







本文来源公众号“程序员学长”,仅用于学术分享,侵权删,干货满满。
原文链接:超强!六大优化算法全总结
今天我们将详细讨论一下用于训练神经网络(深度学习模型)时使用的一些常见优化技术(优化器)。
主要包括:
-
Gradient Descent Algorithm
-
Momentum
-
Adagrad
-
RmsProp
-
Adadelta
-
Adam
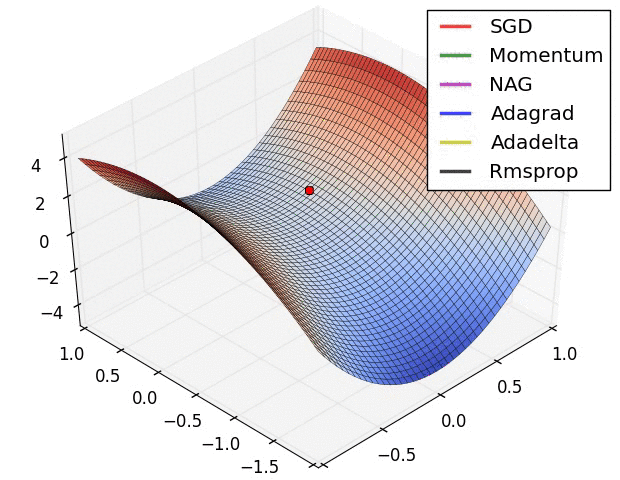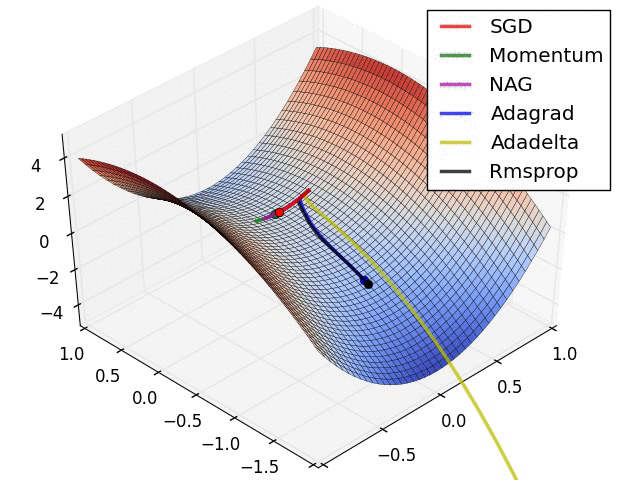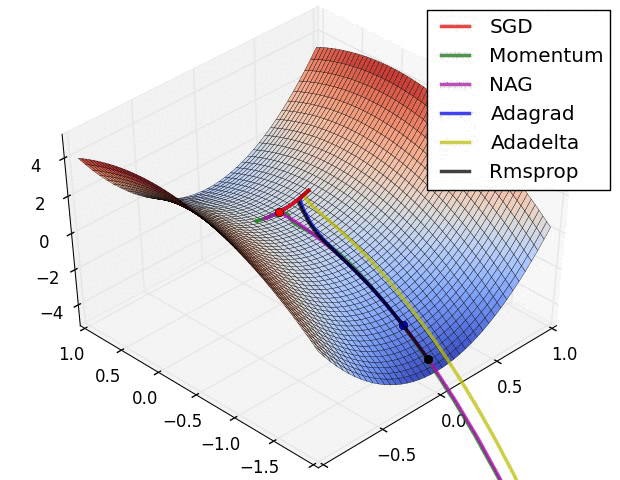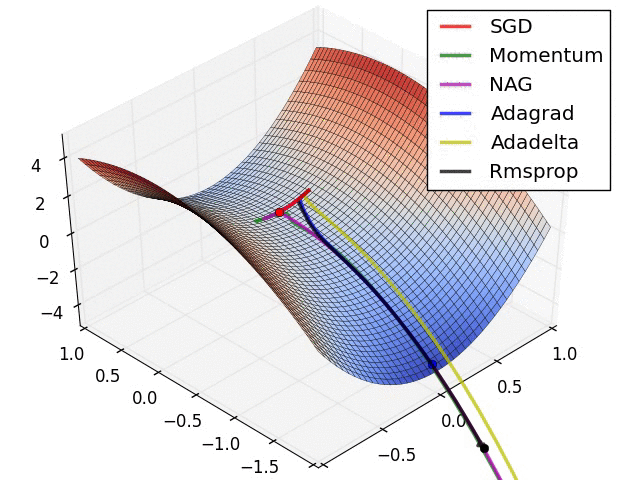
梯度下降算法
梯度下降算法是一种基于迭代的优化算法,用于寻找函数(成本函数)的最小值。
在深度学习模型中常常用来在反向传播过程中更新神经网络的权重。梯度下降的目标是找到使成本函数值最小的参数值。
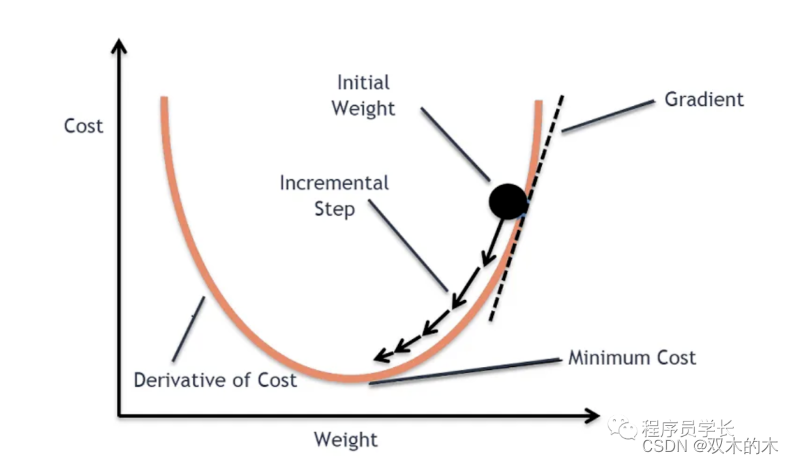
梯度下降的组成部分
-
成本函数:
这是需要最小化的函数。在机器学习中,成本函数通常度量模型预测值与实际值之间的差异。常用的成本函数有均方误差 (MSE)、均方根误差 (RMSE)、平均绝对误差 (MAE) 等。
-
epochs :
它是一个超参数,表示要运行的迭代次数,即为更新模型参数而计算梯度的次数。
-
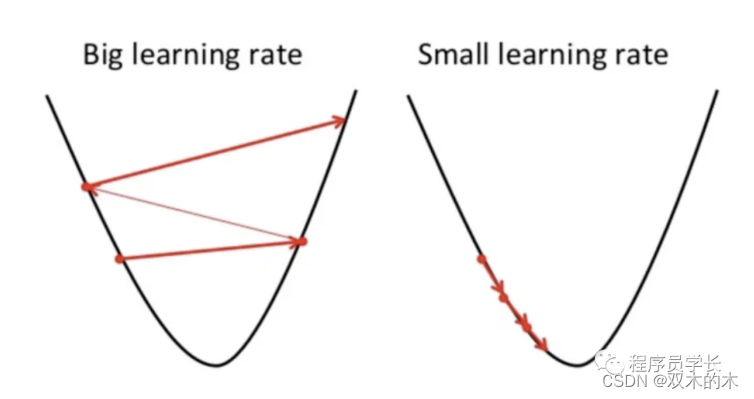
学习率
它是一个超参数,指的是更新步长的大小。如果太大,算法会发散而不是收敛。如果太小,算法需要大量迭代才能收敛,并且可能会遇到梯度消失问题。
执行步骤

梯度下降算法的不同变体
梯度下降算法有几种变体,包括:
批量梯度下降
批量梯度下降使用整个数据集计算梯度。
该方法提供了稳定的收敛性和一致的误差梯度,但对于大型数据集来说计算成本高昂且速度缓慢。
随机梯度下降 (SGD)
SGD 使用单个随机选择的数据点来估计梯度。
虽然它可以更快并且能够逃脱局部最小值,但由于其固有的随机性,它的收敛模式更加不稳定,可能导致成本函数的振荡。
小批量梯度下降
小批量梯度下降在上述两种方法之间取得了平衡。
它使用数据集的子集(或“小批量”)计算梯度。该方法利用矩阵运算的计算优势来加速收敛,并在批量梯度下降的稳定性和 SGD 的速度之间提供折衷方案。
Momentum
Momentum 是一种用于加速梯度下降算法的技术。它在某些方面类似于物理学中的动量概念,因此得名。Momentum 帮助算法在正确的方向上移动,同时减少“摆动”。
在数学上,Momentum 方法修改了标准梯度下降算法中的参数更新规则。在标准梯度下降中,每个参数在每次迭代中根据梯度的相反方向更新。而在使用 Momentum 的情况下,会考虑过去梯度的一部分,这样参数的更新不仅取决于当前梯度,还取决于之前梯度的累积。这可以通过一个动量项来实现,该动量项是过去梯度的加权平均。
具体来说,Momentum 算法在更新参数时使用以下公式。

Momentum 的主要好处包括
-
加速学习过程,特别是在梯度曲面的方向一致时。
-
减少震荡,有助于更平稳地收敛到最小值。
-
在某些情况下,有助于逃脱局部最小值。
Adagrad
Adagrad 是一种自适应的学习率优化算法,专为处理稀疏数据而设计。在传统的梯度下降算法中,全局学习率应用于所有的参数更新,而 Adagrad 允许每个参数有不同的学习率,以便自动调整学习率,这对于处理不同频率的特征是非常有用的。
Adagrad 算法的关键点在于累积过去所有梯度的平方和,用这个累积值来调节每个参数的学习率。这意味着对于出现频率较高的特征,它们的累积梯度会很大,因此学习率会降低;对于出现频率较低的特征,它们的累积梯度小,学习率则相对较高。

Adagrad的优点包括
-
不需要手动调整学习率,算法会自动进行调整。
-
能够很好地处理稀疏数据。
-
对于不同频率的参数可以进行有效的学习。
然而,Adagrad 也有一些局限性
-
学习率是单调递减的,随着时间的推移,学习率可能会过早和过度地减小到0,这会导致训练过程提前结束。
-
累积平方梯度在算法运行过程中不断累加,可能会导致分母过大,使得学习率过小。
RmsProp
RMSprop 是一种自适应学习率优化算法,被广泛用于训练各种类型的神经网络。RMSprop 旨在解决 AdaGrad 算法在训练深度神经网络时面临的一些问题,特别是学习率快速下降的问题。
关键概念
-
平方梯度累积: 在每次迭代中,RMSprop 首先计算梯度的平方,并将其累积到一个指数衰减的平均中。这个平均可以看作是最近梯度大小的移动平均。这有助于平衡梯度更新,特别是当梯度在不同方向的大小差异很大时。
-
自适应学习率: RMSprop 通过这种方式调整学习率,使其对于每个参数都是不同的。具体来说,它通过梯度的移动平均值来调整每个参数的更新。如果一个参数的梯度持续大,那么它的学习率会减少;反之,则增加。
-
防止学习率过快减小: 与 AdaGrad 相比,RMSprop 不会让学习率过快减小。这是因为它不是累积所有过去梯度的平方,而是仅仅关注最近的梯度。这使得 RMSprop 在长期训练中更加有效,尤其是对于非凸优化问题。
在数学上,RMSprop 的更新规则如下:

RMSprop 的这些特性使它在深度学习特别是循环神经网络(RNN)的训练中非常有效。它可以自动调整学习率,从而在训练的不同阶段有效地优化模型。
Adadelta
Adadelta 是一种基于梯度的优化算法,专门用于深度学习网络的训练。它是 AdaGrad 算法的扩展,旨在解决 AdaGrad 在训练过程中学习率单调递减的问题。Adadelta 的主要特点是不需要一个全局学习率,而是根据参数的更新历史来调整学习率。
在数学上,Adadelta 的更新规则如下


Adam
Adam 是一种用于机器学习和人工智能领域的强大优化算法,它结合了 Momentum 和 RMSprop 两种优化算法的特点。该算法基于自适应矩估计,利用梯度的一阶矩和二阶矩在训练过程中动态调整学习率。这有助于确保算法快速收敛并避免陷入局部最优。
Adam 的一个主要优点是它需要很少的内存并且只需要一阶梯度,这使其成为随机优化的有效方法。它也非常适合解决大量数据或参数的问题。
算法概念
下面是 Adam 算法中涉及的关键公式和步骤。


Adam 的优势在于每个参数的学习率是自适应调整的,这使得它在实践中对超参数的选择相对不敏感,并且适用于大多数非凸优化问题。此外,Adam 通常表现出比其他自适应学习率方法更快的收敛性能。
案例分享
import keras # Import the Keras library
from keras.datasets import mnist # Load the MNIST dataset
from keras.models import Sequential # Initialize a sequential model
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
import numpy as np
# Load the MNIST dataset from Keras
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Print the shape of the training and test data
print(x_train.shape, y_train.shape)
# Reshape the training and test data to 4 dimensions
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
# Define the input shape
input_shape = (28, 28, 1)
# Convert the labels to categorical format
y_train = keras.utils.to_categorical(y_train)
y_test = keras.utils.to_categorical(y_test)
# Convert the pixel values to floats between 0 and 1
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# Normalize the pixel values by dividing them by 255
x_train /= 255
x_test /= 255
# Define the batch size and number of classes
batch_size = 60
num_classes = 10
# Define the number of epochs to train the model for
epochs = 10
def build_model(optimizer):
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
return model
optimizers=['SGD','Adagrad','RMSprop','Adadelta','Adam']
histories ={opt:build_model(opt).fit(x_train,y_train,batch_size=batch_size,
epochs=epochs,verbose=1,validation_data=(x_test,y_test)) for opt in optimizers}THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 1809
1809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









