






1 列子见笔记本TEST\save\init_.py
.meta文件保存了当前图结构
.index文件保存了当前参数名
.data文件保存了当前参数值
2 Segnet(https://blog.csdn.net/tuzixini/article/details/78760158)
核心的可训练的分割引擎包含一个编码网络,和一个对应的解码网络,并跟随着一个像素级别的分类层.编码器网络的架构在拓扑上与VGG16网络中的13个卷积层相同.解码网络的角色是映射低分辨率的编码后的特征图到输入分辨率的特征图.具体地,解码器使用在相应编码器的最大合并步骤中计算的池化索引来执行非线性上采样.这消除了上采样的学习需要.上采样后的图是稀疏的,然后与可训练的滤波器卷积以产生密集的特征图.(翻译了一片论文:https://blog.csdn.net/u014451076/article/details/70741629)
2.1 改进 1:SegNet中的编码网络和VGG16的卷积层是拓扑上相同的.我们移除了全连接层
2:.SegNet的关键部件是解码器网络,解码网络与VGG16的13层卷积层相同。解码网络是将低分辨率的编码特征图映射到全分辨率的特征图。解码网络使用最大池化层的池化索引进行非线性上采样,上采样过程就不需要学习。上采样得到的稀疏图与可训练的滤波器卷积得到致密的特征图。使用池化层索引进行上采样的优势:1)提升边缘刻画度;2)减少训练的参数;3)这种上采样模式可以包含到任何编码-解码网络中。

感觉其实和FCN思路十分相似,只是Encoder,Decoder(Upsampling)使用的技术不一致.此外SegNet的编码器部分使用的是VGG16的前13层卷积网络,每个编码器层都对应一个解码器层,最终解码器的输出被送入soft-max分类器以独立的为每个像素产生类概率.
每个编码器由数个蓝色层(卷积层,批归一化层,RELU层)以及一个Pooling层(2x2窗口,步进2,最大池化)组成,输出相当于系数为2的下采样.由于最大池化和子采样的叠加,导致边界细节损失增大,因此必须在编码特征图中在sub-sampling之前捕获和储存边界信息.为了高效,文中只储存了max-pooling indices.
2.2 与FCN比较:FCN仅仅复制了编码器的特征,而Segnet复制了最大池化指数,这使得在内存上比FCN更为高效。
SegNet和FCN最大的不同就在于decoder的upsampling方法,上图结构中,注意,前面encoder每一个pooling层都把pooling indices保存,并且传递到后面对称的upsampling层. 进行upsampling的过程具体如下:
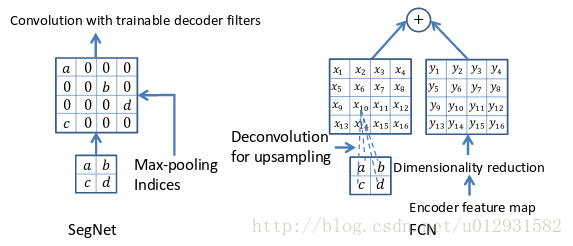
左边是SegNet的upsampling过程,就是把feature map的值 abcd, 通过之前保存的max-pooling的坐标映射到新的feature map中,其他的位置置零.
右边是FCN的upsampling过程,就是把feature map, abcd进行一个反卷积,得到的新的feature map和之前对应的encoder feature map 相加.
3 代码的实现:见Segnet,数据集是voc2012,数据集介绍来源:
https://blog.csdn.net/zhangjunbob/article/details/52769381,)
3.1voc2012数据集的介绍:
1.JPEGImages
文件夹中包含了PASCAL VOC所提供的所有的图片信息,包括了训练图片和测试图片。这些图像都是以“年份_编号.jpg”格式命名的。图片的像素尺寸大小不一,但是横向图的尺寸大约在500*375左右,纵向图的尺寸大约在375*500左右,基本不会偏差超过100。
2 Annotations
文件夹中存放的是xml格式的标签文件,每一个xml文件都对应于JPEGImages文件夹中的一张图片。
3 ImageSets
存放的是每一种类型的challenge对应的图像数据。由以下四个文件组成

Action下存放的是人的动作(例如running、jumping等等,这也是VOC challenge的一部分)

前面的表示图像的name,后面的1代表正样本,-1代表负样本。
4 SegmentationClass:标注出每一个像素的类别
5 SegmentationObject:标注出每一个像素属于哪一个物体















 433
433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









