










本文来源公众号“OpenCV与AI深度学习”,仅用于学术分享,侵权删,干货满满。
原文链接:实战 | 基于YOLOv8和OpenCV实现车速检测(详细步骤 + 代码)
导 读
本文主要介绍如何使用YOLOv8+BYTETrack+OpenCV实现车辆速度的计算(详细步骤 + 代码)。
1 前 言
您是否想过如何使用计算机视觉来估计车辆的速度?在本教程中,我们将探索从对象检测到跟踪再到速度估计的整个过程。
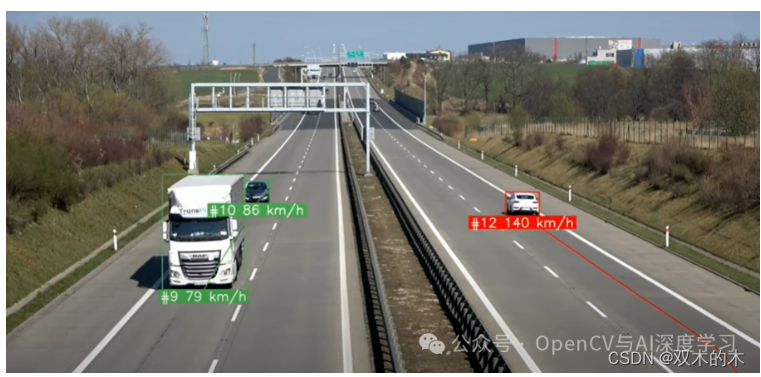
本文的实现主要包含以下三个主要步骤,分别是对象检测、对象跟踪和速度估计,下面我们将一一介绍其实现步骤。
2 车辆检测
要对视频执行目标检测,我们需要迭代视频的帧,然后对每个帧运行我们的检测模型。推理则提供对预先训练的目标检测模型的访问,我们使用yolov8x-640模型。相关代码和文档可参考链接:
https://github.com/roboflow/inference?ref=blog.roboflow.com
https://inference.roboflow.com/?ref=blog.roboflow.comimport supervision as sv
from inference.models.utils import get_roboflow_model
model = get_roboflow_model(‘yolov8x-640’)
frame_generator = sv.get_video_frames_generator(‘vehicles.mp4’)
bounding_box_annotator = sv.BoundingBoxAnnotator()
for frame in frame_generator:
results = model.infer(frame)[0]
detections = sv.Detections.from_inference(results)
annotated_frame = trace_annotator.annotate(
scene=frame.copy(), detections=detections)

当然您也可以将其替换为Ultralytics YOLOv8、YOLO-NAS或任何其他模型。您需要更改代码中的几行,然后就可以了。
3 车辆跟踪
物体检测不足以执行速度估计。为了计算每辆车行驶的距离,我们需要能够跟踪它们。为此,我们使用 BYTETrack,可在 Supervision pip 包中访问。
...
# initialize tracker
byte_track = sv.ByteTrack()
...
for frame in frame_generator:
results = model.infer(frame)[0]
detections = sv.Detections.from_inference(results)
# plug the tracker into an existing detection pipeline
detections = byte_track.update_with_detections(detections=detections)
...如果您想了解有关将 BYTETrack 集成到对象检测项目中的更多信息,请访问 Supervision文档页面。在那里,您将找到一个端到端示例,展示如何使用不同的检测模型来做到这一点。
https://supervision.roboflow.com/how_to/track_objects/?ref=blog.roboflow.com

4 车速计算
让我们考虑一种简单的方法,根据边界框移动的像素数来估计距离。
当您使用点来记住每辆车每秒的位置时,会发生以下情况。即使汽车以恒定速度移动,其行驶的像素距离也会发生变化。距离相机越远,覆盖的距离越小。


因此,我们很难使用原始图像坐标来计算速度。我们需要一种方法将图像中的坐标转换为道路上的实际坐标,从而消除沿途与透视相关的失真。幸运的是,我们可以使用 OpenCV 和一些数学来做到这一点。
视角转换背后的数学
为了变换视角,我们需要一个变换矩阵,我们使用OpenCV 中的函数getPerspectiveTransform确定它。该函数有两个参数:源感兴趣区域和目标感兴趣区域。在下面的可视化中,这些区域分别标记为A-B-C-D和A'-B'-C'-D'。
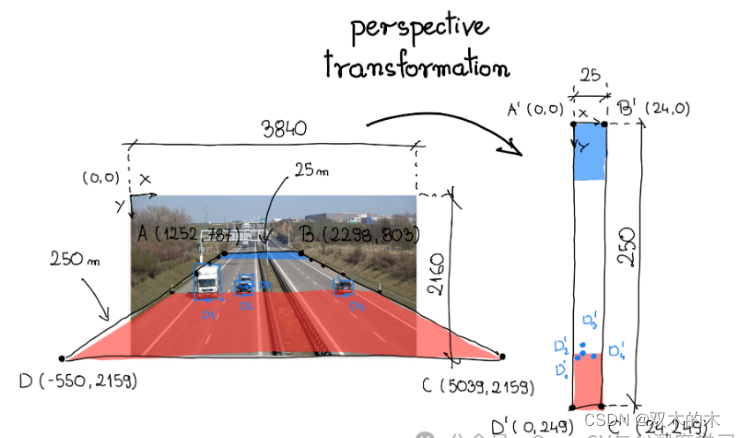 在分析单个视频帧时,我们选择了一段道路作为感兴趣的源区域。在高速公路的路肩上,通常有垂直的柱子——标记,每隔固定的距离间隔开。在本例中为 50 米。感兴趣的区域横跨道路的整个宽度以及连接上述六个柱子的部分。
在分析单个视频帧时,我们选择了一段道路作为感兴趣的源区域。在高速公路的路肩上,通常有垂直的柱子——标记,每隔固定的距离间隔开。在本例中为 50 米。感兴趣的区域横跨道路的整个宽度以及连接上述六个柱子的部分。
在我们的例子中,我们正在处理一条高速公路。Google 地图研究表明,感兴趣源区域周围的区域大约宽 25 米,长 250 米。我们使用此信息来定义相应四边形的顶点,将新坐标系锚定在左上角。
最后,我们将顶点A-B-C-D和的坐标分别重新组织A'-B'-C'-D'为二维SOURCE和TARGET矩阵,其中矩阵的每一行包含一个点的坐标。
SOURCE = np.array([
[1252, 787],
[2298, 803],
[5039, 2159],
[-550, 2159]
])
TARGET = np.array([
[0, 0],
[24, 0],
[24, 249],
[0, 249],
])视角转换
需要一使用源矩阵和目标矩阵,我们创建一个 ViewTransformer 类。该类使用OpenCV的getPerspectiveTransform函数来计算变换矩阵。Transform_points 方法应用此矩阵将图像坐标转换为现实世界坐标。
class ViewTransformer:
def __init__(self, source: np.ndarray, target: np.ndarray) -> None:
source = source.astype(np.float32)
target = target.astype(np.float32)
self.m = cv2.getPerspectiveTransform(source, target)
def transform_points(self, points: np.ndarray) -> np.ndarray:
if points.size == 0:
return points
reshaped_points = points.reshape(-1, 1, 2).astype(np.float32)
transformed_points = cv2.perspectiveTransform(
reshaped_points, self.m)
return transformed_points.reshape(-1, 2)
view_transformer = ViewTransformer(source=SOURCE, target=TARGET)

用计算机视觉计算速度
现在我们已经有了检测器、跟踪器和透视转换逻辑。是时候计算速度了。原则上很简单:将行驶的距离除以行驶该距离所需的时间。然而,这项任务有其复杂性。
在一种情况下,我们可以计算每一帧的速度:计算两个视频帧之间行进的距离,并将其除以 FPS 的倒数,在我的例子中为 1/25。不幸的是,这种方法可能会导致非常不稳定和不切实际的速度值。

为了防止这种情况,我们对一秒钟内获得的值进行平均。这样,汽车行驶的距离明显大于闪烁引起的小盒子移动,我们的速度测量也更接近真实情况。
...
video_info = sv.VideoInfo.from_video_path('vehicles.mp4')
# initialize the dictionary that we will use to store the coordinates
coordinates = defaultdict(lambda: deque(maxlen=video_info.fps))
for frame in frame_generator:
result = model(frame)[0]
detections = sv.Detections.from_ultralytics(result)
detections = byte_track.update_with_detections(detections=detections)
points = detections.get_anchors_coordinates(
anchor=sv.Position.BOTTOM_CENTER)
# plug the view transformer into an existing detection pipeline
points = view_transformer.transform_points(points=points).astype(int)
# store the transformed coordinates
for tracker_id, [_, y] in zip(detections.tracker_id, points):
coordinates[tracker_id].append(y)
for tracker_id in detections.tracker_id:
# wait to have enough data
if len(coordinates[tracker_id]) > video_info.fps / 2:
# calculate the speed
coordinate_start = coordinates[tracker_id][-1]
coordinate_end = coordinates[tracker_id][0]
distance = abs(coordinate_start - coordinate_end)
time = len(coordinates[tracker_id]) / video_info.fps
speed = distance / time * 3.6
...


速度估计隐藏的复杂性
在构建现实世界的车辆速度估计系统时,应考虑许多其他因素。让我们简要讨论其中的几个。
遮挡和修剪的盒子:盒子的稳定性是影响速度估计质量的关键因素。当一辆车暂时遮挡另一辆车时,方框大小的微小变化可能会导致估计速度值的巨大变化。
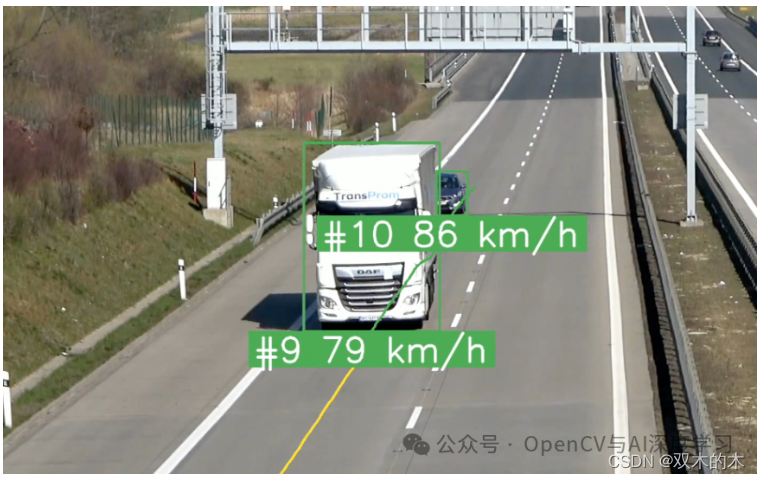
设置固定参考点:在本例中,我们使用边界框的底部中心作为参考点。这是可能的,因为视频中的天气条件很好——晴天,没有下雨。然而,很容易想象找到这一点会困难得多的情况。
道路的坡度:在本例中,假设道路完全平坦。事实上,这种情况很少发生。为了尽量减少坡度的影响,我们必须将自己限制在道路相对平坦的部分,或者将坡度纳入计算中。

THE END!
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









