










《A Reinforcement Learning Method for Multi-AGV Scheduling in Manufacturing》
ICIT/2018
1 摘要
这篇文章提出用强化学习求解多AGV流水车间调度问题。AGV在固定轨道上移动,在机器之间运输半成品(semi-finished product)。
目标:最小化平均工件延迟和总完工时间。
2 论文解读
强化学习算法应用于车间调度问题的难点:
(1)如何将生产调度问题转化为强化学习问题。
(2)如何保证调度问题的可行解可以通过该算法来学习。
2.1 问题描述
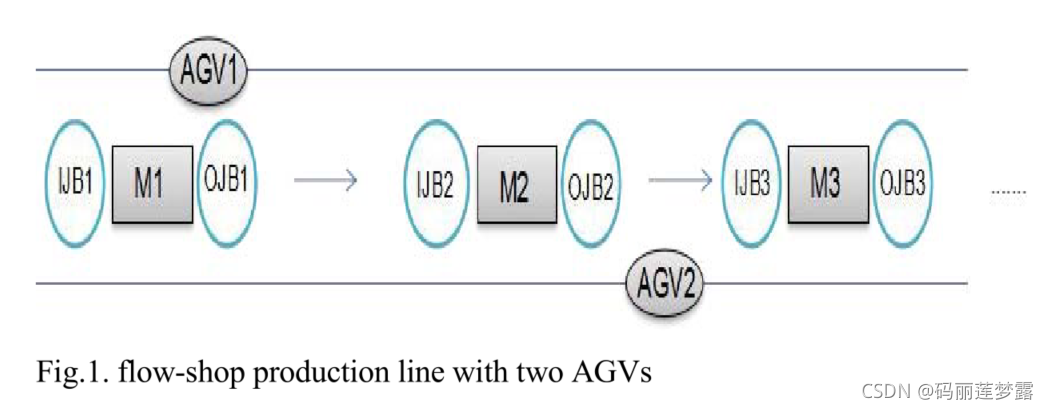
下图中,IJB表示等待加工的工件缓冲区,OJB表示已加工完的工件缓冲区,AGV参与的工作是将从工件从上一工序加工机器的OJB运输到下一工序加工机器的IJB。
2.2 强化学习要素定义
2.2.1 State Space S(状态空间 S)
状态空间由缓冲区-机器组合以及当前AGVs的位置决定的,对缓冲区OJBi-机器Mi组合的状态Si,Si的值定义为={1,2,3,4},分别表示为:
(1)机器Mi空闲且OJBi缓冲区为空.
(2)机器Mi正在加工OJBi缓冲区为空
(3)机器Mi空闲但OJBi缓冲区不为空
(4)机器Mi正在加工且OJBi缓冲区不为空
于是,整个状态空间定义为m+k(m个机器-缓冲对的状态,即上面的4个+k个AGV所在的位置)个长度的一位向量空间。
位置定义可见:

2.2.2 动作空间 A
对动作空间A={a1,a2,...,am-1},动作ai定义为AGV将一个工件从机器的OJB缓冲区转移至下一机器的IJB,所有工件 都需要被转移至下一机器直至经过所有机器,于是最小的转移次数为n*(m-1)。
2.2.3 状态转移(System Transition Times)
当AGV将一个工件放入下一机器的IJB时,这个AGV就进入下一个Transporting task,进行下一状态,假设AGV是在Mk的位置并且需要从Mi运输工件至mi+1传输作业,则该传输任务包括两个连续的AGV移动:
(1)第一个运动是AGV从其当前位置移动到Mi的输出缓冲区,以取走作业。
(2)第二个动作是将产品移动到Mi+1的IJB。
如果在Mi的OJBi中没有完成的作业,则第二移动可能被延迟。因此,该AGV必须在机器Mi处定时等待,直到Mi+1完成作业为止。d定义为AGV到达Mi的输出缓冲器之后的等待时间。作业过渡的时间计算如下 :
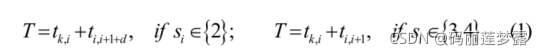
2.2.4 奖励函数
这篇文章它设计了两个奖励函数,它的策略是一部分AGV使用r1作为奖励函数,以最小化AGV等待时间,剩下一部分AGV使用r2作为奖励函数,以此来最小化工件等待时间,最终来引导最大完工时间的下降。
当AGV完成一个transfer task,它将转移下一个工件到另一个机器,下一机器定义为Mi,AT(i)定义为AGV到达Mi的OJB的时间,由于机器可以处于任何状态,AGV到达时将有两种可能的情况:
(1)Mi处于状态2,AGV必须等待直到机器完成工序。
(2)Mi处于状态3、4,AGV不会延迟直接转移下一工件。
在第二种情况下,当AGV到达时,存储的所有作业都等待了不同的持续时间,因此AGV将选择等待时间最长的工件,这篇文章添加了一条规则,即如果机器Mi处于状态2,则AGV将不会接这个任务。
于是,对r1:
![]()
其中,JW(i)是等待时间最长的作业的过程完成时间 ;
对r2:
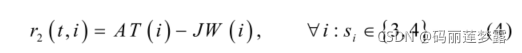


















 965
965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











