







由于总是扎在深度学习的坑里,机器学习的其他算法总是学了就忘,模棱两可,前几天刚又刷了下数理统计,所以本着打造一个扎实及基础的思想,决定好好推一下各种常见的机器学习算法,留作学习笔记。说不定面试就手推公式了呢。。。其实再推一遍也没啥用。。。。放下书就又忘了。。。
线性回归
表面理解
- 所谓线性:体现在y于x仅仅存在 1次方 函数关系
- 所谓回归:体现在我们所学习和预测的数据会回归到某一区间,比如正态分布,回归到平均值
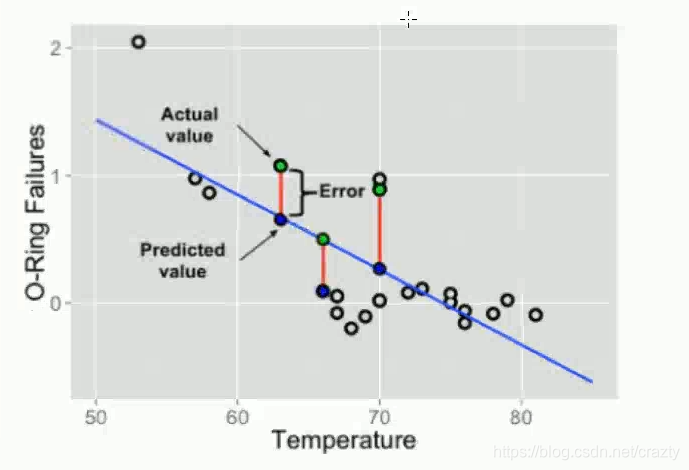
- 具象化出来,也就是图中的线,要尽可能的穿过所有的点,穿不过的也要尽量使loss最小,(loss由loss-function计算得出简单可以理解为图上点到线的距离求和最小)
- 多元线性回归也不过是多添加了几个维度,也就是特征数,y=x1w1+x2w2…+b (其中b并不考虑各种影响下的本身的偏移量)

深入理解线性回归:从数学上搞出解析解
-
什么是中心极限定理(Central Limit Theorem)
中心极限定理指的是给定一个任意分布的总体。我每次从这些总体中随机抽取 n 个抽样,一共抽 m 次。 然 后把这 m 组抽样分别求出平均值。 这些平均值的分布接近正态分布。 -
我们这里假设每一个误差(也就是:(|<y真实> - y<预测>| 记做 ε) 是随机的)那么根据中心极限定理,ε服从正态分布。
那么现在看看:我们知道了ε,知道了真实的y,就可以求预测的y了,知道了输入的x,最后我们就可以求出w了。 -
下式代表:误差+预测=真实
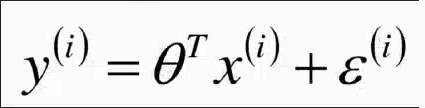
-
正态分布的概率密度
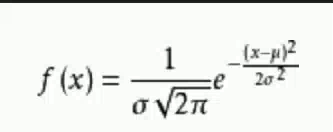
-
然后我们用ε替换掉x-μ
得到:
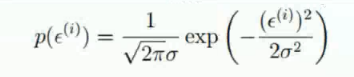
-
再用8里的公式:
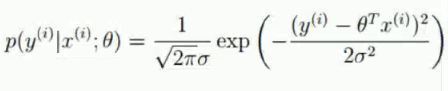
-
多个概率密度函数连乘近似约等于概率的连乘(因为只知道概率密度不知道概率,只能近似了)这样就有了极大似然函数。
大佬给出的极大似然函数的超详细解释,读完之后全身都通透了!
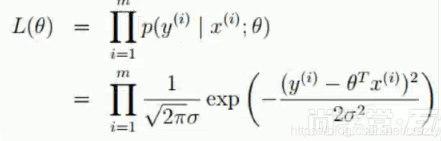
-
然后这里就是期末考试刷题的万年套路了,取㏒,把乘变加。

求l(θ)最大,也就是求J(θ)最小,因为这是个凸函数,也就是J(θ)求导=0时的θ的值。
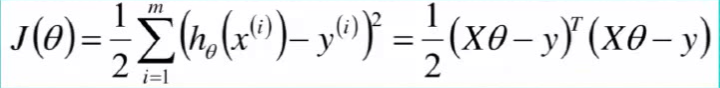

代码实现
import numpy as np
import matplotlib.pyplot as plt
__author__ = 'yasaka'
# 这里相当于是随机X维度X1,rand是随机均匀分布
X = 2 * np.random.rand(100, 1)
# 人为的设置真实的Y一列,np.random.randn(100, 1)是设置error,randn是标准正太分布
y = 4 + 3 * X + np.random.randn(100, 1)
# 整合X0和X1
X_b = np.c_[np.ones((100, 1)), X]
print(X_b)
# 常规等式求解theta
theta_best = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y)
print(theta_best)
# 创建测试集里面的X1
X_new = np.array([[0], [2]])
X_new_b = np.c_[(np.ones((2, 1))), X_new]
print(X_new_b)
y_predict = X_new_b.dot(theta_best)
print(y_predict)
plt.plot(X_new, y_predict, 'r-')
plt.plot(X, y, 'b.')
plt.axis([0, 2, 0, 15])
plt.show()
补充:
Q:为什么求总似然的时候,要用正太分布的概率密度函数?
A:中心极限定理,如果假设样本之间是独立事件,误差变量随机产生,那么就服从正太分布!
Q:总似然不是概率相乘吗?为什么用了概率密度函数的f(xi)进行了相乘?
A:因为概率不好求,所以当我们可以找到概率密度相乘最大的时候,就相当于找到了概率相乘最大的时候!
Q:概率为什么不好求?
A:因为求得是面积,需要积分,麻烦,大家不用去管数学上如何根据概率密度函数去求概率!
Q:那总似然最大和最优解的关系?
A:当我们找到可以使得总似然最大的条件,也就是可以找到我们的DataSet数据集最吻合某个正太分布!
即找到了最优解!
通过最大似然估计得思想,利用了正太分布的概率密度函数,推导出来了损失函数
Q:何为损失函数?
A:一个函数最小,就对应了模型是最优解!预测历史数据可以最准!
Q:线性回归的损失函数是什么?
A:最小二乘法,MSE,mean squared error,平方均值损失函数,均方误差
Q:线性回归的损失函数有哪些假设?
A:样本独立,随机变量,正太分布
通过对损失函数求导,来找到最小值,求出theta的最优解!
深入理解线性回归:梯度下降法
Q:梯度下降法是干嘛的?
A:梯度下降法是一种以最快的速度找到最优解的方法!

求解步骤:
- 初始化theta,w0…wn
- 接着求梯度gradient
- theta_t+1 = theta_t - grad * learning_rate
learning_rate是个超参数,太大容易来回振荡,太小步子太短,需要走很长时间,不管太大还是太小,
都会迭代次数很多,耗时很长 - 等待grad < threshold,迭代停止,收敛,
threshold是个超参数
公式推导:
- 核心公式就是这个:
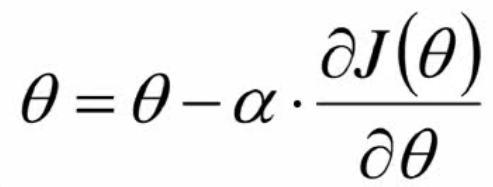
- 下面我们来对损失求导:注意这里的θ和y都是向量,x是输入矩阵。


代码实现
import numpy as np
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
X_b = np.c_[np.ones((100, 1)), X]
# print(X_b)
learning_rate = 0.1
n_iterations = 10000 # 迭代次数
m = 100 # 100个样本
# 1,初始化theta,w0...wn
theta = np.random.randn(2, 1)
count = 0
# 4,不会设置阈值,之间设置超参数,迭代次数,迭代次数到了,我们就认为收敛了
for iteration in range(n_iterations):
count += 1
# 2,接着求梯度gradient
gradients = 1/m * X_b.T.dot(X_b.dot(theta)-y) # 这里用了X_b,也就是整体的输入矩阵,这里和公式推导的不一样,这样导致算出来的是个梯度矩阵,矩阵中的是特征的梯度。
# 3,应用公式调整theta值,theta_t + 1 = theta_t - grad * learning_rate
theta = theta - learning_rate * gradients
print(theta)















 883
883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









