







本文来源公众号“小白学视觉”,仅用于学术分享,侵权删,干货满满。
1 导读
本文试图沿着图神经网络的历史脉络,从最早基于不动点理论的图神经网络(GNN)一步步讲到当前用得最火的图卷积神经网络( GCN) 。
笔者最近看了一些图与图卷积神经网络的论文,深感其强大,但一些Survey或教程默认了读者对图神经网络背景知识的了解,对未学过信号处理的读者不太友好。同时,很多教程只讲是什么,不讲为什么,也没有梳理清楚不同网络结构的区别与设计初衷(Motivation)。
因此,本文试图沿着图神经网络的历史脉络,从最早基于不动点理论的图神经网络(Graph Neural Network, GNN)一步步讲到当前用得最火的图卷积神经网络(Graph Convolutional Neural Network, GCN), 期望通过本文带给读者一些灵感与启示。
1. 本文的提纲与叙述要点主要参考了2篇图神经网络的Survey,分别是来自IEEE Fellow的A Comprehensive Survey on Graph Neural Networks[1] 以及来自清华大学朱文武老师组的Deep Learning on Graphs: A Survey[7], 在这里向两篇Survey的作者表示敬意。
2. 同时,本文关于部分图卷积神经网络的理解很多都是受到知乎问题[8]高赞答案的启发,非常感谢他们的无私分享!
3. 最后,本文还引用了一些来自互联网的生动形象的图片,在这里也向这些图片的作者表示感谢。本文中未注明出处的图片均为笔者制作,如需转载或引用请联系本人。
2 历史脉络
在开始正文之前,笔者先带大家回顾一下图神经网络的发展历史。不过,因为图神经网络的发展分支非常之多,笔者某些叙述可能并不全面,一家之言仅供各位读者参考:
-
图神经网络的概念最早在2005年提出。2009年Franco博士在其论文 [2]中定义了图神经网络的理论基础,笔者呆会要讲的第一种图神经网络也是基于这篇论文。
-
最早的GNN主要解决的还是如分子结构分类等严格意义上的图论问题。但实际上欧式空间(比如像图像 Image)或者是序列(比如像文本 Text),许多常见场景也都可以转换成图(Graph),然后就能使用图神经网络技术来建模。
-
2009年后图神经网络也陆续有一些相关研究,但没有太大波澜。直到2013年,在图信号处理(Graph Signal Processing)的基础上,Bruna(这位是LeCun的学生)在文献 [3]中首次提出图上的基于频域(Spectral-domain)和基于空域(Spatial-domain)的卷积神经网络。
-
其后至今,学界提出了很多基于空域的图卷积方式,也有不少学者试图通过统一的框架将前人的工作统一起来。而基于频域的工作相对较少,只受到部分学者的青睐。
-
值得一提的是,图神经网络与图表示学习(Represent Learning for Graph)的发展历程也惊人地相似。2014年,在word2vec [4]的启发下,Perozzi等人提出了DeepWalk [5],开启了深度学习时代图表示学习的大门。更有趣的是,就在几乎一样的时间,Bordes等人提出了大名鼎鼎的TransE [6],为知识图谱的分布式表示(Represent Learning for Knowledge Graph)奠定了基础。
3 图神经网络(Graph Neural Network)
首先要澄清一点,除非特别指明,本文中所提到的图均指图论中的图(Graph)。它是一种由若干个结点(Node)及连接两个结点的边(Edge)所构成的图形,用于刻画不同结点之间的关系。下面是一个生动的例子,图片来自论文[7]:

3.1 状态更新与输出




3.2 实例:化合物分类
下面让我们举个实例来说明图神经网络是如何应用在实际场景中的,这个例子来源于论文[2]。假设我们现在有这样一个任务,给定一个环烃化合物的分子结构(包括原子类型,原子键等),模型学习的目标是判断其是否有害。这是一个典型的二分类问题,一个训练样本如下图所示:

由于化合物的分类实际上需要对整个图进行分类,在论文中,作者将化合物的根结点的表示作为整个图的表示,如图上红色的结点所示。Atom feature 中包括了每个原子的类型(Oxygen, 氧原子)、原子自身的属性(Atom Properties)、化合物的一些特征(Global Properties)等。把每个原子看作图中的结点,原子键视作边,一个分子(Molecule)就可以看作一张图。在不断迭代得到根结点氧原子收敛的隐藏状态后,在上面接一个前馈神经网络作为输出层(即g函数),就可以对整个化合物进行二分类了。
当然,在同构图上根据策略选择同一个根结点对结果也非常重要。但在这里我们不关注这部分细节,感兴趣的读者可以阅读原文。
不动点理论 在本节的开头我们就提到了, GNN的理论基础是不动点(the fixed point)理论, 这里的不动点理论专指巴拿赫不动点定理(Banach's Fixed Point Theorem)。首先我们用 F 表示若干个 f 堆叠得到的一个函数, 也称为全局更新函数, 那么图上所有结点的状态更新公式可以写成:

3.3 不动点定理

3.4 具体实现
在具体实现中, f 其实通过一个简单的前馈神经网络(Feed-forward Neural Network)即可实现。比如说, 一种实现方法可以是把每个邻居结点的特征、隐藏状态、每条相连边的特征以及结点本身的特征简单拼接在一起, 在经过前馈神经网络后做一次简单的加和。

3.5 模型学习
上面我们花一定的篇幅搞懂了如何让 f 接近压缩映射, 下面我们来具体叙述一下图神经网络中的损失 Loss 是如何定义, 以及模型是如何学习的。
仍然以社交网络举例, 虽然每个结点都会有隐藏状态以及输出, 但并不是每个结点都会有监督信号 (Supervision)。比如说, 社交网络中只有部分用户被明确标记了是否为水军账号,这就构成了一个典型的结点二分类问题。
那么很自然地,模型的损失即通过这些有监督信号的结点得到。假设监督结点一共有 p 个,模型损失可以形式化为:

3.6 GNN与RNN
相信熟悉 RNN/LSTM/GRU 等循环神经网络的同学看到这里会有一点小困惑,因为图神经网络不论是前向传播的方式,还是反向传播的优化算法,与循环神经网络都有点相像。这并不是你的错觉,实际上,图神经网络与到循环神经网络确实很相似。为了清楚地显示出它们之间的不同,我们用一张图片来解释这两者设计上的不同:

假设在 GNN 中存在三个结点 x1,x2,x3, 相应地, 在RNN中有一个序列 (x1,x2,x3) 。笔者认为, GNN与RNN的区别主要在于4点:
-
GNN的基础理论是不动点理论,这就意味着GNN沿时间展开的长度是动态的,是根据收敛条件确定的,而RNN沿时间展开的长度就等于序列本身的长度。
-
GNN每次时间步的输入都是所有结点 v 的特征,而RNN每次时间步的输入是该时刻对应的输入。同时,时间步之间的信息流也不相同,前者由边决定,后者则由序列的读入顺序决定。
-
GNN采用 AP 算法反向传播优化,而RNN使用BPTT(Back Propogation Through Time)优化。前者对收敛性有要求,而后者对收敛性是没有要求的。
-
GNN循环调用 f 的目标是得到每个结点稳定的隐藏状态,所以只有在隐藏状态收敛后才能输出;而RNN的每个时间步上都可以输出,比如语言模型。
不过鉴于初代GNN与RNN结构上的相似性,一些文章中也喜欢把它称之为 Recurrent-based GNN,也有一些文章会把它归纳到 Recurrent-based GCN中。之后读者在了解 GCN后会理解为什么人们要如此命名。
3.7 GNN的局限
初代GNN,也就是基于循环结构的图神经网络的核心是不动点理论。它的核心观点是通过结点信息的传播使整张图达到收敛,在其基础上再进行预测。 收敛作为GNN的内核,同样局限了其更广泛的使用,其中最突出的是两个问题:

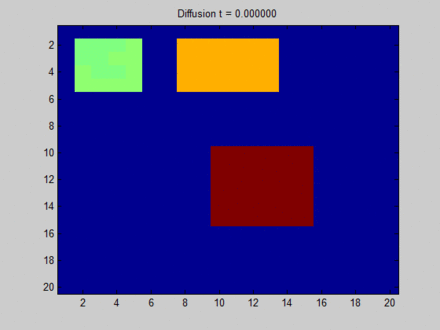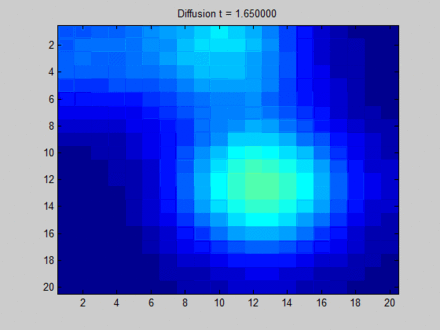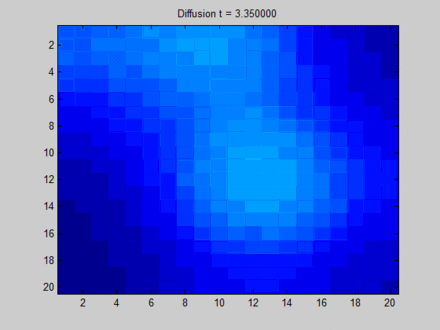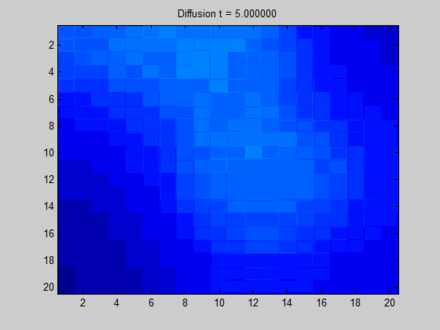
下面这张来自维基百科[13]的图可以形象地解释什么是 Over Smooth,其中我们把整个布局视作一张图,每个像素点与其上下左右以及斜上下左右8个像素点相邻,这决定了信息在图上的流动路径。初始时,蓝色表示没有信息量,如果用向量的概念表达即为空向量;绿色,黄色与红色各自有一部分信息量,表达为非空的特征向量。在图上,信息主要从三块有明显特征的区域向其邻接的像素点流动。一开始不同像素点的区分非常明显,但在向不动点过渡的过程中,所有像素点都取向一致,最终整个系统形成均匀分布。这样,虽然每个像素点都感知到了全局的信息,但我们无法根据它们最终的隐藏状态区分它们。比如说,根据最终的状态,我们是无法得知哪些像素点最开始时在绿色区域。
在这里笔者再多说几句。事实上,上面这个图与GNN中的信息流动并不完全等价。从笔者来看,如果我们用物理模型来描述它,上面这个图代表的是初始时有3个热源在散发热量,而后就让它们自由演化;但实际上,GNN在每个时间步都会将结点的特征作为输入来更新隐藏状态,这就好像是放置了若干个永远不灭的热源,热源之间会有互相干扰,但最终不会完全一致。
4 门控图神经网络(Gated Graph Neural Network)
我们上面细致比较了GNN与RNN,可以发现它们有诸多相通之处。那么,我们能不能直接用类似RNN的方法来定义GNN呢? 于是乎,门控图神经网络(Gated Graph Neural Network, GGNN) [10]就出现了。虽然在这里它们看起来类似,但实际上,它们的区别非常大,其中最核心的不同即是门控神经网络不以不动点理论为基础。这意味着:f 不再需要是一个压缩映射;迭代不需要到收敛才能输出,可以迭代固定步长;优化算法也从 AP 算法转向 BPTT。
4.1 状态更新
与图神经网络定义的范式一致,GGNN也有两个过程:状态更新与输出。相比GNN而言,它主要的区别来源于状态更新阶段。具体地,GGNN参考了GRU的设计,把邻居结点的信息视作输入,结点本身的状态视作隐藏状态,其状态更新函数如下:

为了处理这个问题,GGNN将结点特征作为隐藏状态初始化的一部分。那么重新回顾一下GGNN的流程,其实就是这样:
-
用结点特征初始化各个结点的(部分)隐藏状态;
-
对整张图,按照上述状态更新公式固定迭代若干步;
-
对部分有监督信号的结点求得模型损失,利用BPTT算法反向传播求得W_edge和GRU参数的梯度。
4.2 实例1:到达判断

图中的红色结点即开始结点 , 绿色结点是我们希望判断的结点 S ,我们这里称其为结束结点 E 。那么相比于其他结点,这两个结点具有一定特殊性。那我们就可以使用第1维为1来表示开始结点,第2维为1来表示结束结点。最后在对结束结点分类时,如果其隐藏状态的第1维被赋予得到了一个非0的实数值,那意味着它可以到达。
从初始化的流程我们也可以看出GNN与GGNN的区别:GNN依赖于不动点理论,所以每个结点的隐藏状态即使使用随机初始化都会收敛到不动点;GGNN则不同,不同的初始化对GGNN最终的结果影响很大。
4.3 实例2:语义解析
上面这个例子非常简单形象地说明了GNN与GGNN的不同,由于笔者比较关注Semantic Parsing(语义解析)相关的工作,所以下面我们借用ACL 2019的一篇论文[11]来讲一下GGNN在实际中如何使用,以及它适用于怎样的场景。
首先为不了解语义解析的读者科普一下,语义解析的主要任务是将自然语言转换成机器语言,在这里笔者特指的是SQL(结构化查询语言,Structured Query Language),它就是大家所熟知的数据库查询语言。这个任务有什么用呢?它可以让小白用户也能从数据库中获得自己关心的数据。正是因为有了语义解析,用户不再需要学习SQL语言的语法,也不需要有编程基础,可以直接通过自然语言来查询数据库。事实上,语义解析放到今天仍然是一个非常难的任务。除去自然语言与程序语言在语义表达上的差距外,很大一部分性能上的损失是因为任务本身,或者叫SQL语言的语法太复杂。比如我们有两张表格,一张是学生的学号与其性别,另一张表格记录了每个学生选修的课程。那如果想知道有多少女生选修了某门课程,我们需要先将两张表格联合(JOIN),再对结果进行过滤(WHERE),最后进行聚合统计(COUNT)。这个问题在多表的场景中尤为突出,每张表格互相之间通过外键相互关联。其实呢,如果我们把表格中的Header看作各个结点,表格内的结点之间存在联系,而外键可以视作一种特殊的边,这样就可以构成一张图,正如下图中部所示:

论文[11]就是利用了表格这样的特性,利用GGNN来解决多表问题。下面我们先介绍一下一般的语义解析方法,再介绍[11]是如何将图跟语义解析系统联系在一起的。就笔者知道的而言,目前绝大部分语义解析会遵循Seq2seq(序列到序列,Sequence to sequence)的框架,输入是一个个自然语言单词,输出是一个个SQL单词。但这样的框架完全没有考虑到表格对SQL输出暗含的约束。比如说,在单个SELECT子句中,我们选择的若干Header都要来自同一张表。再举个例子,能够JOIN的两张表一定存在外键的联系,就像我们刚刚举的那个学生选课的例子一样。
那么,GGNN该如何结合到传统的语义解析方法中去呢?在论文[11]中,是通过三步来完成的:
-
首先,通过表格建立对应的Graph。再利用GGNN的方法计算每个Header的隐藏状态。
-
然后,在Seq2seq模型的编码阶段(Encoding),用每个输入的自然语言单词的词向量对表格所有Header的隐藏状态算一个Attention,利用Attention作为权重得到了每个自然语言单词的图感知的表示。
-
在解码阶段(Decoding), 如果输出的是表格中的Header/Table这类词, 就用输出的向量与表格所有Header/Table的隐藏状态算一个分数, 这个分数由 F 提供的。F 实际上是一个全连接层, 它的输出实际上是SQL单词与表格中各个Header/Table的联系程度。为了让SQL的每个输出都与历史的信息一致, 每次输出时都用之前输出的Header/Table对候选集中的Header/Table打分, 这样就利用到了多表的信息。
最终该论文在多表上的效果也确实很好,下面放一个在Spider[12]数据集上的性能对比:

4.4 GNN与GGNN
GGNN目前得到了广泛的应用,相比于GNN,其最大的区别在于不再以不动点理论为基础,虽然这意味着不再需要迭代收敛,但同时它也意味着GGNN的初始化很重要。从笔者阅读过的文献来看,GNN后的大部分工作都转向了将GNN向传统的RNN/CNN靠拢,可能的一大好处是这样可以不断吸收来自这两个研究领域的改进。但基于原始GNN的基于不动点理论的工作非常少,至少在笔者看文献综述的时候并未发现很相关的工作。
但从另一个角度来看,虽然GNN与GGNN的理论不同,但从设计哲学上来看,它们都与循环神经网络的设计类似。
-
循环神经网络的好处在于能够处理任意长的序列,但它的计算必须是串行计算若干个时间步,时间开销不可忽略。所以,上面两种基于循环的图神经网络在更新隐藏状态时不太高效。如果借鉴深度学习中堆叠多层的成功经验,我们有足够的理由相信,多层图神经网络能达到同样的效果。
-
基于循环的图神经网络每次迭代时都共享同样的参数,而多层神经网络每一层的参数不同,可以看成是一个层次化特征抽取(Hierarchical Feature Extraction)的方法。
原文地址:
https://www.cnblogs.com/SivilTaram/p/graph_neural_network_1.html
参考文献
[1]. A Comprehensive Survey on Graph Neural Networks, https://arxiv.org/abs/1901.00596
[2]. The graph neural network model, https://persagen.com/files/misc/scarselli2009graph.pdf
[3]. Spectral networks and locally connected networks on graphs, https://arxiv.org/abs/1312.6203
[4]. Distributed Representations of Words and Phrases and their Compositionality, http://papers.nips.cc/paper/5021-distributed-representations-of-words-andphrases
[5]. DeepWalk: Online Learning of Social Representations, https://arxiv.org/abs/1403.6652
[6]. Translating Embeddings for Modeling Multi-relational Data, https://papers.nips.cc/paper/5071-translating-embeddings-for-modeling-multi-relational-data
[7]. Deep Learning on Graphs: A Survey, https://arxiv.org/abs/1812.04202
[8]. 如何理解Graph Convolutional Network(GCN)? https://www.zhihu.com/question/54504471
[9]. Almeida–Pineda recurrent backpropagation, https://www.wikiwand.com/en/Almeida%E2%80%93Pineda_recurrent_backpropagation
[10]. Gated graph sequence neural networks, https://arxiv.org/abs/1511.05493
[11]. Representing Schema Structure with Graph Neural Networks for Text-to-SQL Parsing, https://arxiv.org/abs/1905.06241
[12]. Spider1.0 Yale Semantic Parsing and Text-to-SQL Challenge, https://yale-lily.github.io/spider
[13]. https://www.wikiwand.com/en/Laplacian_matrix
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









