_length
if ex_index < 5:
tf.logging.info("*** Example ***")
tf.logging.info("guid: %s" % (example.guid))
tf.logging.info("tokens: %s" % " ".join(
[tokenization.printable_text(x) for x in tokens]))
tf.logging.info("input_ids: %s" % " ".join([str(x) for x in input_ids]))
tf.logging.info("input_mask: %s" % " ".join([str(x) for x in input_mask]))
tf.logging.info("segment_ids: %s" % " ".join([str(x) for x in segment_ids]))
tf.logging.info("token_label_ids: %s" % " ".join([str(x) for x in token_label_ids]))
feature = InputFeatures(
input_ids=input_ids,
input_mask=input_mask,
segment_ids=segment_ids,
label_ids=token_label_ids)
return feature
建立分类模型
create_model是微调过程中的核心函数,网络层的添加、损失函数的定义都在其中。
create_model
def create_model(bert_config, is_training, input_ids, input_mask, segment_ids,label_ids,
num_token_labels, use_one_hot_embeddings):
"""Creates a classification model."""
# 加载BERT预训练模型
model = modeling.BertModel(
config=bert_config,
is_training=is_training,
input_ids=input_ids,
input_mask=input_mask,
token_type_ids=segment_ids,
use_one_hot_embeddings=use_one_hot_embeddings)
# 获取token级编码 shape = [batch_size, length, 768]
# 若要获取句子级编码 使用get_pooled_output函数
token_label_output_layer = model.get_sequence_output()
# 可在之后添加BiLSTM+CRF等网络层 token_label_output_layer即为输入
# token_label_hidden_size 768
token_label_hidden_size = token_label_output_layer.shape[-1].value
token_label_output_weight = tf.get_variable(
"token_label_output_weights", [num_token_labels, token_label_hidden_size],
initializer=tf.truncated_normal_initializer(stddev=0.02)
)
token_label_output_bias = tf.get_variable(
"token_label_output_bias", [num_token_labels], initializer=tf.zeros_initializer()
)
with tf.variable_scope("token_label_loss"):
if is_training:
token_label_output_layer = tf.nn.dropout(token_label_output_layer, keep_prob=0.9)
token_label_output_layer = tf.reshape(token_label_output_layer, [-1, token_label_hidden_size])
token_label_logits = tf.matmul(token_label_output_layer, token_label_output_weight, transpose_b=True)
token_label_logits = tf.nn.bias_add(token_label_logits, token_label_output_bias)
token_label_logits = tf.reshape(token_label_logits, [-1, FLAGS.max_seq_length, num_token_labels])
token_label_log_probs = tf.nn.log_softmax(token_label_logits, axis=-1)
token_label_one_hot_labels = tf.one_hot(label_ids, depth=num_token_labels, dtype=tf.float32)
token_label_per_example_loss = -tf.reduce_sum(token_label_one_hot_labels * token_label_log_probs, axis=-1)
token_label_loss = tf.reduce_sum(token_label_per_example_loss)
token_label_probabilities = tf.nn.softmax(token_label_logits, axis=-1)
token_label_predictions = tf.argmax(token_label_probabilities, axis=-1)
loss = token_label_loss
return (loss, token_label_per_example_loss, token_label_logits, token_label_predictions)
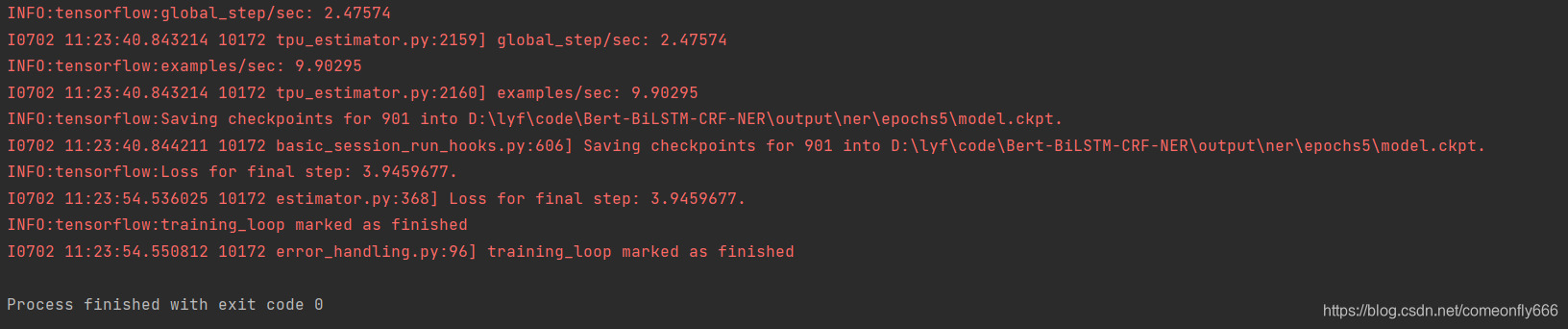
训练模型
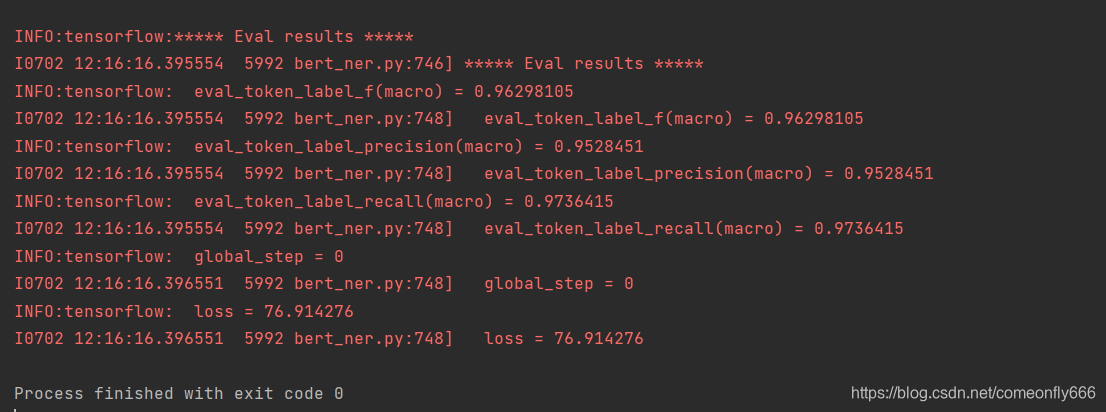
评估模型

















 3324
3324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









