







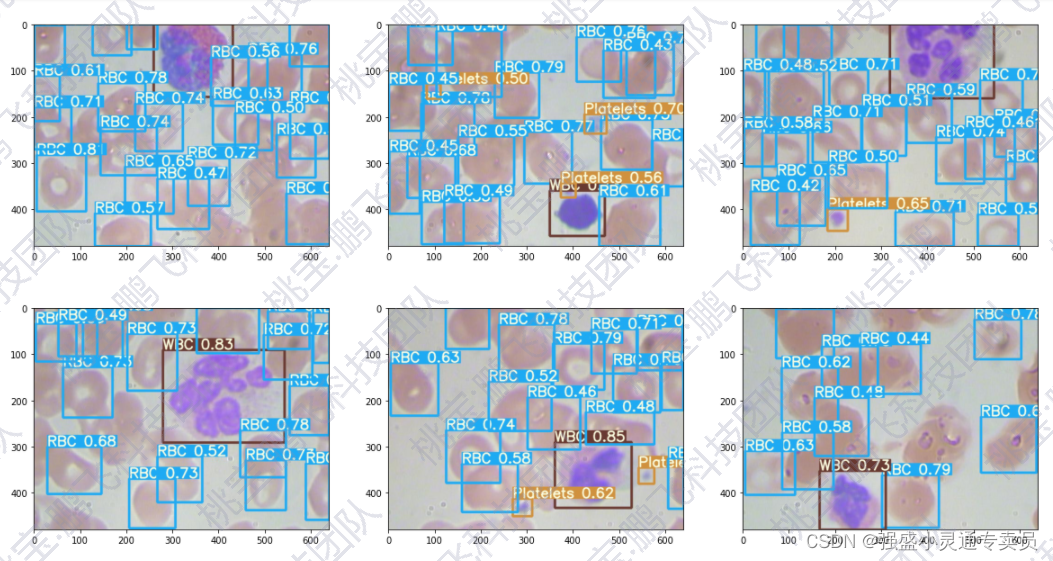
在自定义数据集上训练了一个对象检测模型,以从显微血液涂片图像中查找红细胞、白细胞、血小板计数的数量。
1 数据集
BCCD数据集是用于血细胞检测的小规模数据集。
https://github.com/Shenggan/BCCD_Dataset
有三种标签:
- RBC(红细胞)
- WBC(白细胞)
- 血小板(主要)


目录结构:
├── BCCD
│ ├── Annotations
│ │ └── BloodImage_00XYZ.xml (364 items)
│ ├── ImageSets # Contain four Main/*.txt which split the dataset
│ └── JPEGImages
│ └── BloodImage_00XYZ.jpg (364 items)
├── dataset
│ └── mxnet # Some preprocess scripts for mxnet
├── scripts
│ ├── split.py # A script to generate four .txt in ImageSets
│ └── visualize.py # A script to generate labeled img like example.jpg
├── example.jpg # A example labeled img generated by visualize.py
├── LICENSE
└── README.mdannotations = sorted(glob('/content/BCCD_Dataset/BCCD/Annotations/*.xml'))
df = []
cnt = 0
for file in annotations:
prev_filename = file.split('/')[-1].split('.')[0] + '.jpg'
filename = str(cnt) + '.jpg'
row = []
parsedXML = ET.parse(file)
for node in parsedXML.getroot().iter('object'):
blood_cells = node.find('name').text
xmin = int(node.find('bndbox/xmin').text)
xmax = int(node.find('bndbox/xmax').text)
ymin = int(node.find('bndbox/ymin').text)
ymax = int(node.find('bndbox/ymax').text)
row = [prev_filename, filename, blood_cells, xmin, xmax, ymin, ymax]
df.append(row)
cnt += 1
data = pd.DataFrame(df, columns=['prev_filename', 'filename', 'cell_type', 'xmin', 'xmax', 'ymin', 'ymax'])
data[['prev_filename','filename', 'cell_type', 'xmin', 'xmax', 'ymin', 'ymax']].to_csv('/content/blood_cell_detection.csv', index=False)

2 模型
YOLOv5
# parameters
nc: 80 # number of classes
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, BottleneckCSP, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]

3 训练


4 验证
















 2902
2902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









