







本文来源公众号“算法进阶”,仅用于学术分享,侵权删,干货满满。
原文链接:PyTorch从零构建Llama 3
大家好,本文将详细指导如何从零开始构建完整的Llama 3模型架构,并在自定义数据集上执行训练和推理。
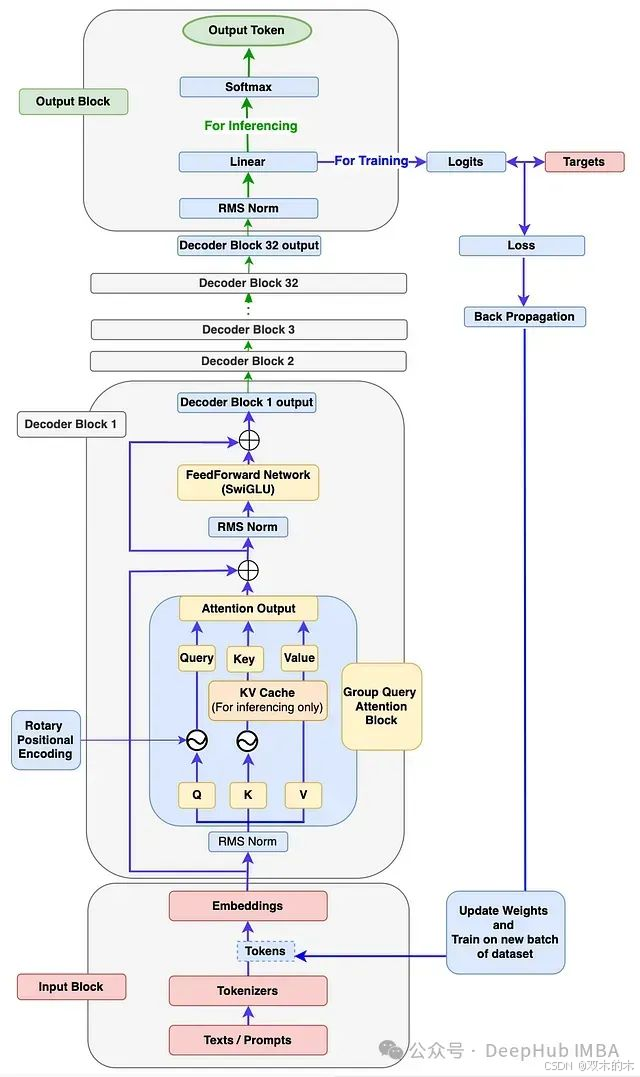
[图1]:Llama 3架构展示训练和推理流程。因为官方Llama 3论文中未提供相关图表。所以此图为大概架构图,阅读本文后你应能绘制出更为精确的架构图。
本文目标
通过本文。你可以了解到:
-
深入理解Llama 3模型各组件的底层工作原理。
-
编写代码构建Llama 3的每个组件,并将它们组装成一个功能完整的Llama 3模型。
-
编写代码使用新的自定义数据集训练模型。
-
编写代码执行推理,使Llama 3模型能够根据输入提示生成新文本。
1、输入模块
如图1所示,输入模块包含三个组件:文本/提示、分词器和嵌入。
输入模块内部工作流程
让我们通过下图了解输入模块内的工作流程。
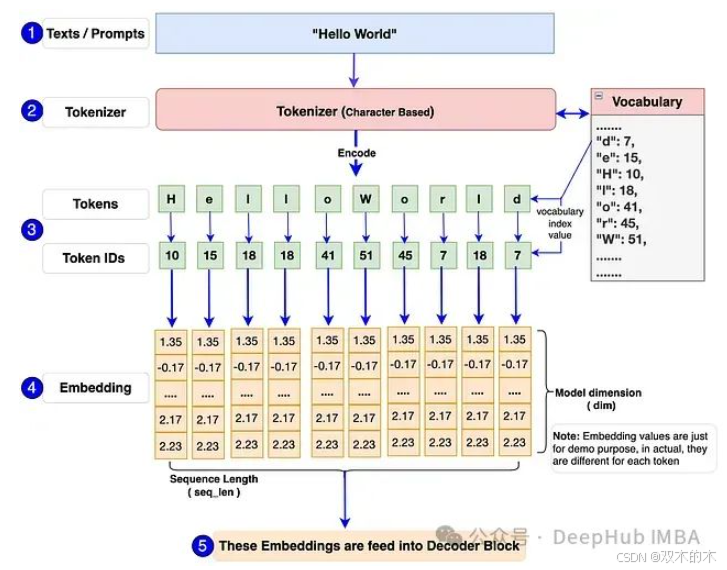
[图2]:输入模块流程图,展示提示、分词器和嵌入流程。
首先,单个或批量文本/提示被输入模型。例如:图中的"Hello World"。
输入模型的必须是数字格式,因为模型无法直接处理文本。分词器将这些文本/提示转换为标记ID(词汇表中标记的索引号表示)。我们将使用Tiny Shakespeare数据集构建词汇表并训练模型。Llama 3模型使用TikToken作为分词器,这是一种子词分词器。但是我们这个实现将使用字符级分词器。这样做的主要原因是让我们能够自行构建词汇表和分词器,包括编码和解码函数,这样可以深入理解底层工作原理并完全掌控代码。
每个标记ID将被转换为128维的嵌入向量(原始Llama 3 8B中为4096维)。然后这些嵌入将被传递到下一个解码器模块。
输入模块代码实现:
# 导入必要的库
import torch
from torch import nn
from torch.nn import functional as F
import math
import numpy as np
import time
from dataclasses import dataclass
from typing import Optional, Tuple, List
import pandas as pd
from matplotlib import pyplot as plt
### 步骤1: 输入模块 ###
# 使用Tiny Shakespeare数据集实现字符级分词器。部分字符级分词器代码参考自Andrej Karpathy的GitHub仓库
# (https://github.com/karpathy/nanoGPT/blob/master/data/shakespeare_char/prepare.py)
# 加载tiny_shakespeare数据文件 (https://github.com/tamangmilan/llama3/blob/main/tiny_shakespeare.txt)
device: str = 'cuda' if torch.cuda.is_available() else 'cpu' # 根据可用性分配设备为cuda或cpu
# 加载tiny_shakespeare数据文件
with open('tiny_shakespeare.txt', 'r') as f:
data = f.read()
# 通过提取tiny_shakespeare数据中的所有唯一字符准备词汇表
vocab = sorted(list(set(data)))
# 训练Llama 3模型需要额外的标记,如<|begin_of_text|>、<|end_of_text|>和<|pad_id|>,将它们添加到词汇表中
vocab.extend(['<|begin_of_text|>','<|end_of_text|>','<|pad_id|>'])
vocab_size = len(vocab)
# 创建字符与词汇表中对应整数索引之间的映射。
# 这对于构建分词器的编码和解码函数至关重要。
itos = {i:ch for i, ch in enumerate(vocab)}
stoi = {ch:i for i, ch in enumerate(vocab)}
# 分词器编码函数:输入字符串,输出整数列表
def encode(s):
return [stoi[ch] for ch in s]
# 分词器解码函数:输入整数列表,输出字符串
def decode(l):
return ''.join(itos[i] for i in l)
# 定义稍后在模型训练中使用的张量标记变量
token_bos = torch.tensor([stoi['<|begin_of_text|>']], dtype=torch.int, device=device)
token_eos = torch.tensor([stoi['<|end_of_text|>']], dtype=torch.int, device=device)
token_pad = torch.tensor([stoi['<|pad_id|>']], dtype=torch.int, device=device)
prompts = "Hello World"
encoded_tokens = encode(prompts)
decoded_text = decode(encoded_tokens)
### 输入模块代码测试 ###
# 取消下面的三重引号来执行测试
"""
print(f"Shakespeare文本字符长度: {len(data)}")
print(f"词汇表内容: {''.join(vocab)}\n")
print(f"词汇表大小: {vocab_size}")
print(f"编码后的标记: {encoded_tokens}")
print(f"解码后的文本: {decoded_text}")
"""
### 测试结果: ###
"""
Shakespeare文本字符长度: 1115394
词汇表内容:
!$&',-.3:;?ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz<|begin_of_text|><|end_of_text|><|pad_id|>
词汇表大小: 68
编码后的标记: [20, 43, 50, 50, 53, 1, 35, 53, 56, 50, 42]
解码后的文本: Hello World
"""2、解码器模块
参照图1的架构图,解码器模块包含以下子组件:
-
RMS归一化
-
旋转位置编码
-
KV缓存
-
分组查询注意力
-
前馈网络
-
解码器块
RMS归一化(Root Mean Square Normalization)
RMSNorm的必要性
从图1可以看出,输入模块的输出(嵌入向量)经过RMSNorm模块。这是因为嵌入向量具有多个维度(Llama3-8b中为4096维),可能出现不同范围的值。这会导致模型梯度爆炸或消失,从而导致收敛缓慢甚至发散。而RMSNorm将这些值归一化到一定范围,有助于稳定和加速训练过程。这使得梯度具有更一致的幅度,从而加快模型收敛。
RMSNorm的工作原理

[图3]:对形状为[3,3]的输入嵌入应用RMSNorm
类似于层归一化,RMSNorm沿嵌入特征或维度应用。上图中的嵌入形状为[3,3],意味着每个标记有3个维度。
示例:对第一个标记X1的嵌入应用RMSNorm:
X1标记在每个维度上的值(x11、x12和x13)分别除以所有这些值的均方根。公式如图3所示。
为避免除以零并保证数值稳定性,在均方根中加入一个小常数E(Epsilon)。乘以一个缩放参数Gamma (Y)。每个特征都有一个独特的Gamma参数(如图中d1维度的Y1、d2维度的Y2和d3维度的Y3),这是一个学习参数,可以向上或向下缩放以进一步稳定归一化。gamma参数初始化为1(如上面的计算所示)。
如示例所示,嵌入值原本较大且分布范围宽。应用RMSNorm后,值变小且范围缩小。计算使用实际的RMSNorm函数完成。
RMSNorm相比层归一化的优势
如上例所示没有计算任何均值或方差,而这在层归一化中是必需的。所以RMSNorm通过避免计算均值和方差减少了计算开销。根据作者的研究,RMSNorm在不影响准确性的同时提供了性能优势。
RMSNorm代码实现:
# 步骤2: 解码器模块
# 注:由于Llama 3模型由Meta开发,为了与他们的代码库保持一致并考虑未来兼容性,
# 我将使用Meta GitHub上的大部分代码,并进行必要的修改以实现我们的目标。
# 定义参数数据类:我们将在模型构建、训练和推理过程中使用这些参数。
# 注:为了更快地看到训练和推理结果,而不是专注于高准确性,我们对大多数参数采用较低的值,
# 这些值在Llama 3模型中设置得更高。
@dataclass
class ModelArgs:
dim: int = 512 # 嵌入维度
n_layers: int = 8 # 模型解码器块的数量
n_heads: int = 8 # 查询嵌入的头数
n_kv_heads: int = 4 # 键和值嵌入的头数
vocab_size: int = len(vocab) # 词汇表长度
multiple_of: int = 256 # 用于计算前馈网络维度
ffn_dim_multiplier: Optional[float] = None # 用于计算前馈网络维度
norm_eps: float = 1e-5 # RMSNorm计算的默认Epsilon值
rope_theta: float = 10000.0 # RePE计算的默认theta值
max_batch_size: int = 10 # 最大批量大小
max_seq_len: int = 256 # 最大序列长度
epochs: int = 2500 # 总训练迭代次数
log_interval: int = 10 # 打印日志和损失值的间隔数
device: str = 'cuda' if torch.cuda.is_available() else 'cpu' # 根据可用性分配设备为cuda或cpu
## 步骤2a: RMSNorm
class RMSNorm(nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
device = ModelArgs.device
self.eps = eps
# 缩放参数gamma,初始化为1,参数数量等于d 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 565
565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









