






![]()
摘要

大规模语言模型(large language models,LLMs)所展现的处理各种自然语言处理(natural language processing,NLP)任务的能力引发了广泛关注. 然而,它们在处理现实中各种复杂场景时的鲁棒性尚未得到充分探索,这对于评估模型的稳定性和可靠性尤为重要.
因此,本文使用涵盖了9个常见NLP任务的15个数据集(约147,000个原始测试样本)和来自TextFlint的61种鲁棒的文本变形方法分析GPT-3和GPT-3.5系列模型在原始数据集上的性能,以及其在不同任务和文本变形级别(字符、词和句子)上的鲁棒性. 研究结果表明,GPT模型虽然在情感分析、语义匹配等分类任务和阅读理解任务中表现出良好的性能,但其处理信息抽取任务的能力仍较为欠缺,比如其对关系抽取任务中各种关系类型存在严重混淆,甚至出现“幻觉”现象. 在鲁棒性评估实验中,GPT模型在任务层面和变形层面的鲁棒性都较弱,其中,在分类任务和句子级别的变形中鲁棒性缺乏更为显著. 此外,探究了模型迭代过程中性能和鲁棒性的变化,以及提示中的演示数量和演示内容对模型性能和鲁棒性的影响. 结果表明,随着模型的迭代过程以及上下文学习的加入,模型的性能稳步提升,但是鲁棒性依然亟待提升. 这些发现从任务类型、变形种类、提示内容等方面揭示了GPT模型还无法完全胜任常见的NLP任务,并且模型存在的鲁棒性问题难以通过提升模型性能或改变提示内容等方式解决. 通过对gpt-3.5-turbo的更新版本、gpt-4模型,以及开源模型Llama2-7b和Llama2-13b的性能和鲁棒性表现进行对比,进一步验证了实验结论. 鉴于此,未来的大模型研究应当提升模型在信息提取以及语义理解等方面的能力,并且应当在模型训练或微调阶段考虑提升鲁棒性.
![]()
内容简介

1.通过评估涵盖9个不同NLP任务的15个数据集,使用61种任务特定的变形方法,对GPT3和GPT3.5系列模型的性能和鲁棒性进行了全面分析.
2.研究结果表明,尽管GPT模型在在情感分析、语义匹配等分类任务和阅读理解任务表现出色,但在面对输入文本扰动时仍然存在明显的鲁棒性问题.
3.未来的大模型研究应当提升模型在信息提取和语义理解方面的能力,并且应当在模型训练或微调阶段考虑提升模型的鲁棒性.
亮点图文
0. 引言
为定量评估和探究大模型的能力,已有的工作集中于评估大模型在常识和逻辑推理、多语言和多模态、心智理论和数学等方面的能力. 尽管这些工作在基准测试集上取得了很好的效果,但大模型是否具备良好的鲁棒性仍然需要进一步研究.
鲁棒性衡量了模型在面对异常情况(如噪音、扰动或故意攻击)时的稳定性,这种能力在现实场景,尤其是在自动驾驶和医学诊断等安全场景下对于大模型至关重要. 然而,已有的研究主要使用对抗攻击策略,这对于大规模评估来说需要消耗大量的算力和时间;并且对抗样本生成的目标是通过对特定模型或数据集的原始输入进行微小的扰动,以误导模型的分类或生成结果,但这些扰动并不总是代表真实世界中的威胁和攻击方式. 此外,现有研究大多针对ChatGPT及同时期的其他大模型,对GPT系列模型迭代过程中性能和鲁棒性的变化关注较少.
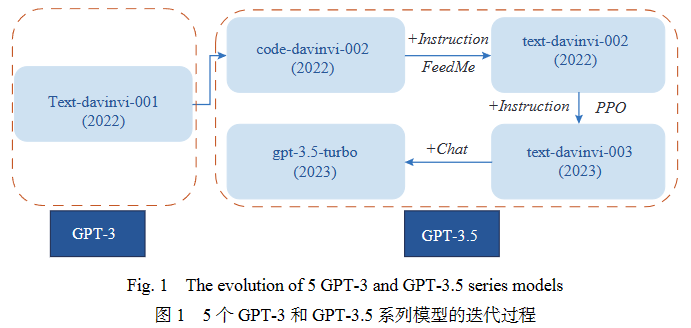
鉴于此,本文选择了图1所示的5个GPT-3和GPT-3.5系列模型作为大模型的代表,通过全面的实验分析其性能和鲁棒性.
本文的定量结果和定性分析表明:
1)GPT模型在情感分析、语义匹配等分类任务和阅读理解任务中表现出较优异的性能,但在信息抽取任务中性能较差. 例如,其严重混淆了关系抽取任务中的各种关系类型,甚至出现了“幻觉”现象.
2)在处理被扰动的输入文本时,GPT模型的鲁棒性较弱,它们在分类任务和句子级别变形中鲁棒性缺乏更为显著.
3)随着GPT系列模型的迭代,其在NLP任务上的性能稳步提升,但是鲁棒性并未增强. 除情感分析任务外,模型在其余任务上的鲁棒性均未明显提升,甚至出现显著波动.
4)随着提示中演示数量的增加,GPT模型的性能提升,但模型鲁棒性仍然亟待增强;演示内容的改变可以一定程度上增强模型的抗扰动能力,但未能从根本上解决鲁棒性问题.
同时,通过对gpt-3.5-turbo的更新版本、gpt-4、开源模型Llama2-7b和Llama2-13b的表现进行评估,本文进一步验证了上述实验结论的普适性和可持续性.
1. 相关工作
已有的关于大模型鲁棒性的工作主要集中于两个方面:对抗鲁棒性和分布外鲁棒性. 对抗鲁棒性是指模型在抗样本上的鲁棒性表现,对抗样本的生成方式为:对原始输入施加一个阈值范围内的微小扰动,使得模型的分类或生成结果发生变化. 分布外鲁棒性关注于模型的泛化性,即使用与模型训练数据存在分布偏移的数据,包括跨域或跨时间数据,进行鲁棒性评测. 然而,对抗样本的数据是以欺骗模型为目的而生成的,与现实场景中产生的噪音和扰动存在明显差异,并且生成对抗样本需要消耗大量算力和时间,不适合进行大规模评测. 本文通过考虑更广泛的使用场景,从输入文本的角度出发,利用任务特定的文本变形来评估大模型在每个任务中的鲁棒性表现,从而进行更全面的分析. 此外,本文关注于GPT系列的多个模型的表现,分析了它们在迭代过程中性能和鲁棒性方面的变化.
2. 数据集和模型
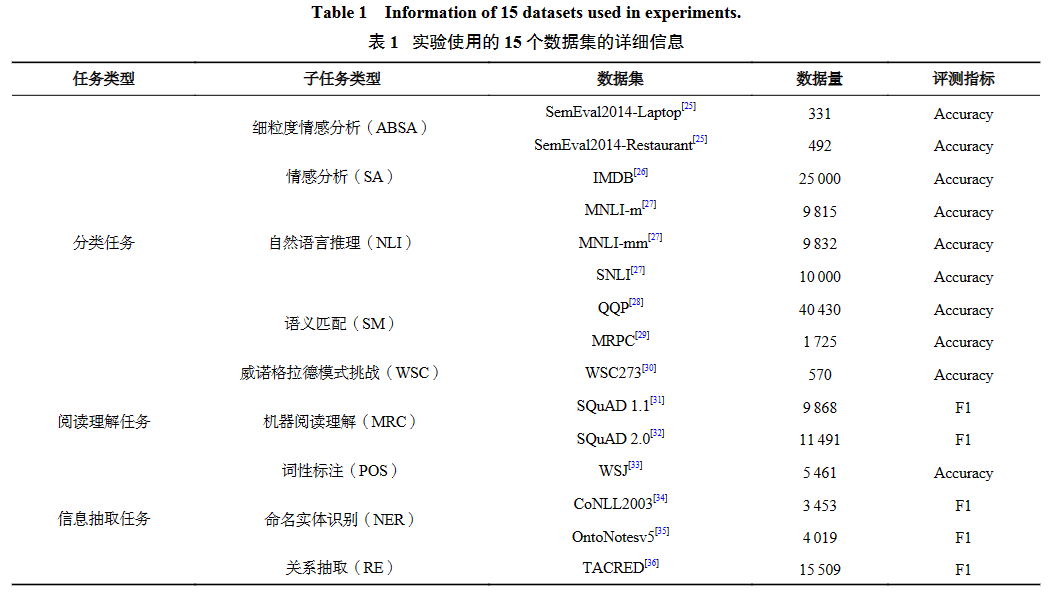
为了全面评估GPT模型在各类自然语言处理任务上的表现,如表1所示,本文选取了9个常见的自然语言处理任务,涵盖分类、阅读理解和信息抽取3个不同类别. 针对每个任务,本文选取了具有代表性的公开数据集进行测试,最终共包含15个不同数据集.
根据图1所示,本文主要针对5个GPT-3和GPT-3.5系列模型进行评估和分析,并对GPT-4模型在零样本场景下进行抽样测试,所有模型都通过OpenAI官方API 进行评估. 根据OpenAI官方文档的说明, text-davinci-002是基于code-davinci-002的InstructGPT模型,其使用了FeedME方法(一种监督式微调策略)进行训练;Text-davinci-003是text-davinci-002的改进版本,其使用近端优化策略(proximal policy optimization,PPO)算法进行训练,该算法被用于基于人类反馈的强化学习(reinforcement learning from human feedback, RLHF);GPT-3.5-turbo是针对聊天场景进行优化的最强大的GPT-3.5模型(本文第3~5节所使用的版本均为gpt-3.5-turbo-0301版本).
3. 性能评测
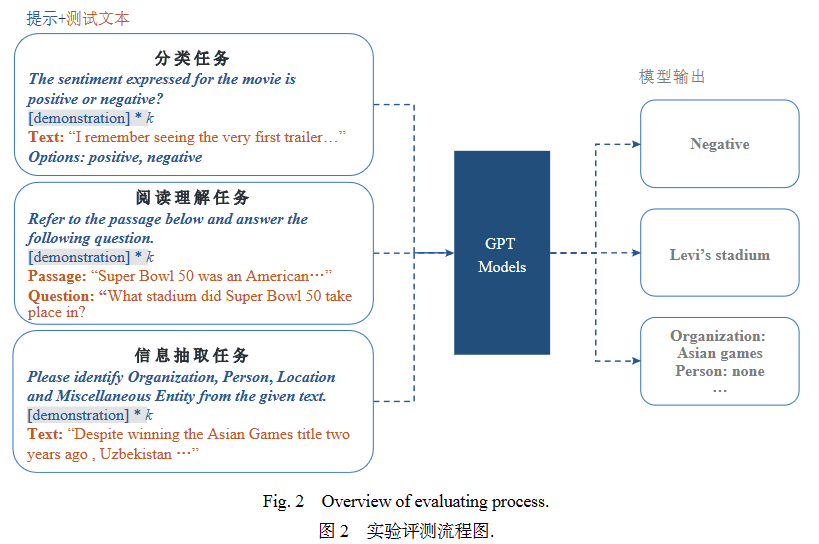
大模型可以通过输入适当的提示或指令来执行各种任务,而无需修改任何参数. 为评估GPT模型在NLP任务中的性能,本文针对每个具体任务设计了3种不同的提示. 如图2所示,本文将提示与测试文本拼接起来作为测试样本输入模型,并获得相应的输出,通过对输出结果的定量评估来评测模型的性能.
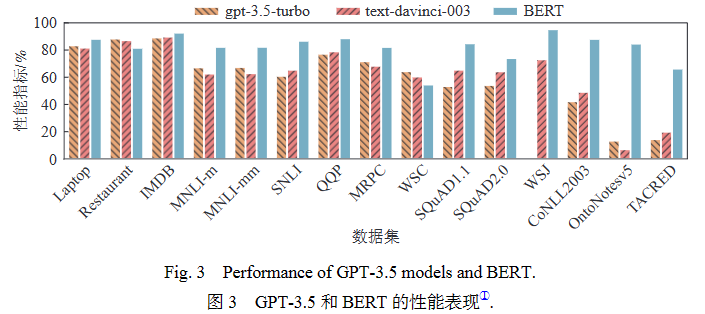
首先分析两个最新的GPT-3.5模型(即gpt-3.5-turbo和text-davinci-003模型)的性能表现. 其和BERT在15个数据集上的性能表现如图3所示,图中的数据是每个数据集在3个提示下的性能均值. 结果表明,GPT模型的零样本性能在情感分析、语义匹配、机器阅读理解等分类任务和阅读理解任务中可以与BERT相媲美,并且在SemEval2014-Restaurant和WSC数据集上的表现优于BERT.
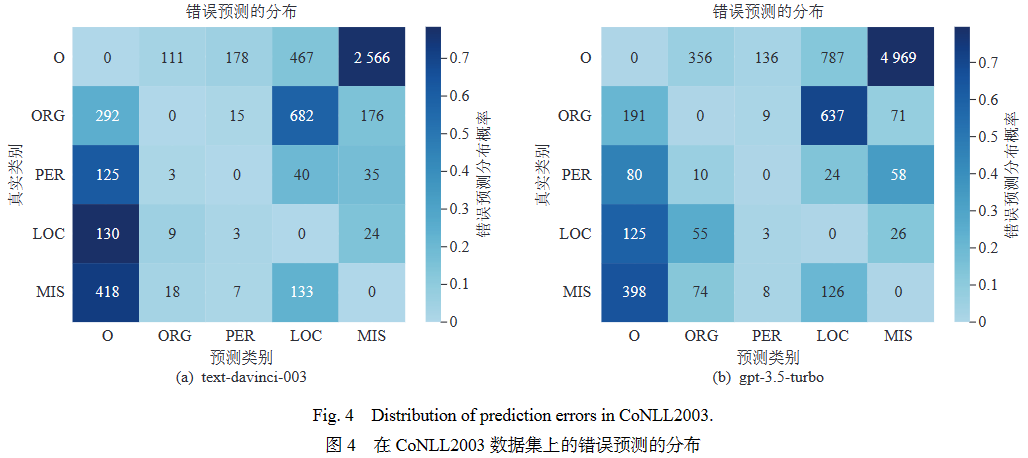
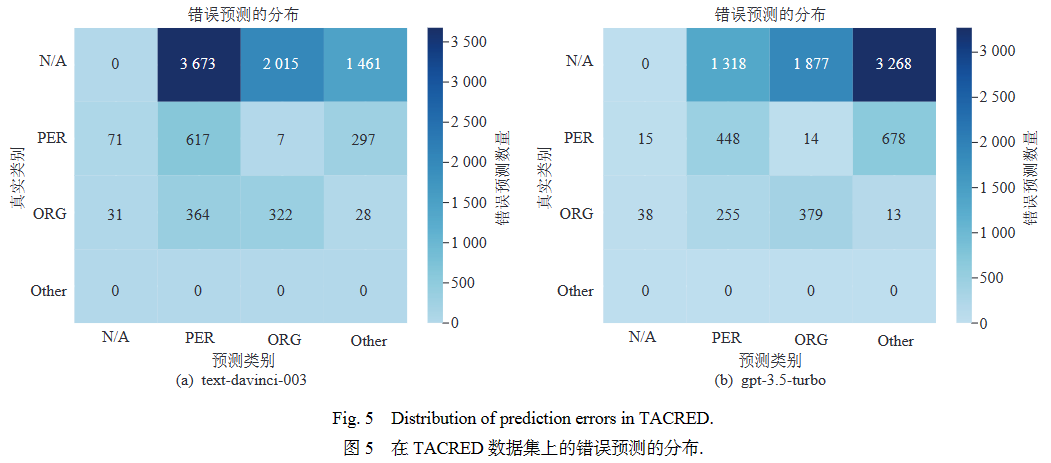
然而,GPT模型在命名实体识别(NER)和关系抽取(RE)任务上表现不佳. 为深入了解模型错误预测背后的原因,本文选择CoNLL2003和TACRED数据集作为代表,分析了错误预测的分布情况. 图4第一列表示在CONLL2003数据集的预测结果中,实体类型被错误预测为“非实体”类型(即“O”)的数量. 结果表明,在NER任务中,大多数错误预测来自于“O”标签与特定实体类型的混淆,这表明大模型对实体词缺乏敏感性;在RE任务中,如图5的第一行所示,GPT模型倾向于将“无关系”实例(即“N/A”)错误分类为特定的关系类型.
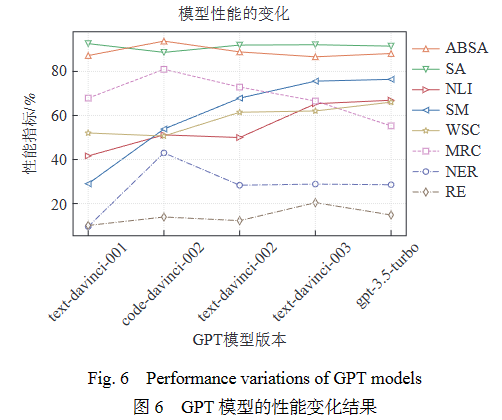
此外,如图6所示,本文按照OpenAI官方发布模型的时间顺序和迭代关系(图1),评测了GPT-3和GPT-3.5系列模型在迭代过程中性能的变化. 由于测试数据较多,本文按照表1所示的子任务类型进行结果展示,每个子任务的数值为其包含数据集的结果均值. 结果表明,随着模型发布时间的推移,GPT模型在大多数NLP任务上的性能稳步提升. 其中,GPT模型在情感分析(SA)和细粒度情感分析(ABSA)任务上保持了较高的性能,并在自然语言推理(NLI)、语义匹配(SM)和威诺格拉德模式挑战(WSC)任务上有显著的性能提升,但在NER和RE任务上的性能一直处于较低水平.
4. 鲁棒性研究
如表2所示,本节使用TextFlint提供的61种任务特定的变形来评测模型的鲁棒性. 如图2所示,每种变形均已通过TextFlint提供的变形规则作用于原始数据,从而生成变形数据. 本文通过将提示与变形数据拼接起来,作为测试文本输入模型并获得相应输出.

TextFlint提供的变形是基于语言学并针对不同的NLP任务设计的,在保持变形文本的可接受性的同时,能够更好地代表实际应用中的挑战. 本节中,根据变形的粒度,将变形分为句子级别、词级别和字符级别. 表3展示了不同类型的变形样例.

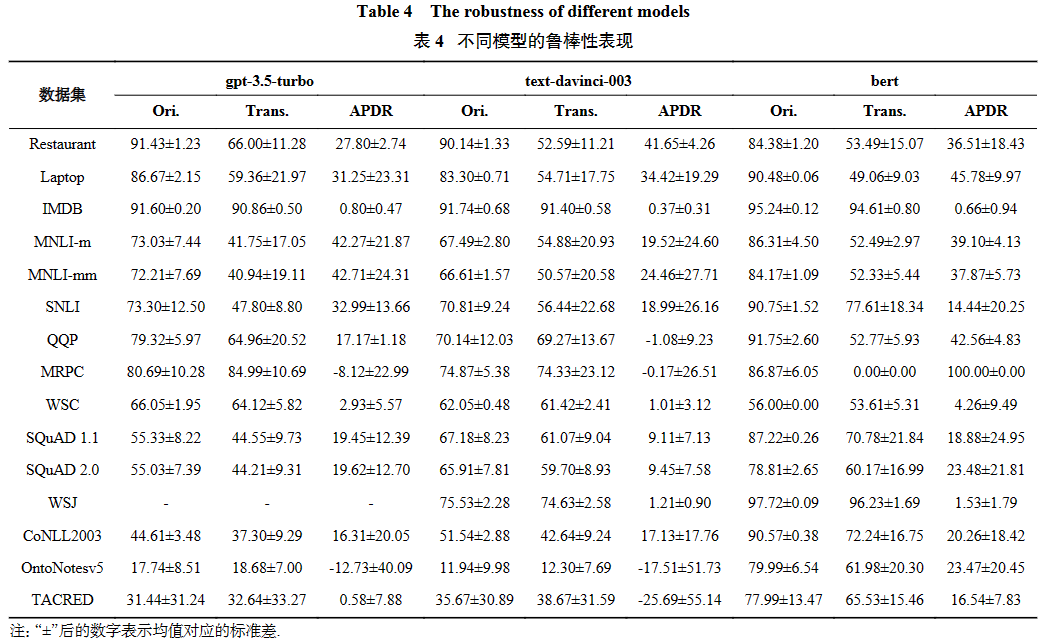
表4列出了模型每个数据集上的平均结果. 具体而言,本文定义
![]()
为PDR(公式1)在不同数据集上的平均值定义为:
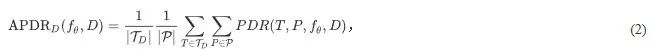
其中,
![]()
表示特定数据集D包含的任务特定变形的集合,
![]()
表示3个提示的集合.
表4结果表明,GPT模型的表现与BERT类似,其在分类任务中出现了显著的性能下降. 例如,gpt-3.5-turbo在MNLI-mm数据集上的绝对性能下降了42.71%,而text-davinci-003在SemEval2014-Restaurant数据集上的绝对性能下降了41.65%.
此外,随着迭代的进行,GPT系列模型在不同任务上平均性能下降率的变化如图7所示. 由于不同模型间的结果波动较大,图7的纵坐标数值为经过对数变换之后的结果. 平均性能下降率越小,代表模型的鲁棒性越好,但图中的结果没有呈现出一致的趋势. 在ABSA和MRC任务中,模型间的鲁棒性表现较为相似;在SA任务上出现了较显著的鲁棒性提升;但是在其余任务中均呈现出显著的波动,并且没有出现鲁棒性显著提升的情况. 这可能表明GPT模型的迭代过程主要集中于改进模型在一般场景下的性能,而非解决鲁棒性问题.
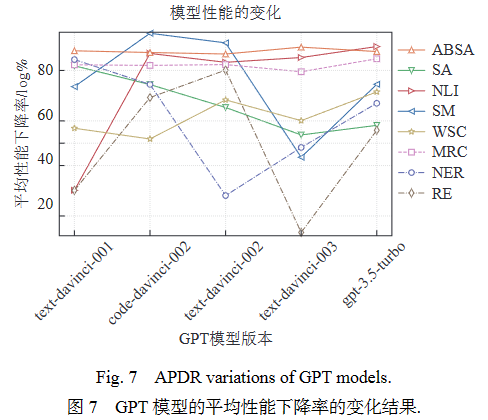
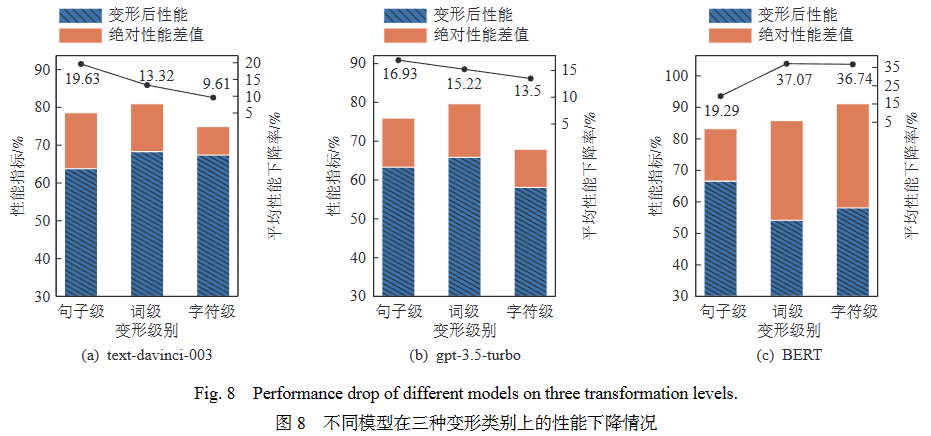
图8为GPT模型在3种变形级别上的性能下降情况. 其中蓝色部分(斜杠)表示模型的原始性能,橙色部分表示变形后性能与原始性能的差值,黑色圆点表示平均性能下降率(APDR). 通过计算每个变形级别下的PDR的均值得到
![]()
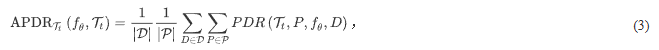
其中,
![]()
表示某个变形类别t的变形集合,
![]()
表示提示的集合.
根据图8所示,GPT模型的平均性能下降率在句子、词、字符三个变形类别上逐级递减,即处理句子级别的变形文本时,GPT模型在变形前后的性能下降更为显著. 句子级别的变形通常涉及语义的重新表述或句子整体结构的改变,这对模型稳定性有更高的要求. 此外,GPT模型在字符级和词级变形上表现出比BERT更好的鲁棒性. GPT模型的平均性能下降范围为9.61%至15.22%,而BERT的性能下降分别为36.74%和37.07%. 可以看出,与监督微调模型相比,GPT模型对细粒度扰动表现出更强的稳定性.
5. 性能和鲁棒性影响因素
图9所示的蓝色柱子表示原始性能,红色柱子表示变形后的性能. 颜色越深代表演示数量越多. 图9结果表明,增加演示数量通常会带来性能的提升. 此外,从零样本增加为少样本的情况下,模型性能提升显著,特别是对于一开始在零样本情景下表现不佳的任务,如信息抽取任务. 此外,随着演示数量的增加,不同GPT模型之间的性能差异减小.
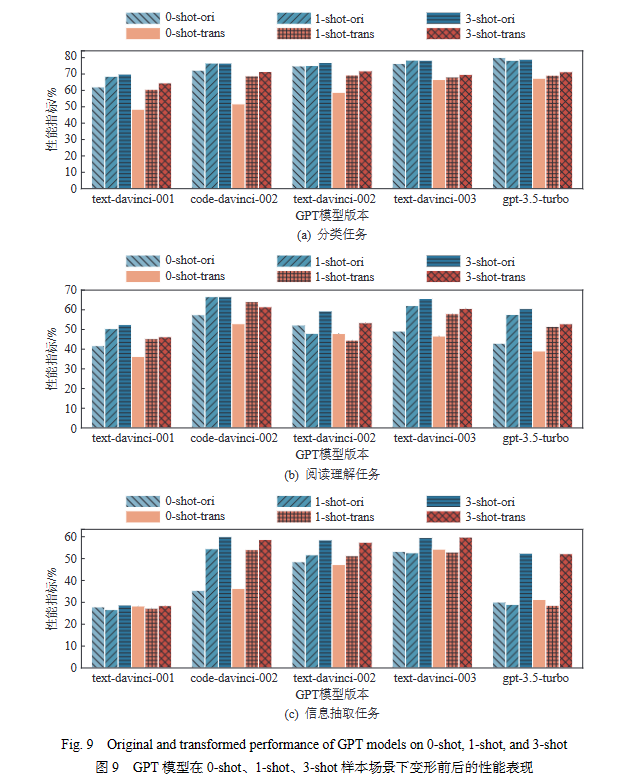
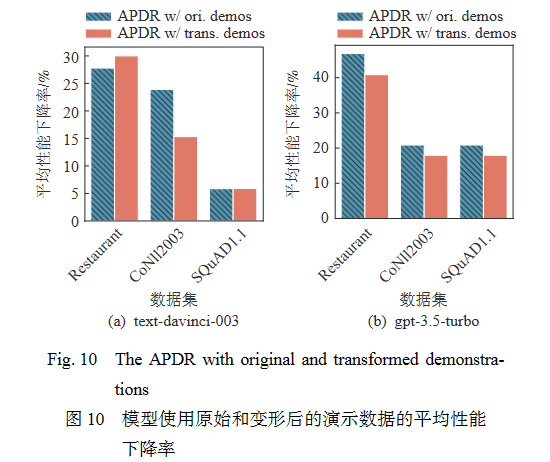
图10展示了变形前后模型的平均性能下降率,蓝色部分代表使用原始演示样例时的结果,红色部分表示使用变形后的演示样例时的结果. 该数值越低,表示性能下降越少,模型稳定性越好. 结果表明,在演示中使用变形后的样本有助于缓解模型变形后的性能下降,说明演示中包含的扰动信息能够帮助模型更好地处理变形数据. 但是,平均性能下降率依然处于较高的数值,这表明这种性能改善是有限的,不足以从根本上解决模型的鲁棒性问题.
6. 讨论
如图11所示,根据模型更新与迭代顺序,gpt-3.5-turbo-0613和gpt-4模型在大部分数据集上的性能出现较为显著的提升. 其中,在阅读理解的数据集中,两个模型的提升最为显著. 第3节中的结果表明GPT模型在NER和RE上表现不佳,图11的结果表明gpt-3.5-turbo-0613和gpt-4模型在NER任务的Ontonotesv5及RE任务的TACRED数据集上的表现仍然处于较低水平.
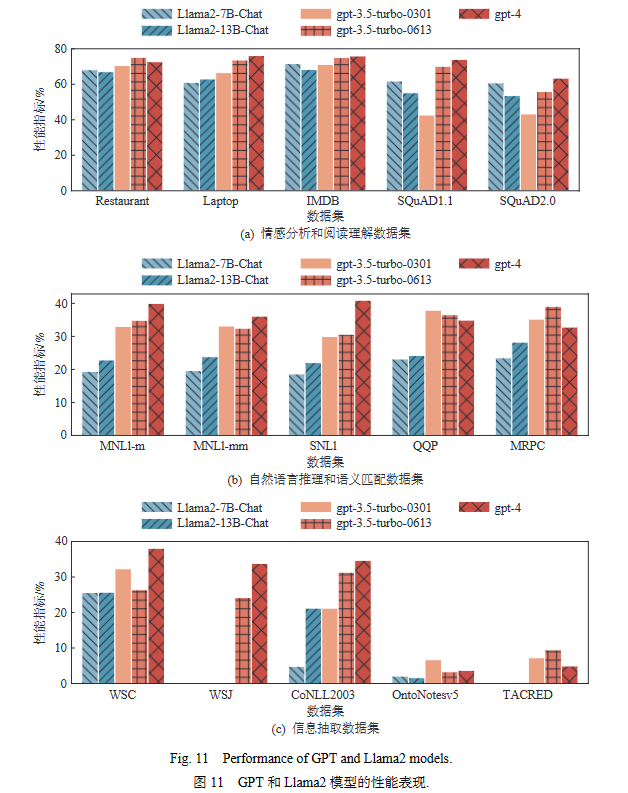
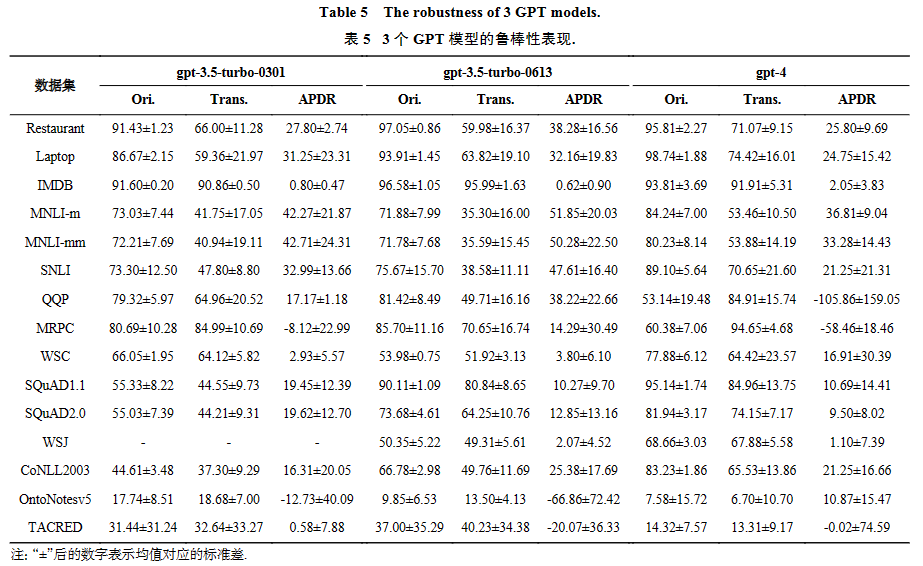
表5展示了3个模型的鲁棒性表现. 如表5所示, GPT模型仍然存在4.3节中提到的鲁棒性问题,尤其在分类任务中存在显著的性能下降. 值得注意的是,在阅读理解任务中gpt-3.5-turbo-0613和gpt-4 的鲁棒性进一步提升,表现出在该任务上较高的稳定的. 同时,gpt-3.5-turbo的版本迭代未带来稳定的鲁棒性提升,而gpt-4的鲁棒性在大多任务上都优于GPT-3.5系列模型.
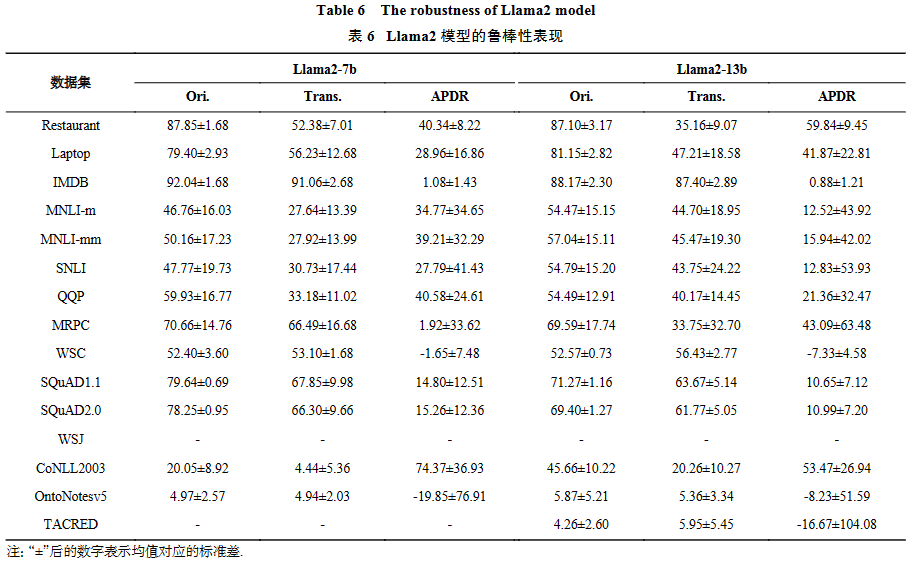
如表6所示,与GPT系列模型的鲁棒性表现类似,Llama2-7b和Llama2-13b在大多分类任务上的性能下降都较为严重,但在阅读理解任务中的鲁棒性与gpt-4相当,且好于GPT-3.5系列模型. 同时,Llama2-13b比Llama2-7b具有更好的鲁棒性.
总结
本文通过评估涵盖9个不同NLP任务的15个数据集,使用61种任务特定的变形方法,对GPT3和GPT3.5系列模型的性能和鲁棒性进行了全面分析. 研究结果表明,尽管GPT模型在在情感分析、语义匹配等分类任务和阅读理解任务表现出色,但在面对输入文本扰动时仍然存在明显的鲁棒性问题. 其中,本文分别从任务层面和变形级别层面具体分析了GPT模型的鲁棒性表现,表明其在分类任务和句子级变形中鲁棒性亟待提升. 同时,随着GPT系列模型的迭代,其性能在大多任务上稳步提升,但鲁棒性依然面临很大的挑战. 此外,本文探讨了提示对GPT模型的性能和鲁棒性的影响,包括提示中演示数量和演示内容两方面. 这些发现从任务类型、变形种类、提示内容等方面揭示了 GPT模型还无法完全胜任常见的 NLP任务,并且模型存在的鲁棒性问题难以通过提升模型性能或改变提示内容等方式解决. 与此同时,本文通过评估gpt-3.5-turbo的更新版本、gpt-4模型,以及开源模型Llama2-7b和Llama2-13b的性能和鲁棒性表现,进一步验证了实验结论. 鉴于此,未来的大模型研究应当提升模型在信息提取和语义理解方面的能力,并且应当在模型训练或微调阶段考虑提升模型的鲁棒性.
















 93
93

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











