






在很多场景中需要对多变量数据进行观测,在一定程度上增加了数据采集的工作量。更重要的是:多变量之间可能存在相关性,从而增加了问题分析的复杂性。
主成分分析(Principal Components Analysis, PCA)是一种使用最广泛的数据降维算法(非监督的机器学习方法)。旨在降低数据的维数,通过保留数据集中的主要成分来简化数据集(选取出更便于人类理解的特征)。
主成分分析的主要思想:
将 n 维特征映射到 k 维上,这 k 维是全新的正交特征(称为主成分),是在原有 n 维特征的基础上重新构造出来的 k 维特征。参考主成分分析法(PCA)思想及原理
1 方差
方差(Variance)分为总体方差(Population Variance)和样本方差(Sample Variance)。
Q1:什么是总体?什么是样本?
- 总体,即大同小异的对象的全体,例如中国的所有成年人,某所小学的全体学生;
- 样本,即通过抽样,从研究总体中抽取的少量有代表性的个体所组成的集合。
总体方差的计算公式:
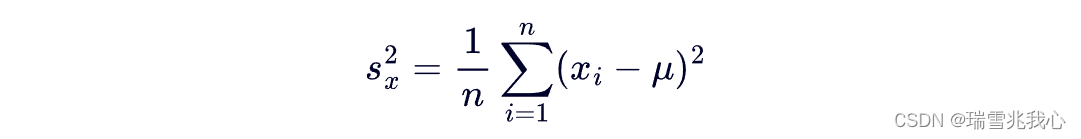
样本方差的计算公式:
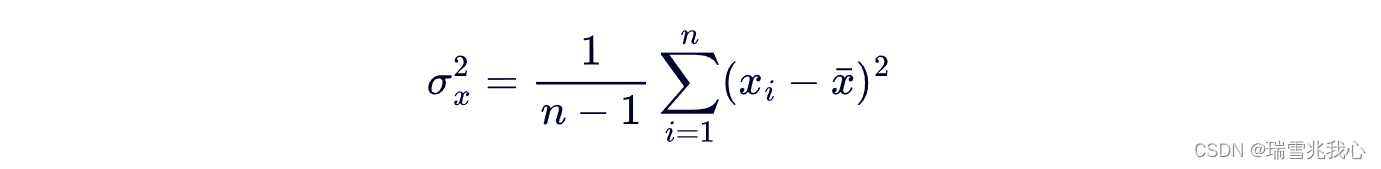
Q2:方差是怎么来的?
统计学中重要的概念:
- 总体中个体的特性总是通过一个或多个数量来描述,这些用于描述个体属性的指标就称为变量(Variable)(例如,身高、体重、性别、年龄、职业等)。变量又分为定量变量(例如,年龄:35岁)和定性变量(例如,年龄类别:18-35岁)
- 一个总体中有许多个体,他们之所以成为研究对象,必定存在共性(比如性别、年龄、职业等属性),这些共性即称为同质性(Homogeneity)。从统计学角度看,同质性指方差同质性(equality of variance),即不同变量或群组之间分散的程度要一样或接近,这样的数据才具有可计算和可比性。
- 然而,同一总体内的个体也会存在差异,这是绝对存在的,这些差异就是我们强调的变异(Variation)。
- 集中趋势(Central Tendency)是指:样本的共同点(同质性)使得某一变量值会趋向于同一数值,比如身高,在图形上就表现为变量值聚集在某个中心值的周围,也称为平均水平,如均数或中位数
- 离散趋势(Dispersion Tendency)是指:由于各种原因(遗传、环境等),同一个总体中的个体之间都不会完全相同,所以某个变量的值不会都是同一个数值,而是向平均水平左右的方向移动,而分散开来。(例如,某地区男性身高的平均值是1.7,意味着,该地区每个个体的身高都会在1.7上下)
方差或标准差是综合衡量这片数据个体间差异的大小的一个重要指标。
我们用每一个个体的身高值与平均值相减做平方,再加和除以总人数,就得到了方差(开方后即得到“标准差”)
Q3:计算样本方差时为什么是除以(n-1)?
概率理解:对于 n 个样本,如果我想抽取的容量是 n(计算总体方差),事实上(需要计算样本方差)只能抽取 n-1 个样本(即 n-1 个自由度,n-1 个独立信息片段),因为最后一个样本是可以通过
算出来的。这个时候只要抽取 n-1 个样本,所以每个样本被抽取的概率是 1/(n-1)。
统计学研究,就是希望在这个现实社会中透过大片的数据获取我们想要的信息。
统计学重要的研究内容之一是“用样本推测总体”。具体而言,就是用样本均数和样本标准差来估计总体均数和总体标准差(对于一个特定的总体,总体均数和总体标准差是恒定不变的),而这里的估计有一个很重要的原则就是“无偏估计(Unbiased Estimator)”。所谓”无偏“,就是样本值应该围绕总体值上下波动的,不能总在总体值的上面,或者总在总体值下面。
但是,从总体中进行抽样,每次抽样便获得一个特定的样本,样本值也就变化一次。下面不等式恒成立。左边是样本方差,右边是总体方差。
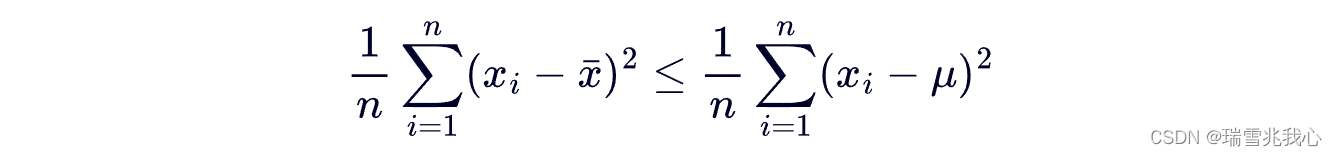
现实中我们无法计算总体均数 μ,当用样本均数代替总体均数后,上面左边的式子总是小于右边的式子。因此,如果我们采取左式计算样本方差,那它就不是总体方差的“无偏”估计了,而是总小于总体方差。
我们假定随机变量 x 的数学期望 μ 是已知的,然而方差 σ2 是未知的,在这个条件下,根据方差的定义我们有:
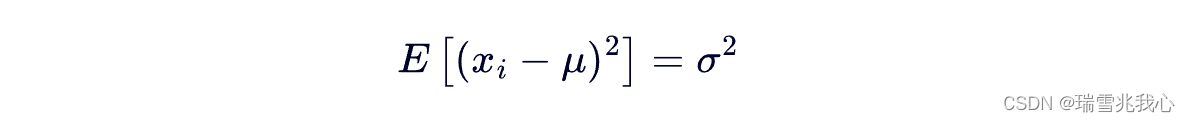
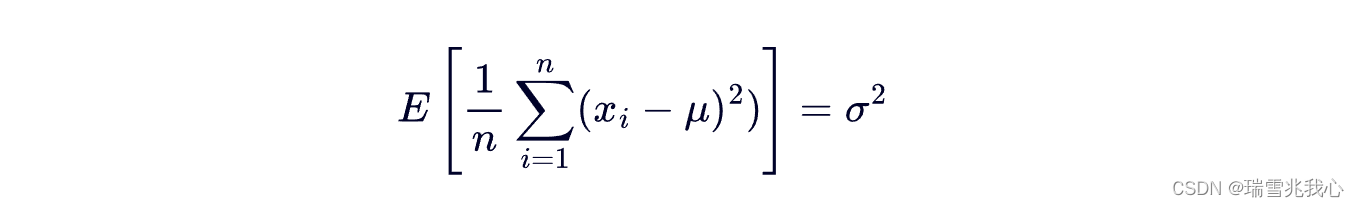
现在,我们考虑随机变量 x 的数学期望 μ 是未知的情形。这时,我们会倾向于直接用 替换掉上面式子中的 μ,但是这样就出现了不是总体方差的“无偏”估计的问题。参考无偏计算公式
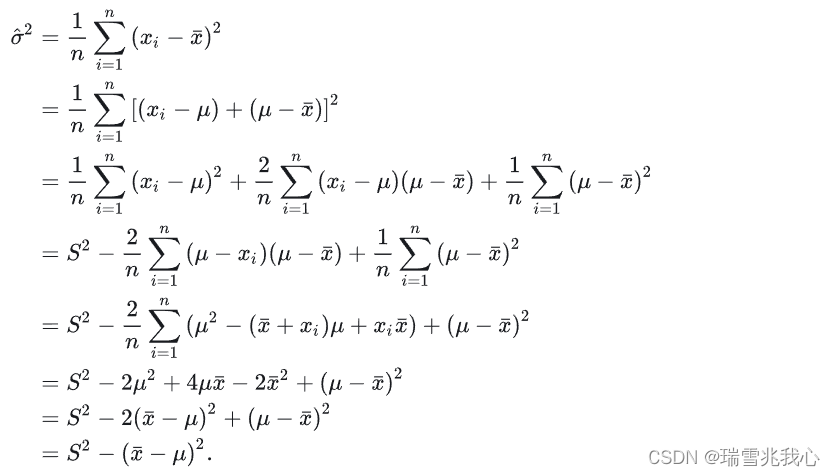
由此我们可以明显发现这个估计其实只有在 x = μ 时才是无偏估计,为了满足 “无偏”条件,唯一的办法就是将它的分母调小,左边的样本方差值就会变大,这就是分母 n-1 的由来。
2 协方差
样本方差是用来衡量单个随机变量的离散程度(如:人口中一个人的身高的变化),而协方差(Covariance)则是来刻画两个随机变量的相似程度(如:一个人的身高和人口中一个人的体重)。
随机变量自身的协方差的计算公式:
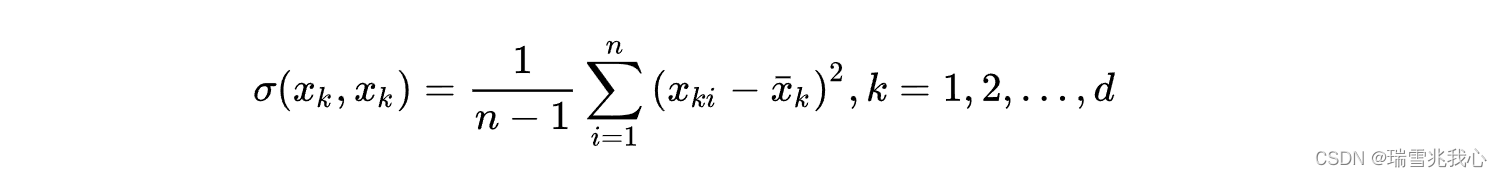
两两之间的协方差的计算公式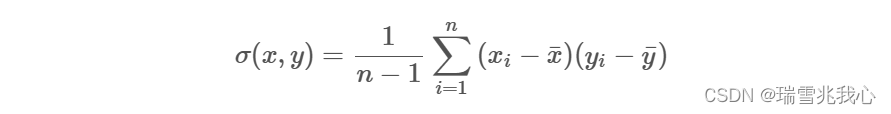
3 从方差和协方差到协方差矩阵
有如下协方差矩阵公式可知,对角线上的元素为各个随机变量的方差,非对角线上的元素为两两随机变量之间的协方差,
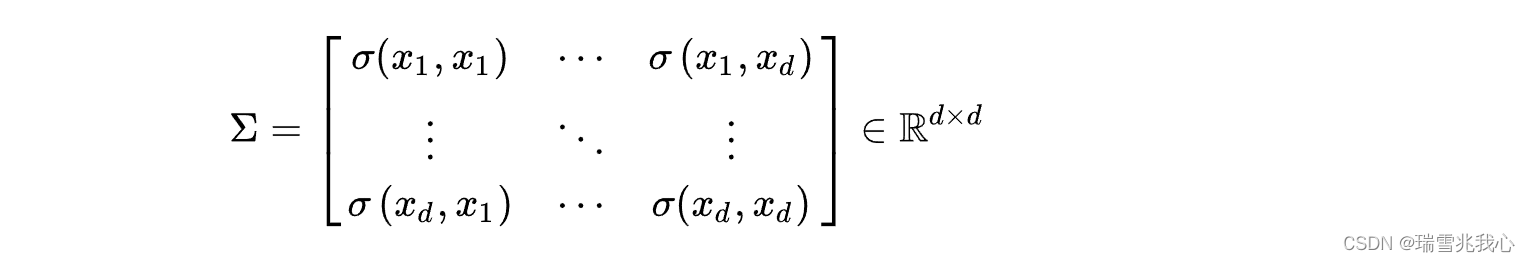
4 主成分分析的数学原理:
通过对协方差矩阵进行特征分解,从而得出主成分(特征向量)与对应的权值(特征值(Eigenvalue))。然后剔除那些较小特征值(较小权值)对应的特征,从而达到降低数据维数的目的。参考PCA(主成分分析)的理解与应用
















 876
876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











