






构建时间序列的支付单量预测模型通常涉及以下步骤:
-
数据收集与清洗:
-
收集历史支付单量数据。
-
清洗数据,包括处理缺失值、异常值和重复记录。
-
确保数据的一致性,例如统一支付时间戳的格式。
-
-
数据探索与分析:
-
进行描述性统计分析以了解数据的基本特征。
-
绘制时间序列图,观察数据的季节性、趋势和周期性。
result = seasonal_decompose(data['value'], model='additive') result.plot() plt.show()如何判断使用加法模型还是乘法模型分解?
选择哪种模型取决于数据的特点和业务需求。以下是一些建议:
-
观察数据的趋势和季节性成分:如果数据的季节性成分在不同趋势水平下保持稳定,那么加法模型可能更合适。如果数据的季节性成分随着趋势的变化而变化,那么乘法模型可能更合适。
-
检查数据的残差:在拟合加法或乘法模型后,检查残差以确定哪个模型更好地捕捉了数据中的规律。如果残差呈现出随机分布,那么所选模型可能更合适。
-
考虑业务背景:根据业务需求和对数据的理解,选择更适合的模型。例如,在销售额预测中,乘法模型可能更合适,因为销售额的季节性波动可能随着市场环境的变化而变化。
-
计算自相关和偏自相关函数,以识别数据中的潜在相关性。
# 计算自相关函数 acf_values = acf(data['value']) # 计算偏自相关函数 pacf_values = pacf(data['value']) # 绘制自相关和偏自相关函数图 plot_acf(data['value']) plot_pacf(data['value']) plt.show()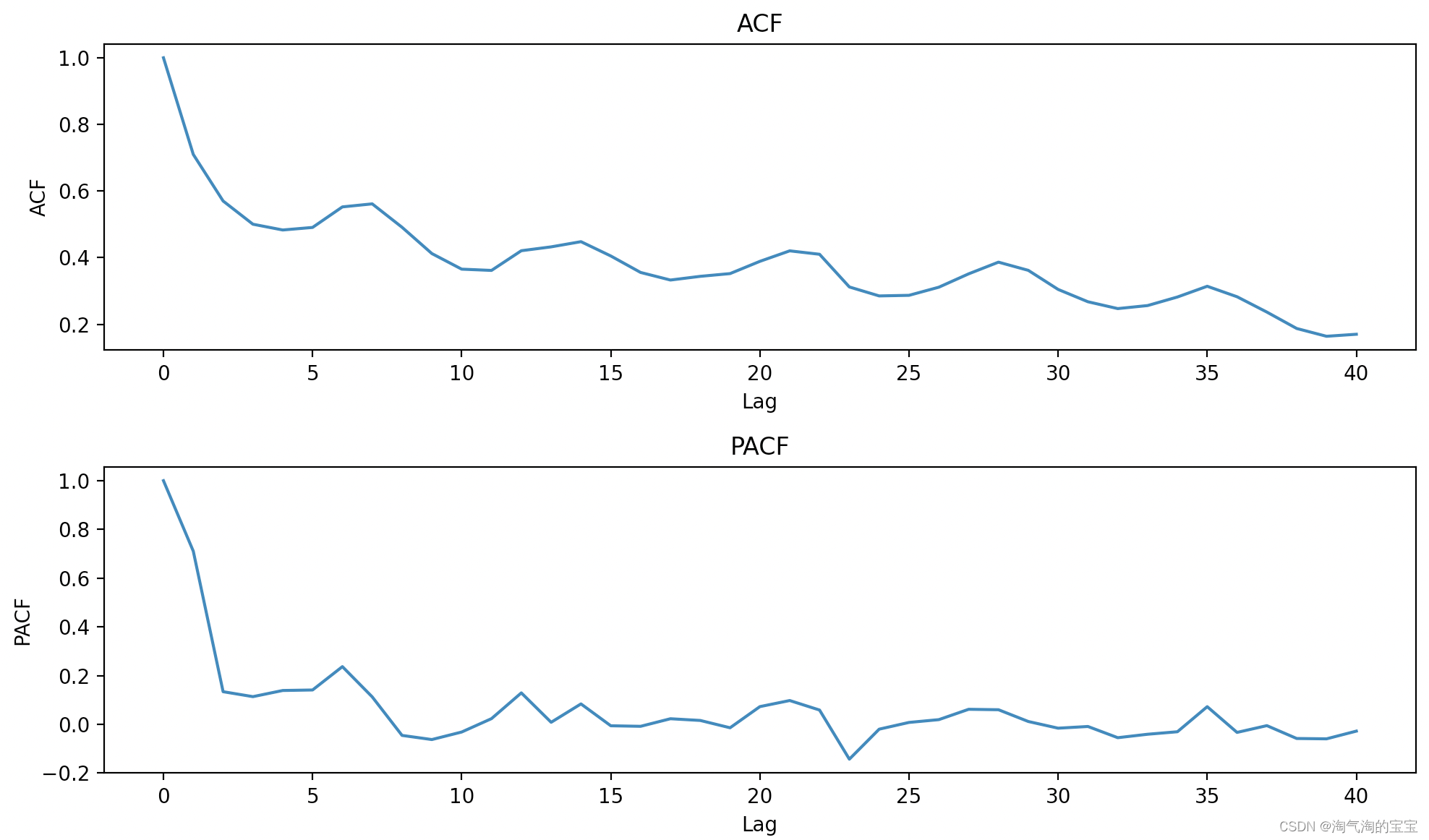

-
自相关函数(ACF):
- 自相关系数可以理解为将一列数据按照滞后数拆分成两列,然后计算这两列数据之间的相关系数。它衡量的是当前观测值与其之前观测值之间的相关性。
- ACF图像中的每个点代表不同滞后期数的自相关系数。如果某个滞后期的自相关系数显著不为0,则表明在该滞后期存在自相关性。
-
偏自相关函数(PACF):
- 偏自相关函数表示在给定中间观测值为条件时,当前观测值与过去某一特定滞后期数的观测值之间的相关性。
- PACF图像中的截尾性质是AR模型的一个重要特征,即在某个点之后,偏自相关系数变为0或接近0,这表明增加更多的滞后变量不会改善预测效果。
- PACF图像通常用于识别AR模型的阶数,即应该包含多少个滞后变量来拟合时间序列数据。
- ACF图像通常用来识别时间序列数据中的季节性成分或者周期性成分。
- 结论:由上图,ACF呈拖尾衰减,说明是平稳序列。
-
-
-
-
平稳性检验:
-
对时间序列数据进行平稳性检验(如ADF检验)。
-
倘若数据非平稳,通过差分、对数转换等方法使其平稳。
from statsmodels.tsa.stattools import adfuller result = adfuller(data['value']) print('ADF Statistic: %f' % result[0]) print('p-value: %f' % result[1]) out: ADF Statistic: -3.123396 p-value: 0.024870
-
-
模型选择:
-
根据数据特性选择合适的时间序列预测模型,如ARIMA、SARIMA、Holt-Winters季节性预测、Facebook Prophet、LSTM神经网络等。
-
模型选择方法:
- 数据的平稳性:如果时间序列数据是平稳的,即数据的统计特性(如均值、方差)不随时间变化,可以考虑使用ARIMA模型。ARIMA模型适用于分析和预测具有趋势和季节性的平稳时间序列数据。
- 季节性因素:如果数据存在明显的季节性变化,可以选择包含季节差分的ARIMA模型,或者使用SARIMA(季节性自回归积分滑动平均)模型来捕捉和预测季节性模式。
- 非线性关系:如果时间序列数据中存在非线性关系,可以考虑使用基于深度学习的模型,如LSTM(长短期记忆)网络或RNN(循环神经网络)。这些模型能够捕捉复杂的非线性模式,适合处理如文本、音频等顺序数据。
- 训练时间和计算资源:基于深度学习的模型可能需要较长的训练时间和更多的计算资源。如果训练时间是一个关键因素,可能需要优先考虑传统的时间序列分析方法,如ARIMA模型。
- 预测范围:如果需要长期预测,传统模型可能更为合适,因为它们通常对远外推(long-term extrapolation)更加稳定。而深度学习模型可能在短期内提供更准确的预测,但可能不适合长期预测。
- 数据量:深度学习模型通常需要大量的数据来进行训练,以便捕捉复杂的模式。如果数据量有限,传统模型可能更为合适。
- 模型解释性:如果需要模型具有良好的解释性,传统模型如ARIMA可能更适合,因为它们的参数和经济意义之间有直接的联系。
- 实际应用案例:参考类似领域的应用案例,了解其他研究者或从业者在类似问题上选择的模型,可以为模型选择提供有价值的参考。
- 实验比较:建立几个不同的时间序列模型,并通过交叉验证等方法比较它们的预测性能,最终选择表现最佳的模型。
- 专业知识和经验:结合领域专家的知识和以往经验,对模型的选择也有很大的帮助。
- 资源的可用性:考虑到实际可用的计算资源和技术能力,选择最适合当前条件的模型。
- 模型的泛化能力:考虑模型在新数据上的泛化能力,选择能够在未见过的数据上也表现良好的模型
-
-
使用交叉验证来评估不同模型的性能。
-
-
参数调优: (1)对选定的模型进行参数调优,比如使用网格搜索或随机搜索来寻找最优参数组合。
-
模型训练: (1)用历史数据训练模型。 (2)应用模型诊断,如残差分析,确保模型拟合良好。
-
模型验证: (1)在测试集上评估模型性能,常用指标有均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)等。 (2)可以通过滚动预测或时间序列交叉验证来进行更严格的验证。
-
预测: (1)使用最终模型进行未来支付单量的预测。 (2)根据需要生成置信区间,以评估预测的不确定性。
-
结果解释与部署: (1)解释模型的预测结果,考虑如何将预测结果应用于业务决策。 (2)部署模型以便定期自动运行预测,并将结果报告给相关利益相关者。















 1220
1220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









