







导读
生成式 AI 正在以前所未有的速度改变着软件开发的格局,从智能助手到内容创作,从数据分析到教育辅导,其应用场景不断拓展,为各行业带来了前所未有的机遇。然而,将生成式 AI 集成到现有应用中往往需要复杂的开发工作,涉及大量的基础设施搭建、模型选择与调优、数据处理与向量化等繁琐步骤,这对于大多数开发团队来说是一个巨大的挑战。QuivrHQ 团队推出的 Quivr 正是为了应对这些挑战而生,它是一款 opinionated 的 RAG(Retrieval-Augmented Generation,检索增强生成)工具,旨在帮助开发者轻松地将生成式 AI 集成到他们的应用中,让团队能够专注于自身产品的核心价值,而非 RAG 的底层实现。
目录
RAG(Retrieval-Augmented Generation)简介
摘要
Quivr 是一款简化生成式 AI 应用开发的 RAG 工具,它提供了简单易用的 API 和丰富的配置选项,支持多种大型语言模型(LLM)和向量数据库,能够处理各种文件格式,并且可以灵活地集成到现有的应用架构中。本文将深入探讨 Quivr 的核心概念、功能特点、架构设计、应用场景以及使用方法,并结合实际示例进行演示,帮助读者全面了解 Quivr 的强大功能和便捷性。
概念讲解
RAG(Retrieval-Augmented Generation)简介
RAG 是一种结合了检索(Retrieval)和生成(Generation)的技术范式。在传统的生成模型中,模型仅依据输入提示进行内容创作,而 RAG 则通过从大规模文档或数据中检索相关信息,为生成模型提供上下文支持,从而生成更准确、更可靠的输出。这种技术特别适用于需要精确信息引用的场景,例如文档问答、知识库查询、智能客服等。
Quivr 的核心概念
-
Opinionated RAG :Quivr 作为 opinionated 的 RAG 工具,提供了一套经过精选和优化的组件、流程和最佳实践,旨在帮助开发者快速上手并高效地构建生成式 AI 应用。它对底层的技术选型和实现细节进行了合理的抽象和封装,使开发者无需深入了解复杂的 RAG 实现原理,即可轻松地将生成式 AI 集成到自己的产品中。
-
LLM(Large Language Model)集成 :Quivr 支持多种主流的大型语言模型,如 GPT-4、Groq 和 Llama 等。这使得开发者可以根据自身需求和应用场景选择最适合的模型,充分发挥不同模型的优势,为应用提供强大的语言理解和生成能力。
-
向量数据库支持 :Quivr 兼容多种向量数据库,包括 PGVector 和 Faiss 等。向量数据库用于存储和检索高维向量数据,如文本嵌入向量,能够快速找到与用户查询最相似的文档片段或数据,为生成模型提供准确的上下文信息。
-
文件处理与数据摄取 :Quivr 支持处理各种文件格式,开发者可以方便地将文档、表格、图片等文件中的内容摄取到系统中,进行进一步的处理和利用,满足不同应用场景下的数据需求。
架构设计
架构图
以下是 Quivr 的架构图:
Quivr 的架构主要由以下几个模块组成:
-
API 网关 :提供统一的入口,接收和处理来自客户端的请求,进行身份验证、请求路由和负载均衡等操作,将请求分发到相应的后端服务。
-
前端界面 :基于 React 构建的现代化用户界面,提供友好的操作体验,方便用户进行文件上传、查询提交、结果查看等操作。界面设计简洁直观,易于上手。
-
后端服务 :处理业务逻辑,包括文件管理、数据处理、向量嵌入生成、检索查询等。它与向量数据库和其他后端组件进行交互,协调各模块的工作流程,确保系统的高效运行。
-
向量数据库 :用于存储和检索文本嵌入向量等高维数据,支持高效的相似性搜索。Quivr 支持多种向量数据库,如 PGVector 和 Faiss,开发者可以根据实际需求选择合适的数据库。
-
LLM 服务 :集成大型语言模型,根据检索到的上下文信息生成最终的输出结果。Quivr 支持多种 LLM,开发者可以灵活选择并配置模型参数。
流程图
以下是 Quivr 的工作流程图:
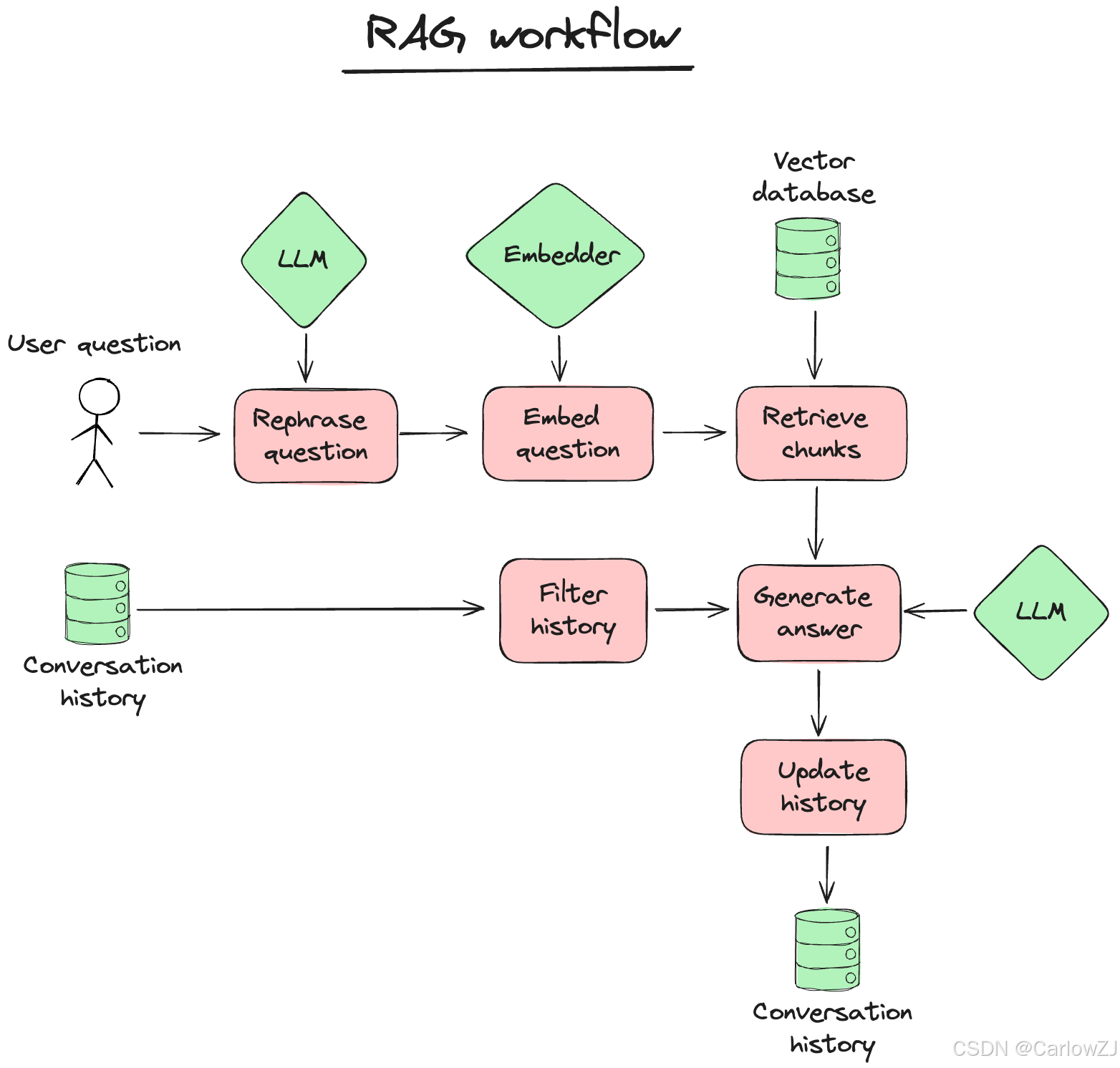
Quivr 的工作流程主要包括以下几个步骤:
-
文件上传与预处理 :用户通过前端界面上传各种格式的文件,后端服务接收文件并对文件内容进行预处理,如文本提取、格式转换等操作。
-
数据分割与嵌入生成 :将预处理后的数据进行分割,生成适合向量化的数据片段。然后,利用嵌入模型将这些片段转换为高维向量表示,生成文本嵌入向量。
-
向量存储 :将生成的向量数据存储到向量数据库中。向量数据库对向量数据进行索引和优化,以便后续的快速检索。
-
用户请求处理 :用户通过前端界面提交查询请求,API 网关将请求转发到后端服务。
-
相似性检索 :后端服务根据用户查询,从向量数据库中检索出与查询最相似的向量数据,获取相关的上下文信息。
-
结果生成与返回 :将检索到的上下文信息传递给集成的 LLM,由 LLM 根据上下文生成最终的输出结果,并通过 API 网关将结果返回给前端界面展示给用户。
功能特点
简单易用的 API
Quivr 提供了一套简单易用的 RESTful API,开发者可以轻松地将 Quivr 集成到现有的应用中。以下是一些常见的 API 示例:
-
文件上传 API :允许用户上传各种文件,如文档、表格、图片等,Quivr 会自动处理文件内容并将其存储到向量数据库中。
-
查询 API :用户提交查询请求,Quivr 根据查询内容从向量数据库中检索相关信息,并调用 LLM 生成答案返回给用户。
-
数据管理 API :提供文件管理、数据更新、向量索引维护等功能,方便开发者对数据进行管理和维护。
丰富的配置选项
Quivr 提供了丰富的配置选项,开发者可以根据自身需求对系统进行灵活的配置。例如:
-
模型配置 :可以选择不同的 LLM 和嵌入模型,配置模型的参数,如温度值、最大生成长度等,以满足不同的应用场景和性能要求。
-
数据库配置 :支持多种向量数据库,开发者可以根据实际需求选择合适的数据库,并配置数据库的连接信息、索引参数等。
-
检索配置 :可以调整检索的相似度阈值、返回结果数量等参数,优化检索效果和性能。
多文件格式支持
Quivr 支持处理多种文件格式,如 PDF、DOCX、XLSX、PPTX、TXT 等,能够自动提取文件中的文本内容并进行处理。这使得开发者可以方便地将各种文档中的知识和信息集成到应用中,丰富应用的知识库。
实时更新与增量学习
Quivr 支持实时更新知识库,当有新的文件或数据添加时,系统可以自动检测并更新向量数据库,使知识库始终保持最新状态。同时,Quivr 还支持增量学习,开发者可以定期对模型进行再训练,以提升模型的性能和准确性。
代码示例
环境准备
在开始使用 Quivr 之前,确保已经安装了以下依赖:
-
Node.js :建议使用 >= 18.15.0 的版本。
-
Python :用于运行一些数据处理和模型相关的脚本。
-
Docker :方便进行环境搭建和部署,确保 Docker 和 Docker Compose 已正确安装。
安装与部署
使用 Docker 部署
以下是使用 Docker 部署 Quivr 的代码示例:
# 克隆 Quivr 仓库
git clone https://github.com/QuivrHQ/quivr.git
cd quivr
# 构建 Docker 镜像
docker-compose build
# 启动服务
docker-compose up -d本地安装
如果需要在本地进行开发,可以按照以下步骤安装:
# 克隆仓库
git clone https://github.com/QuivrHQ/quivr.git
cd quivr
# 安装依赖
npm install
# 初始化数据库(如果需要)
npm run init-db
# 启动服务
npm start文件上传与处理
以下是一个使用 Python 脚本上传文件到 Quivr 的示例:
import requests
# 设置 API 地址和文件路径
api_url = "http://localhost:3000/api/upload"
file_path = "/path/to/your/file.pdf"
# 发送 POST 请求上传文件
with open(file_path, "rb") as file:
response = requests.post(api_url, files={"file": file})
# 检查响应结果
if response.status_code == 200:
print("文件上传成功!")
else:
print(f"文件上传失败,错误信息:{response.text}")提交查询请求
以下是如何使用 JavaScript 在前端页面中提交查询请求的示例:
JavaScript
// 设置 API 地址和查询参数
const api_url = "http://localhost:3000/api/query";
const query = "你的查询内容";
// 发送 POST 请求提交查询
fetch(api_url, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ query: query }),
})
.then((response) => response.json())
.then((data) => {
console.log("查询结果:", data);
// 在页面上显示查询结果
document.getElementById("result-container").innerHTML = data.answer;
})
.catch((error) => {
console.error("查询失败:", error);
});应用场景
智能客服系统
在智能客服领域,Quivr 可以帮助企业在多个渠道提供 24/7 的自动化客户服务。通过集成 Quivr,智能客服系统可以从大量的历史对话记录、产品文档、常见问题解答等资料中检索相关信息,快速准确地回答客户的问题,提高客户满意度和运营效率。例如,某电商平台利用 Quivr 构建智能客服,能够自动回答用户关于产品信息、订单状态、退换货政策等问题,减少了人工客服的工作量,提升了客户体验。
企业知识库
Quivr 适用于构建企业内部的知识库,帮助员工快速查找和利用企业内部的文档、资料和数据。企业可以将各种内部文档、报告、邮件等文件上传到 Quivr,员工可以通过简单的查询获取所需的信息,提高工作效率和知识共享程度。例如,某科技公司使用 Quivr 搭建企业知识库,员工可以方便地查询技术文档、项目资料、会议纪要等内容,促进了团队协作和知识传承。
教育辅导工具
在教育领域,Quivr 可以用于开发智能辅导工具,为学生提供个性化的学习支持。通过集成教材、讲义、习题等教育资源,Quivr 能够根据学生的问题提供详细的解答和学习建议,帮助学生更好地理解和掌握知识。例如,某教育机构利用 Quivr 开发了一款智能学习助手,学生可以随时向助手提问,助手会结合教材内容和知识点为学生提供准确的答案和讲解,辅助学生的学习过程。
智能文档助手
Quivr 可以作为智能文档助手,帮助用户快速理解和处理各种文档。用户只需将文档上传到 Quivr,即可通过自然语言查询获取文档中的关键信息、摘要、特定内容等。例如,某律所开发了基于 Quivr 的智能文档助手,律师可以快速查询合同文件中的关键条款、法律条文等内容,提高工作效率和准确性。
数据分析与报告生成
在数据分析和报告生成方面,Quivr 可以根据用户提供的数据和查询要求,自动生成分析报告和可视化结果。通过集成数据分析工具和数据源,Quivr 能够快速检索相关数据,利用 LLM 生成专业的分析报告和解读,为决策提供支持。例如,某市场调研公司利用 Quivr 构建数据分析平台,能够根据市场数据生成市场趋势分析报告、竞品分析报告等,为客户提供有价值的市场洞察。
注意事项
硬件资源要求
Quivr 对硬件资源有一定要求,建议配置如下:
-
CPU :至少 4 核心,推荐 8 核心或以上。
-
内存 :至少 16 GB,推荐 32 GB 或以上。
-
存储 :至少 50 GB 空闲空间,具体需求根据数据量而定。
-
GPU (可选):如果使用支持 GPU 加速的 LLM 或嵌入模型,可以显著提升性能。
数据隐私与安全
由于 Quivr 会处理大量的文档和数据,涉及到数据隐私和安全问题。开发者需要采取适当的措施来保护数据,如使用加密传输、存储敏感数据、设置访问权限等。确保只有授权用户可以访问和操作数据,防止数据泄露和未授权访问。
模型选择与调优
Quivr 支持多种 LLM 和嵌入模型,不同的模型在性能、准确性和资源消耗等方面存在差异。开发者需要根据实际应用场景和需求选择合适的模型,并进行适当的调优,以达到最佳的性能和效果。同时,要关注模型的更新和升级,及时更新模型以获取更好的性能和功能。
向量数据库的维护
向量数据库的性能和效率对 Quivr 的整体表现至关重要。开发者需要定期维护向量数据库,如优化索引、清理无用数据、监控数据库性能等,确保数据库的高效运行。根据实际情况合理调整数据库的配置参数,以满足应用的检索性能要求。
错误处理与日志记录
在使用 Quivr 的过程中,可能会出现各种错误和异常情况,如文件上传失败、查询超时、模型推理错误等。开发者需要实现完善的错误处理机制,及时捕获和处理错误,并向用户反馈友好的错误信息。同时,启用日志记录功能,记录系统的运行状态、请求处理过程、错误详情等信息,便于问题的排查和分析,有助于及时发现和解决问题。
总结
Quivr 作为一款 opinionated 的 RAG 工具,凭借其简单易用的 API、丰富的配置选项、多文件格式支持以及灵活的架构设计,为开发者提供了一种高效、便捷的方式来将生成式 AI 集成到应用中。它降低了开发门槛,节省了开发时间和成本,使开发者能够专注于自身产品的核心价值和创新。无论是构建智能客服、企业知识库、教育辅导工具,还是开发智能文档助手、数据分析平台等应用,Quivr 都能够提供强大的支持和功能。随着生成式 AI 技术的不断发展和应用场景的不断拓展,Quivr 必将在未来发挥更加重要的作用,推动各行业的智能化发展。
引用
-
Quivr 是一款 opinionated 的 RAG 工具,旨在帮助开发者轻松地将生成式 AI 集成到他们的应用中。它提供了简单易用的 API 和丰富的配置选项,支持多种大型语言模型和向量数据库,能够处理各种文件格式,并且可以灵活地集成到现有的应用架构中。
-
详细介绍了 Quivr 的安装部署、API 使用、配置选项、模型集成等方面的内容,为开发者提供了全面的指导和参考。
-
介绍了 GPT-4 模型的功能、特点、使用方法和限制等信息,为开发者使用 GPT-4 进行开发提供了官方指导。
-
提供了 Groq 模型的相关信息和资源,包括模型架构、性能特点、应用场景等,帮助开发者了解和使用 Groq 模型。
-
介绍了 Llama 模型系列的详细信息,包括模型版本、训练数据、性能表现等,为开发者选择和使用 Llama 模型提供了参考。
-
描述了 PGVector 的安装、使用方法和功能特点,为开发者将 PGVector 用作 Quivr 的向量数据库提供了技术指导。
-
详细介绍了 Faiss 的基本原理、功能特性、安装步骤和使用示例,帮助开发者理解和应用 Faiss 作为向量数据库。



















 1801
1801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











