







社区
- 社交网络:用户之间通过某些行为关系构成的网路。这些行为根据业务场景可以是:点击、关注、好友、一起打游戏、一起开会、一起聊天。
- 社区:社交网络中,用户之间连接较为紧密的子网络,可以看做是一个社区。通常社区内的用户连接较为紧密,社区之间的用户连接较为稀疏
- 社区发现(Community Detection):则是在大规模的社交网络中,找出不同的社区,对用户进行划分
- 社区发现,仅仅是利用社交网络结构来对节点进行划分,相比于GNN网络,少了节点的特征。
社区发现算法
图分割
- 这类算法大多属于迭代二分法,核心思想是把图分割成两个子图,然后继续迭代。经典的算法为 Kernighan-Lin算法(KL算法)
- KL算法属于一种贪婪算法:
- 定义社区内边数和社区间边数的增益函数Q,算法就是最大化Q来确定社区
- 具体步骤是先随机化切割多个社区,将某个社区的节点移动/交换到另外一个社区,计算此时整个网络的Q值。从初始阶解开始搜索,直到找不到更优的候选解为止
- 必须指定子图大小,实际应用比较困难
- 其他的图分割算法类似,无非就是在Q的定义,社区划分效率上做改进
聚类算法
- 一般说的社区发现的聚类算法指GN算法,但是计算复杂度高,实际应用不现实
- 可以做的是根据社交网络的性质把用户构建成序列,然后用word2vec训练用户向量,最后用聚类算法,使不同的用户向量分到不同的类中,形成社区。原理比较简单,可实现,但是需要根据业务经验指定聚类的簇心数
标签传播
LPA(Label Propagation Algorithm), 比较简单
- 对所有节点指定一个唯一的标签,标签体系根据业务确定
- 对每一个节点,统计邻居节点的标签,选择最多的标签赋给当前节点。
- 迭代刷新,直到收敛
比较依赖初始化标签的选择,而且邻居节点标签最大的有多个时随机选择,增加了随机性。
基于模块度的算法
- 模块度是衡量一个社区划分好坏的指标,同时也可以作为目标函数迭代算法
- 模块度经历过几个版本,目前主流的定义如下:

- 第二个公式注意区分A和δ, A是指v和w两个节点连接的时候为1,δ是指v和w所在的社区在一个社区的时候为1
- 第二个公式就是计算v和w相连且在一个社区的边数量在v和w相连的所有边数量的占比。也就是社区内部总边数和网络总边数的比例。2m表示所有边总和*2,因为两个节点相连无向图会有两条边
- 第三个公式:kv*kw,表示随机情况下,v和w连接的期望,除以2m就表示随机情况下v和w相连的占比。
- 简单理解:A(vw)可以看作是节点v和节点w在同一个社区的边数之和。kv*kw/2m可以看作v和w在随机情况下连接的边数期望。如果社区分得好,节点内连接的数肯定是要比随机分配的时候该社区内节点连接的数要大的。随意Q越大越好。
Louvain算法以及实现

1.第一步:初始化每个节点为1个社区,然后遍历每个节点,判断当前节点移到邻居节点所在社区使模块度增益情况。选择模块度增益最大的社区作为节点要加入的社区。直到整个模块度都不发生增长。
2. 第二步:将第一步得到的社区聚合成一个点,生成社区的带新的网络,重复第一步。
3. 缺点:采用贪婪思想很容易将整个社区划分“过拟合”。因为Fast Unfolding是针对点遍历,很容易将一些外围的点加入到原本紧凑的社区中,导致一些错误的合并。这种划分有时候在局部视角是优的,但是全局视角下会变成劣的。后面提出一种基于模块密度的算法,可以解决该问题:Network community detection using modularity density measures
其中,模块度变化可以用以下公式计算:
4. 模块度
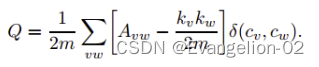

- 模块度增益:即加入某个节点i时Q的变化

代码实现:
- 原理实现:louvain算法python实现
- 调包实现:networkx+python-louvain
其中调用networkx时,可用以下函数加载自己的数据:
def load_graph(path):
nodes = []
edges = []
with open(path) as text:
for line in text:
vertices = line.strip().split()
if len(vertices) == 3:
vi = int(vertices[0])
vj = int(vertices[1])
w = float(vertices[2])
else:
vi = int(vertices[0])
vj = int(vertices[1])
w = 1.0
edges.append((vi, vj, w))
if vi not in nodes:
nodes.append(vi)
if vj not in nodes:
nodes.append(vj)
G = nx.Graph()
G.add_nodes_from(nodes)
G.add_weighted_edges_from(edges)
return G
- networkx api: networkx















 4213
4213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









