





 文章介绍了如何利用大语言模型LLM增强功能,通过检索和生成技术,结合文本和图像的多模态信息。方法包括索引知识库、使用嵌入机处理文本片段、多模态嵌入搜索和多模态LLM生成文本或图像摘要,以提供更丰富的答案合成。
文章介绍了如何利用大语言模型LLM增强功能,通过检索和生成技术,结合文本和图像的多模态信息。方法包括索引知识库、使用嵌入机处理文本片段、多模态嵌入搜索和多模态LLM生成文本或图像摘要,以提供更丰富的答案合成。
- 本质
- 将用户输入的信息补充到大语言模型LLM中。LLM 可以使用这些信息来增强其生成的回答或响应。
- 先检索,后生成
- 传统RAG
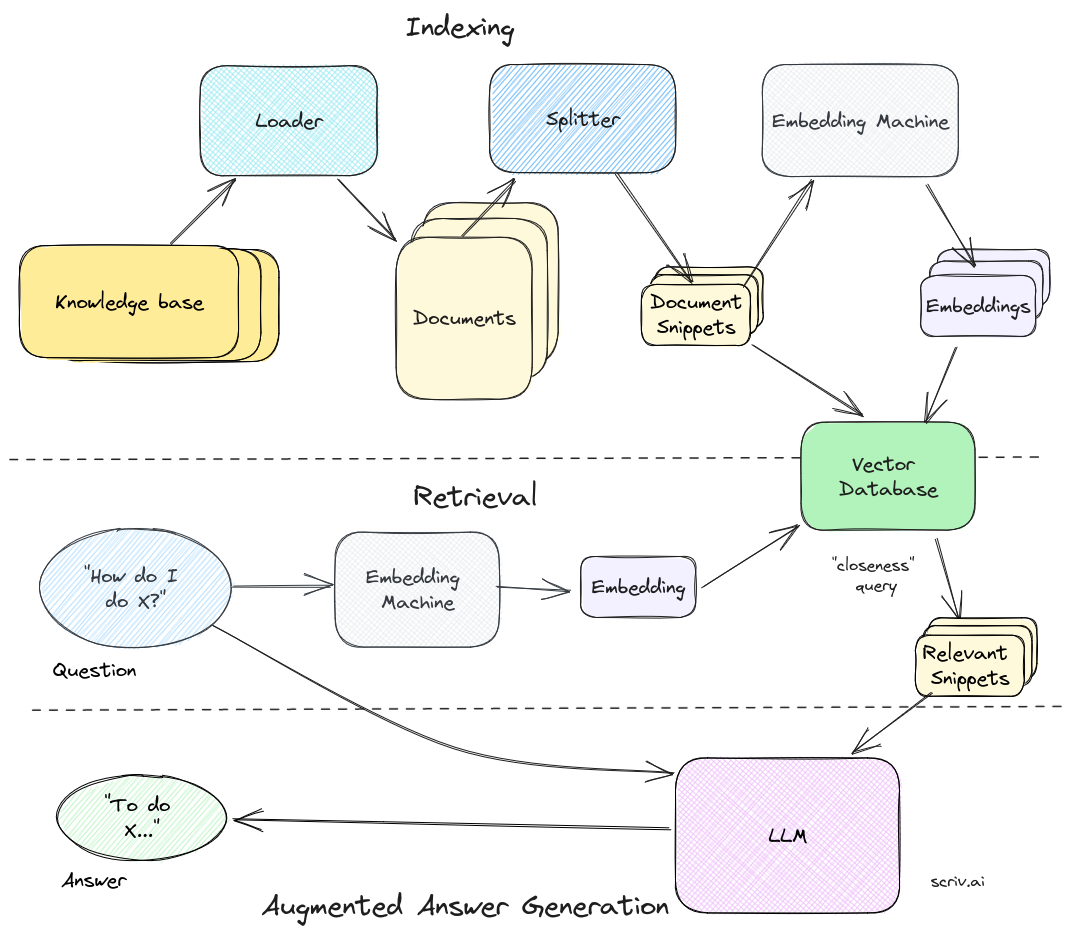
- 实现过程
- 对知识库进行索引。使用加载器获取知识并将其转换为单个文档,然后使用分割器将其转换为小块或片段。
- 将这些片段传递给嵌入机,嵌入机将它们转换为可以用于语义搜索的向量。并将这些嵌入向量与其文本片段一起保存在向量数据库中。
- 用户提出问题并将问题通过相同的嵌入机发送到向量数据库中,检索并确定最匹配的片段。
- 将最匹配的片段、自定义的system prompt和用户提出的问题一起格式化,交由LLM处理,最终得到针对具体语境的答案。
-
- 缺点
- 许多文档包含多种内容类型,不仅仅是文本,还包括表格和图像。
- 文本拆分可能会破坏表格,从而损坏检索中的数据
- 嵌入表可能会给语义相似性搜索带来挑战
- 图像中捕获的信息通常会丢失
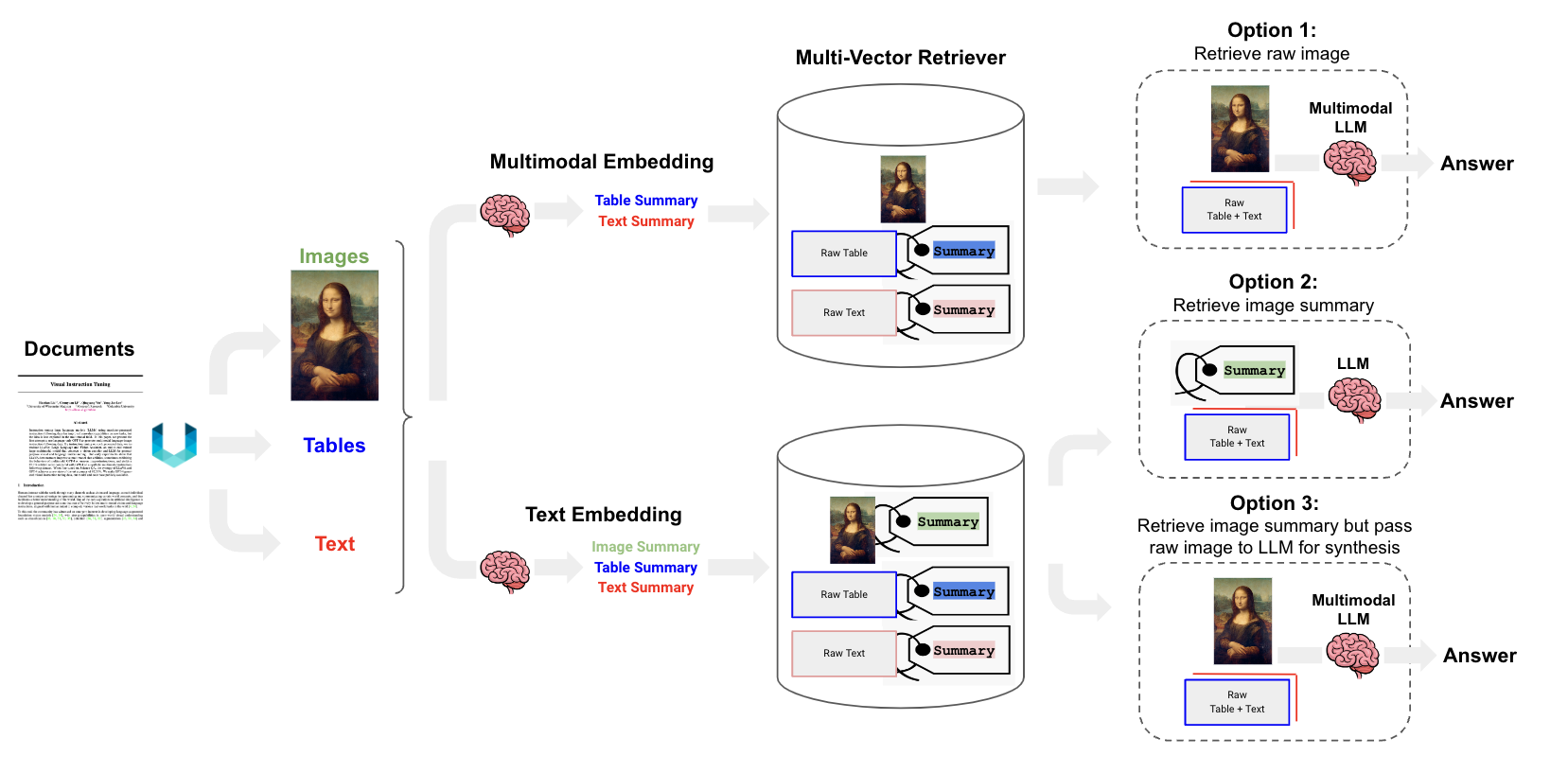
- 实现过程
- 多模态RAG
- Option 1:
- 使用多模态嵌入(如 CLIP)嵌入图像和文本
- 使用相似性搜索检索两者
- 将原始图像和文本块传递给多模态 LLM 以进行答案合成
-
1.RAG(检索增强生成)
最新推荐文章于 2025-05-27 18:19:13 发布

















 6104
6104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









