






摘要
本文提出了一种新的多语提示学习方法(MultiPLe),该方法由三个主要部分组成,即多语提示模块、分层原型模块和四联体对比学习模块。多语提示模块是针对单语场景中出现的多词混淆而设计的。具体来说,它将最初的单语文本扩展为多语集,为多义词触发器提供有价值的信号。然后,它驱动一个跨语言预训练语言模型(PLM)来引出先验知识,以捕获上下文语义和模糊触发器的可区分特征。为了解决同义词混淆问题,提出了基于两级原型网络的分层原型模块,以更细的粒度建立混淆触发器与其对应标签之间的联系。最后,我们引入了一个四联体对比学习模块,以增强标签表示,同时去噪多语提示模块可能带来的潜在干扰。
语义混淆主要表现为一词多义混淆和同义词混淆:
- 例如,如图1的左侧所示,两个标签都是“Personnel.End-Position”和“Con-flict.Riot”都是“fired”这个词引发的,因此,在处理“已触发”的触发器实例时,传统ED模型很难区分正确的事件标签。
- 例如,图1右侧所示,在少样本事件检测中,触发器“arrived”和“reached”的频率分别为11和4,导致相同的标签“Move-ment.Transport”,而对于只被“enter”触发一次的隐藏实例,ED方法很难分配标签“Movement.Transport”。
解决办法
多语提示模块通过预训练语言模型中的多语消歧和先验知识来开发触发器的语境语义,以缓解多语多义混淆。然后,采用分层原型模块,将捕获到的最深处语义模糊触发器与细粒度的标签连接起来,减少同义词混淆;最后,我们采用四联体对比学习模块来解决标签表示不足和潜在噪声的问题。
研究方法
多语言提示模型(MultiPle)三个重要组成部分如下:
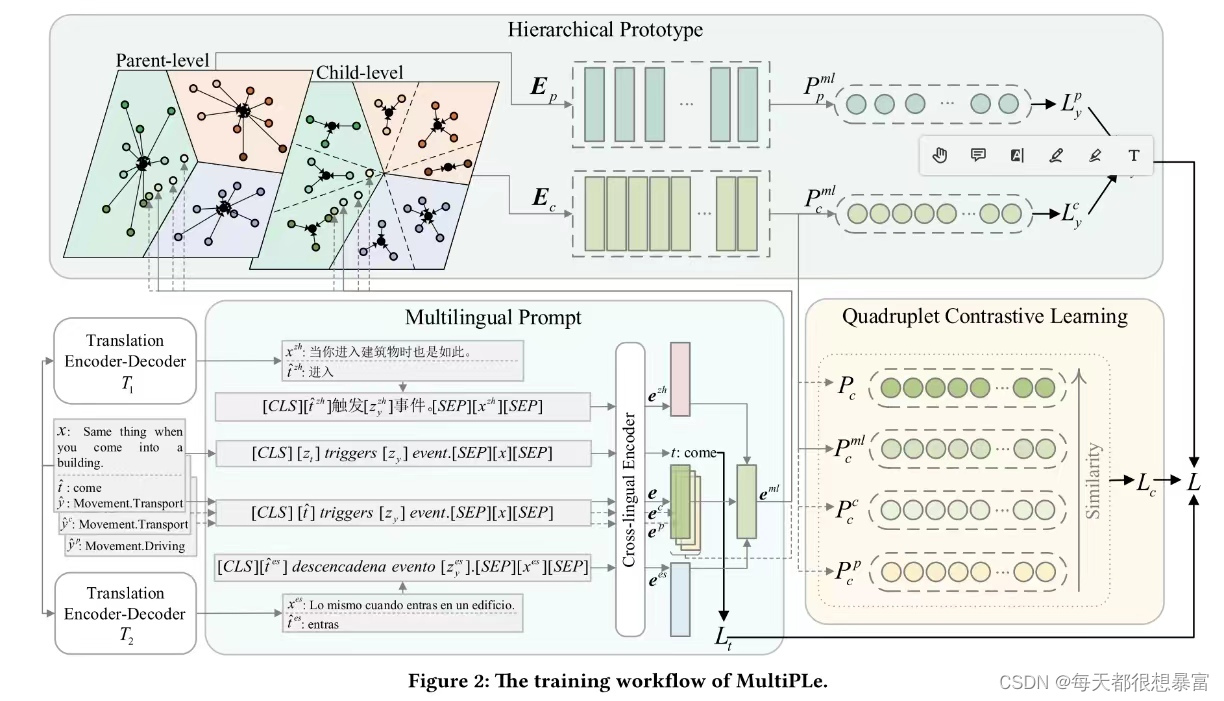
- 多语言提示模块(multilingual prompt module):给定一个原始英语实例(x, t, y),我们首先生成对比实例和翻译后的双语实例,并用语内提示模板对其进行修改,得到触发器t和相应的事件嵌入,进而给出联合事件表示eml,解决多词混淆问题。
- 分层原型模块(hierarchical prototype module:针对同义词混淆问题,提出了两级原型网络Ep和Ec来预测事件标签。
- 四联体对比学习模块(quadruplet contrastive learning module:利用对比实例的相似性来挖掘微妙的标签特征,提高检测性能。
通常,MultiPLe输出预测的触发器t和事件标签y,并由总损失L监督,以优化跨语言编码器和原型网络。
研究创新点
- 据我们所知,我们是第一个处理语义混淆的少样本事件检测(FSED),它进一步分为多义混淆和同义词混淆。
- 我们提出了一种多语言提示(multilingual prompt)来缓解一词多义的混淆,并设计了一个分层原型模块(hierarchical prototype module)来缓解同义词的混淆。此外,采用四联体对比学习模块(quadruplet contrastive learning module)来增强标签表示和去噪干扰。
- 我们在两个公共数据集上进行了全面的实验,以验证MultiPLe在FSED中缓解混淆的有效性,在两个公共数据集上的实验表明,MultiPLe优于最先进的f1得分基线,FSED的最大改进率为13.63%。
结论
在本文中,我们提出了一种新的方法来消除FSED中的语义混淆(一词多义和同义词)。为了减少多义混淆,开发了多语言提示模块,以掌握触发器的上下文语义并生成联合事件表示。此外,为了解决同义词混淆问题,设计了一个分层原型模块来捕获连接到模糊触发器的可区分标签特征。最后,采用四联体对比学习模块增强标签表示,规避模型训练中潜在的噪声。在两个公共数据集上的实验表明,在加权f1分数方面,MultiPLe在FSED的最先进基线上取得了显着的改进。对于未来的工作,我们希望在跨语言少镜头事件检测中加入提示调优方法来丰富表示生成。
附录
多语言提示模块
我们首先采用传统的单语提示进行触发器识别,然后通过多语提示生成联合事件表示来解决多词混淆问题。
- 触发器识别(Trigger identification):
- 我们实现事件检测范式的第一步,即x→(x, t)。给定一个英语实例(x, t, y),我们将x连接到一个手动构建的提示模板中,即“[
]触发[
]事件”,得到修改后的提示符
。
- 其中[
被输入到跨语言编码器中以填充[
中所有候选词的分布概率
。
- 考虑到t∈x,我们将预测触发器在
上的概率分布重写为记号序列x1上的分布:
={
,
,…,
},其中
。
- 其中
是
是已识别触发器的概率。那么,最终触发t可以表示为t = argmax
,其中
表示真概率,即如果
,否则
。
- 联合事件(Joint event representation)
- 在得到预测的触发器t后,我们进行下一步(x, t)→y。在提示符之前,每个元组(x,
,
)的没有事件标签的双语实例,即中文的(
,
)和西班牙语的(
,
),分别由翻译编码器T1和T2准备。英文提示模板的触发器进一步完善,形式为“[t]触发[
]事件”。,然后我们可以得到提示符
,类似地其他两个模板设计做出相应的提示
、
。
- 对于每个提示符,我们将其输入到跨语言编码器中,生成对应的[MASK]的最后一个隐藏向量,即e,
和
。之后,训练阶段的联合事件表示
∈
,可以通过三个嵌入的平均值来计算,其中d是事件表示的维数。
分层原型模块
我们提出了一种新的分层原型模块来描述事件标签之间的继承关系,该模块由父级和子级原型网络组成。
- 父级原型网络优化(Parent-level prototypical network)
- 我们首先从初始标签空间Y∈
构造一个父标签空间Yp∈
,其中父标签的数目小于初始标签的数目,N < n。我们将一个实例的真正的父标签记为y´p∈Yp,,父级原型网络Ep = {ep1, ep2,…, epn}是随机初始化的,其中epi∈Ep是表示第i个父标签ypi的空间质心的d维向量。
- 对于得到的事件表示eml, 根据欧几里得距离,然后我们可以得到eml在所有父标签上的概率分布。
- 以交叉熵损失Lp y对父级原型网络进行优化:
- 子级原型网络优化(Child-level prototypical network)
- 与父级类似,子级原型网络Ec = {ec1, ec2,…,首先c随机初始化ecN},其中每个子标签的原型可以记为eci∈Ec,一个d维向量。通过将eml投射到Ec上,我们可以生成eml与第i个子标签yci的概率。
- 以交叉熵损失Lc y用于优化子级原型网络的损失函数为
- 确定最终事件标签
- 为了进行测试,我们首先将事件表示e投影到Ep上,这样我们就可以在中获得具有最高概率ppi的预测父标签yp。
- 当e作用于Ec时,我们只计算e和与yp相关的子标签的质心得到概率pci之间的距离。
- 其中Yc(yp)∈RNp为带有yp的子标签的集合,且Np < n,因此最终输出y为概率最大的事件标签pci。至此,步骤(x, t)→y完成了。
四联体对比学习模块(Quadruplet contrastive learning)
模糊触发器时可能会引入上下文外语义,多语言提示模块可能会在模型训练中带来额外的噪声,为了克服潜在的干扰,进一步掌握不同事件标签的细微特征,我们引入了一个四联体对比学习模块。
三个规则
- 对应的eml实例可以看作是所有类内实例中与输入实例最相似的实例。
- 具有同源子标签的类内实例比具有同源父标签但具有异源子标签的类间实例更加相似。
- 同源父标签下的类间实例比异源父标签下的类间实例更相似。
基于上述规则,我们可以构造一个四联体实例。从与初始实例的相似度降序来看,多语实例是四胞胎中第一个具有最高相似度的对比实例。下一个是类内实例(xc, tc, yc)在同源子标签yc下,然后是具有同源父标签但异源子标签yp的实例(xp, tp, yp)。与原始实例一致,后两个对比实例被输入到多语言提示模块中。然后我们可以得到相应的事件嵌入e, ec和ep,然后将它们投影到原型网络ep和ec上,生成分层原型模块中各自的子级概率分布Pc, Pc c和Pp c,以及得到的Pml 。而且,实例越相似,它们的子级概率分布越接近。
















 143
143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









