







一、算法简介
AdaBoost是一种迭代算法,核心思想是针对同一个训练集去训练多个不同的分类器(弱分类器),训练完毕之后,把所有这些弱分类器进行融合得到最终的分类器(强分类器)。
算法本身是通过改变数据分布来实现的,首先根据每次训练结束之后每个样本是否分类正确然后赋予不同的权重,然后把新的数据集传递到下一层训练下一个分类器,最终把所有的分类器融合起来,作为最后的分类器进行使用,进行决策。使用AdaBoost分类器可以排除掉一些不必要的训练数据特征,(在分类中是把分类错误的数据集赋予较小的权重实现)把分类的关键放在关键的训练数据上面。
二、算法流程
①首先通过对N个样本的学习得到第一个分类器。
②将①中分类错误的样本和其他的新数据一起构成一个新的N个训练样本,进行学习,得到第二个分类器
③将①和②中分错的样本加上其他的新样本重新构成一个新的数据量为N的训练样本,进行学习,得到第三个分类器
。。。
④最终,把所有的弱分类器进行融合,得到我们最终需要的分类器。
三、算法中存在的问题
①如何调整训练集,使得在训练集上训练弱分类器得以进行?
②如何将训练得到的各个弱分类器联合起来形成强分类器?
解决办法:
①:使用加权后选取的训练数据集代替随机选择的训练样本,这样将训练的焦点集中在比较难分的训练数据样本之上。
②:将弱分类器联合起来使用加权的投票机制代替平均投票机制,让分类效果好的弱分类器得到比较大的权重,而差的弱分类器的权重相应减小一些。
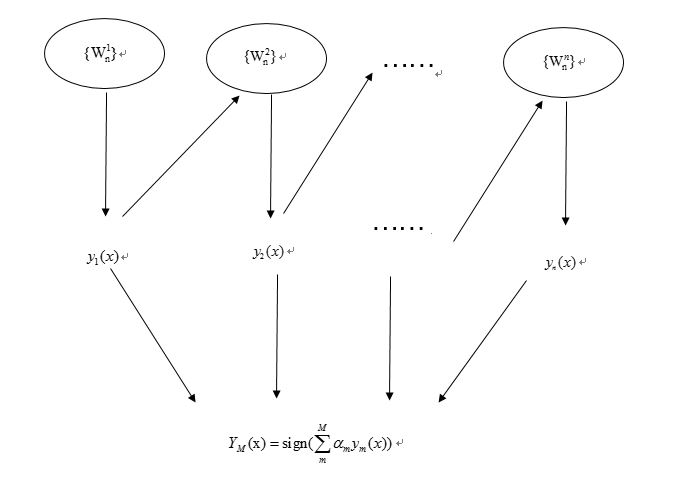
AdaBoost结构,最后的分类器Ym是由多个弱分类器组合而成的,相当于最后m个弱分类器来投票决定分类,而每个弱分类器的“话语权”——权重α不同。
具体过程:
1、初始化所有训练样例的权重为1/N,其中N为样例数。
2、for m=1,…,M
a)训练弱分类器y1,使其最小化权重误差函数: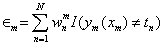
b)计算弱分类器的权重系数α: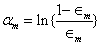
c)更新权重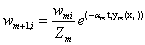 i=1,…,N
i=1,…,N
Zm是规范化因子,使所有w和为1;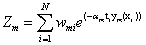
3、得到最后的分类器
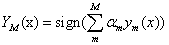
原理:可以看到整个过程和途中是一样的,前一个分类器改变权重w,同时组成最后的分类器,如果一个训练样例在前一个分类器中被误分,那么它的权重会增加,相应地,被正确分类的样例的权重会减小,使下一个分类器会更在意被分类错误的样例。
一个例子
博主好懒,字不想打了,直接附上自己的笔记了~~~(字是真的好丑~~!)


本算法到此完结~~~没有下文















 1302
1302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









