






- 编码,就是将输入序列转化成一个固定长度向量。
- 解码,就是将之前生成的固定长度向量再转化出输出序列。
编码器-解码器有 2 点需要注意:
- 不管输入序列和输出序列长度是多少,中间的向量长度都是固定的。
- 不同的任务可以选择不同的编码器和解码器 (如RNN,CNN,LSTM,GRU)。
1 序列到序列模型(Seq2Seq)
Encoder-Decoder 有一个比较显著的特征就是它是一个 End-to-End 的学习算法,以机器翻译为例,将英语翻译成汉语这样的模型叫做 Seq2Seq。
什么是端到端 End-to-End 的学习?
端到端的学习其实就是不做其他任何额外的处理,直接从原始数据输入到任务结果输出,整个训练和预测过程,都是在模型里完成的。参考NLP基础之sequence2sequence
- 比如:我们想磨豆浆,那么普通料理机就不是端到端的(因为料理机的输入是洗干净且浸泡过的黄豆,料理机的输出是生豆浆。用这样的料理机磨豆浆,我们需要实现自行清洗、浸泡黄豆,事后我们还要自己煮豆浆(喝生豆浆很可能导致食物中毒))相反,如果我们有一个端到端的豆浆机,就可以直接把黄豆和水(原始数据)放进去,最后得到的是可以直接喝的热豆浆(结果)
Seq2Seq 工作原理:
Seq2Seq ( Sequence-to-Sequence),是指输入一个序列,Seq2Seq 模型生成模型的编码表示,然后将其传递给解码器输出另一个序列。这种结构最重要的地方在于输入序列和输出序列的长度是可变的。
Seq2Seq 原理图:参考Seq2Seq
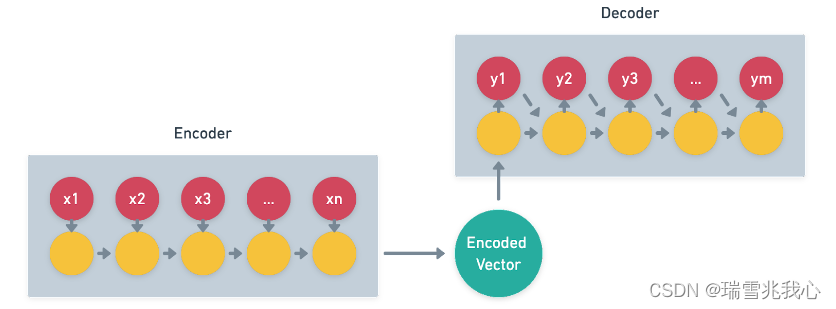
以简单的RNN为例,编码器中的隐藏状态计算公式:参考Seq2Seq更详细的解析
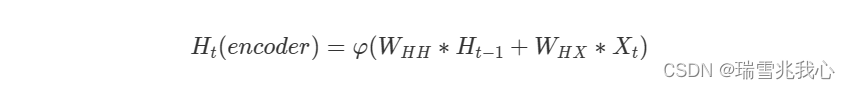
- H(t)(encoder):表示编码器中的隐藏状态
:表示激活函数
- X(t):表示当前时刻输入的信息
- H(t-1):表示上一时刻的隐藏状态
- W(HH):表示连接隐藏状态的权重矩阵
- W(HX):表示连接输入和隐藏状态的权重矩阵
解码器中的隐藏状态计算公式:
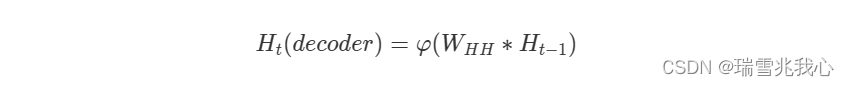
- H(t)(decoder):表示解码器中的隐藏状态
- W(HH):表示连接隐藏状态的权重矩阵
- H(t-1):表示上一时刻的隐藏状态
解码器生成的输出计算公式:
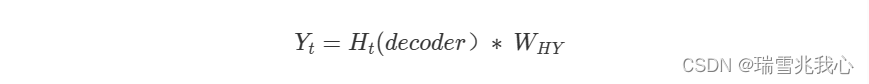
H(t)(decoder):表示解码器中的隐藏状态
W(HY):表示将隐藏状态与解码器输出连接起来的权重矩阵
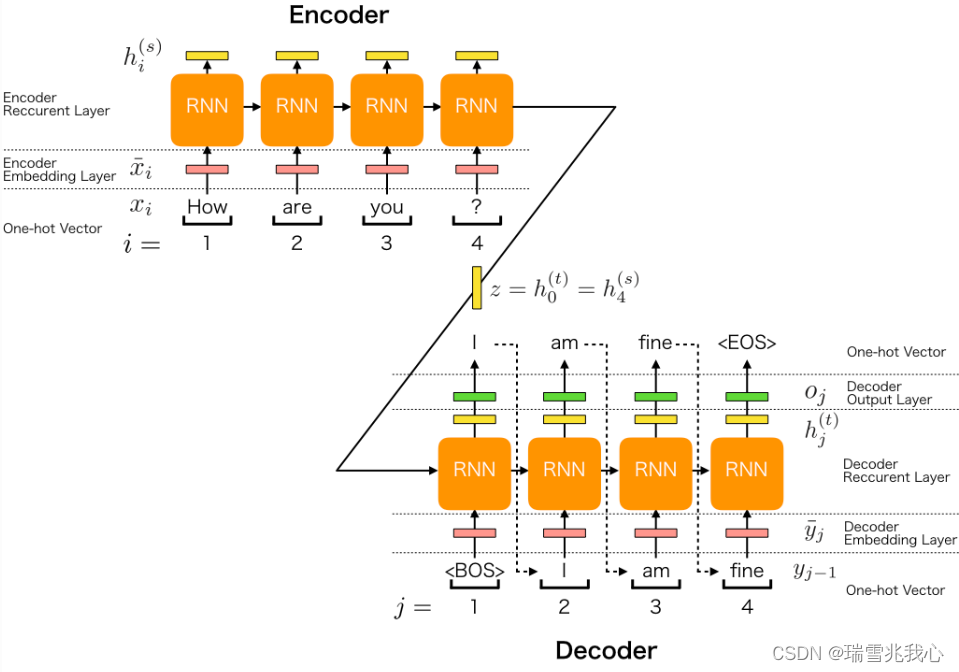
2 结合RNN循环神经网络的序列到序列Seq2Seq模型
Seq2seq(结合 RNN)的模型架构可以分为五大角色:
编码器嵌入层:将输入句子每个单词的 One-Hot独热编码向量转换为嵌入向量。
编码器循环层:将输入句子每个单词的嵌入向量生成隐藏向量。
解码器嵌入层:将输出句子中的每个单词的 One-Hot 独热编码向量转换为嵌入向量。
解码器循环层:将输出句子每个单词的嵌入向量生成隐藏向量。
解码器输出层:将隐藏向量生成的输出句子转换成 One-Hot 独热编码向量的概率
编码器由两层组成:嵌入层和循环层; 解码器由三层组成:嵌入层、循环层和 输出层。















 1174
1174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











