









本文来源公众号“Coggle数据科学”,仅用于学术分享,侵权删,干货满满。
原文链接:从零实现 DeepSeek R1:从基础模型到强化推理模型
在人工智能领域,语言模型的推理能力一直是研究的热点和难点。DeepSeek R1 作为一款专注于推理的先进语言模型,其训练过程和技术创新为自然语言处理领域带来了新的突破。
今天,我们将深入探讨 DeepSeek R1 的训练过程,从技术细节到实现步骤,带你一探究竟。
https://github.com/FareedKhan-dev/train-deepseek-r1
DeepSeek R1 的训练过程并非从零开始,而是基于其强大的基础模型 DeepSeek V3,通过强化学习(Reinforcement Learning, RL)的方式进行优化和改进。
为了便于理解和实践,我们可以通过一个简化版本的项目来复现这一过程。项目代码库 train-deepseek-r1 提供了完整的实现细节,包括代码、依赖库和针对非技术读者的解释文档。
环境配置
在开始之前,我们需要准备好训练环境。通过以下命令克隆代码库并安装依赖库:
git clone https://github.com/FareedKhan-dev/train-deepseek-r1.git
cd train-deepseek-r1
pip install -r requirements.txt
接下来,导入必要的 Python 库,包括 PyTorch、Hugging Face Transformers、TRL(Transformers Reinforcement Learning)等。这些工具为我们提供了强大的模型、数据处理和训练功能。
推理型数据集
在训练 DeepSeek R1 时,研究者们选择了两个开源数据集:NuminaMath-TIR 和 Bespoke-Stratos-17k。
-
NuminaMath-TIR 是一个专注于数学问题的数据集,包含 70,000 个数学问题及其逐步解决方案。每个问题都配有详细的推理过程(Chain of Thought, CoT),以对话形式呈现。这种结构化的数据集非常适合训练模型的推理能力。
-
Bespoke-Stratos-17k 数据集则专注于数学和代码问题,包含 17,000 个问题及其解决方案。与 NuminaMath-TIR 类似,它也以对话形式呈现问题和解决方案,但更侧重于编程和数学推理。
DeepSeek R1 训练快速概览
DeepSeek R1 的训练过程是一个从基础模型出发,通过强化学习和分阶段训练逐步提升推理能力的过程。
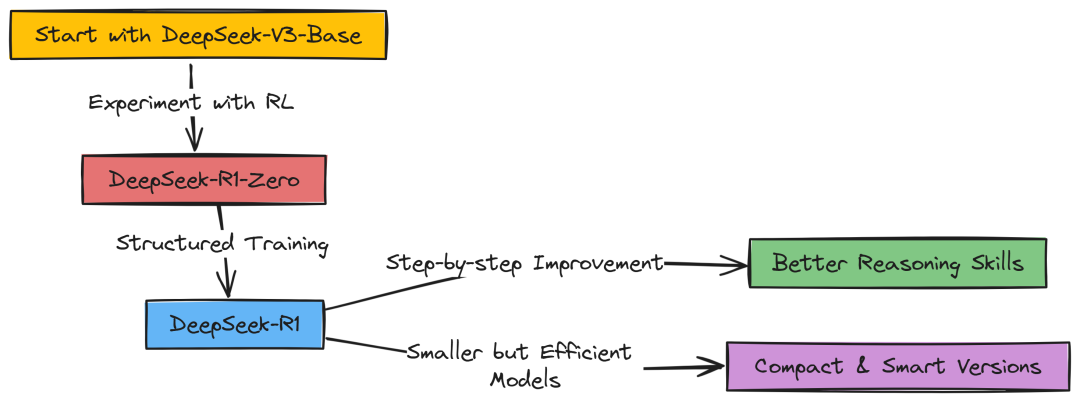
选择基础模型
基础模型是语言模型的“底座”,它提供了模型的初始架构和参数。一个强大的基础模型通常具备以下特点:
-
强大的语言生成能力:能够生成流畅、自然的语言文本。
-
足够的参数量:足够的参数量可以支持模型学习复杂的语言模式和推理逻辑。
-
高效的计算性能:模型的大小和计算效率直接影响训练和推理的速度。
为了简化训练过程,同时确保模型的性能和效率,我们选择了一个更小的基础模型——Qwen/Qwen2.5-0.5B-Instruct。这个模型的大小仅为 0.9 GB,适合大多数用户在本地运行和训练。
强化学习模块
在 DeepSeek R1 的训练过程中,最初的版本被称为 DeepSeek R1 Zero。这是一个基于纯强化学习的初步尝试,目的是看看仅通过强化学习是否能够让模型自发地产生推理能力。
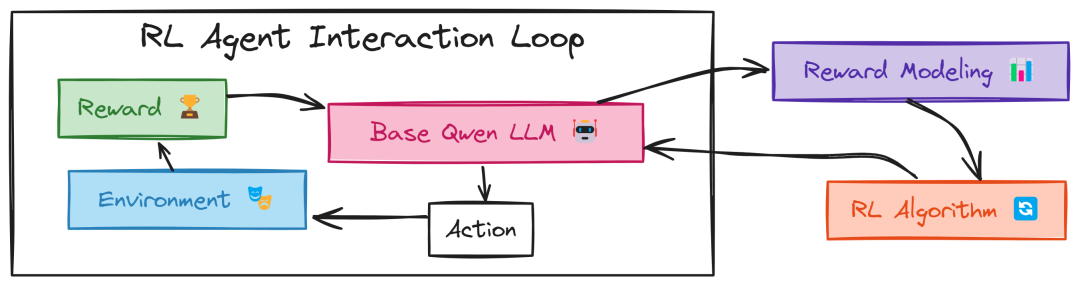
DeepSeek 团队在训练 R1 Zero 时采用了 GRPO 算法,这种算法通过一种创新的方式解决了传统强化学习的局限性。
GRPO 算法的核心在于它能够直接从一组行为的结果中计算出一个基线(baseline),这个基线可以作为衡量行为好坏的参考点。因此,GRPO 算法不需要一个单独的“critic”模型,从而大大节省了计算成本,提高了训练效率。
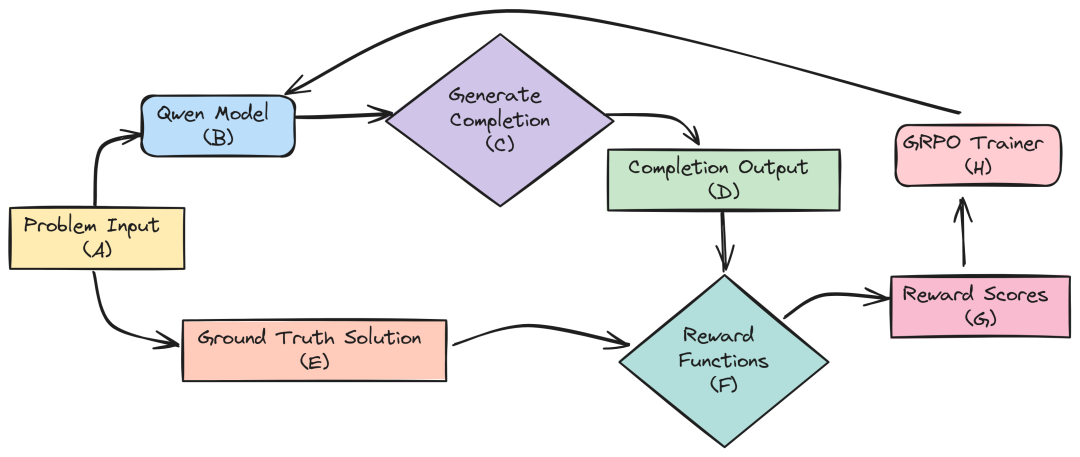
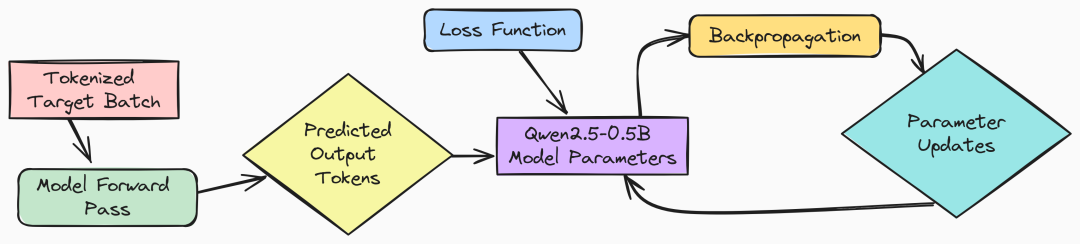
1. 问题输入与模型生成
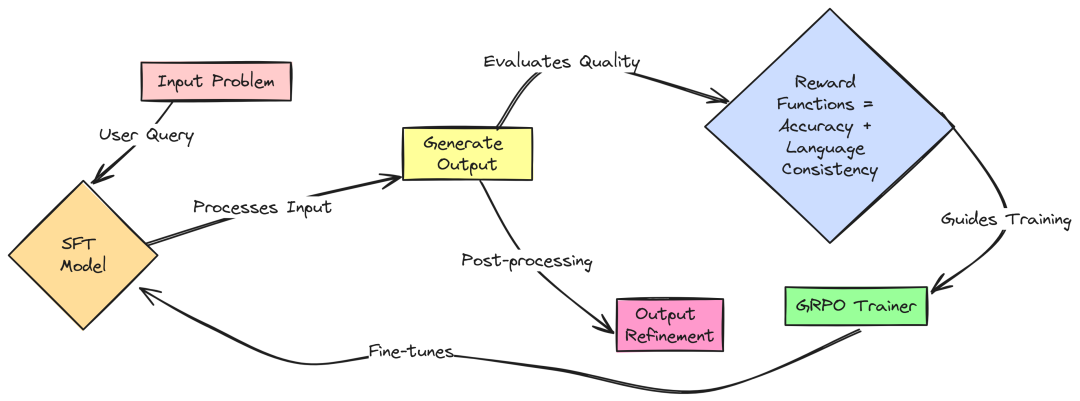
首先,将问题输入(Problem Input, A)提供给 Qwen 模型(Qwen Model, B)。Qwen 模型尝试通过生成完成(Generate Completion, C)来生成一个回答。最终的结果,称为完成输出(Completion Output, D),包括带有标签的推理步骤和最终解决方案。
2. 奖励函数的评估
接下来,将问题输入(A)和真实解决方案(Ground Truth Solution, E)输入到奖励函数(Reward Functions, F)中。这些奖励函数充当智能评分器,将 Qwen 的完成输出(D)与正确答案进行比较,并从多个方面进行评估,例如:
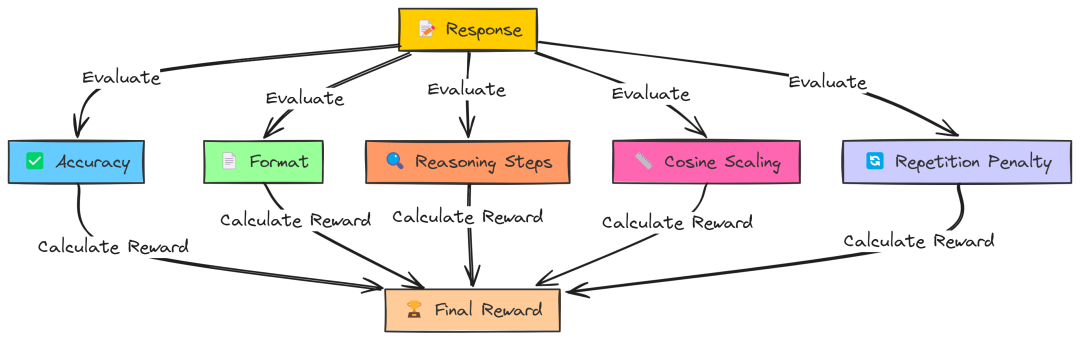
-
准确性:答案是否正确?
-
格式:是否正确使用了标签?
-
推理步骤:逻辑是否清晰?
-
余弦缩放:回答是否简洁?
-
重复惩罚:是否存在不必要的重复?
这些评估会产生奖励分数(Reward Scores, G),然后将这些分数传递给 GRPO 训练器(GRPO Trainer, H)。
3. 模型的调整与优化
GRPO 训练器使用梯度来调整 Qwen 模型(B),微调其生成答案的方式。这个过程被称为梯度奖励策略优化(Gradient Reward Policy Optimization),因为它通过梯度、奖励反馈和策略调整来优化 Qwen 的回答,从而最大化性能。
Prompt Template 设计
在 DeepSeek R1 Zero 的训练中,研究人员使用了一个特定的 Prompt Template,这个模板不仅定义了问题和回答的结构,还引入了推理过程的标签。以下是该模板的具体内容:
# DeepSeek 系统提示模板,用于基于 GRPO 的训练
SYSTEM_PROMPT = (
f"""A conversation between User and Assistant. The user asks a question,
and the Assistant solves it. The assistant
first thinks about the reasoning process in the mind and
then provides the user with the answer. The reasoning
process and answer are enclosed within <think> </think>
and <answer> </answer> tags, respectively, i.e.,
<think> reasoning process here </think><answer> answer here </answer>
"""
)
奖励函数设计与实现
1. 准确性奖励(Accuracy Reward)
准确性奖励是最直观的奖励函数,其目标是检查模型的回答是否在数学上等同于正确答案。
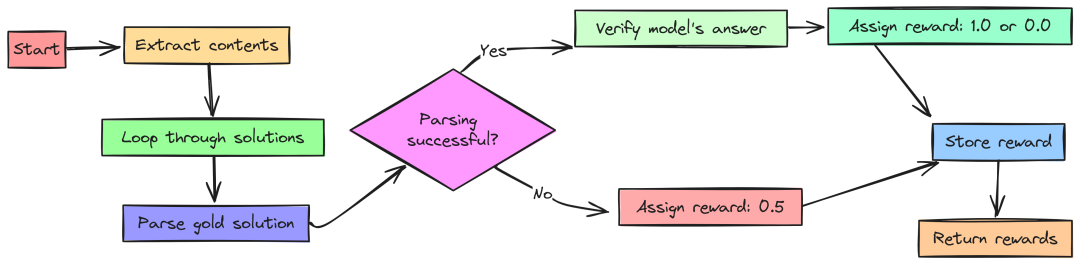
如果模型的回答正确,奖励为 1.0;如果回答错误,奖励为 0.0。如果正确答案无法解析,奖励为 0.5,以避免不公平的惩罚。
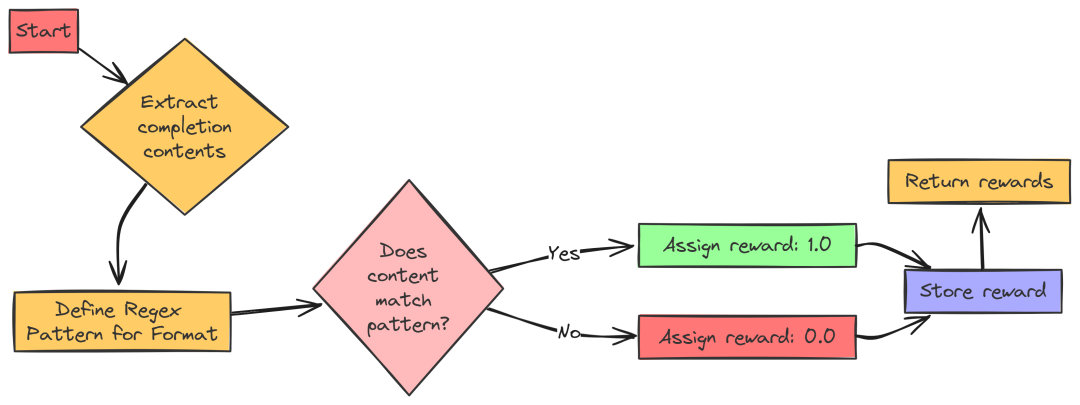
2. 格式奖励(Format Reward)
格式奖励确保模型的回答符合预定义的格式。具体来说,模型的回答需要包含和标签。如果格式正确,奖励为 1.0;否则为 0.0。
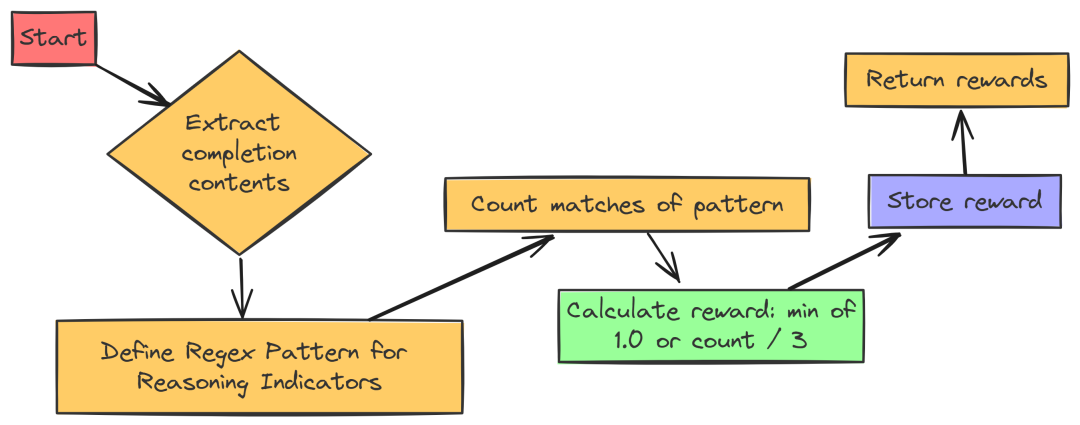
3. 推理步骤奖励(Reasoning Steps Reward)
推理步骤奖励鼓励模型展示其推理过程。它通过查找关键词和模式(如“Step 1:”、编号列表、项目符号、过渡词等)来评估推理步骤的清晰度。推理步骤越多,奖励越高。
4. 余弦缩放奖励(Cosine Scaled Reward)
余弦缩放奖励旨在鼓励模型生成简洁的答案,并对较长的错误答案给予较轻的惩罚。它通过余弦函数对答案长度进行缩放,以调整奖励值。
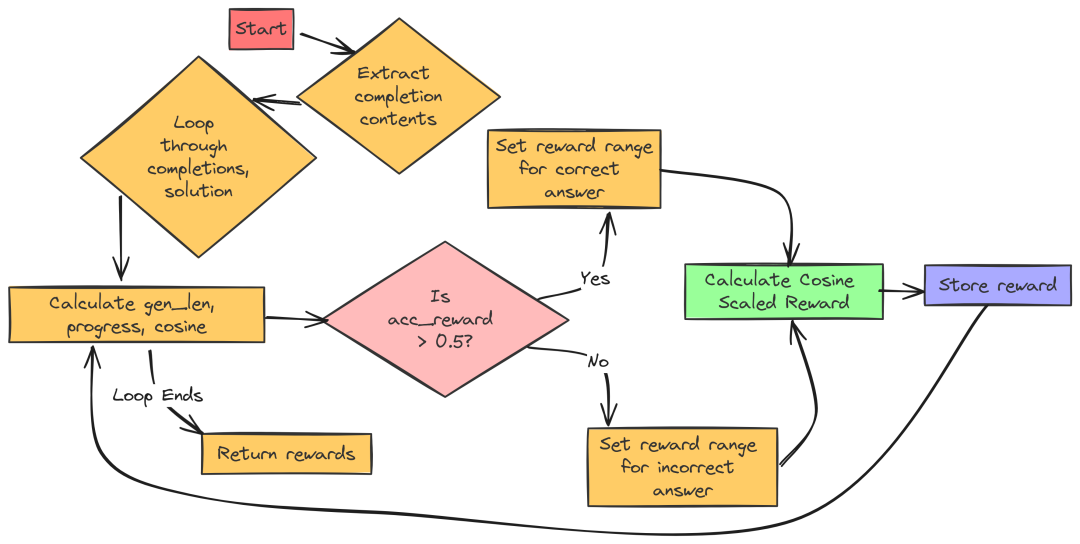
5. 重复惩罚奖励(Repetition Penalty Reward)
重复惩罚奖励旨在防止模型重复生成相同的短语或序列。它通过计算 n-gram 的重复率来评估模型的多样性,并对重复过多的回答给予负奖励。
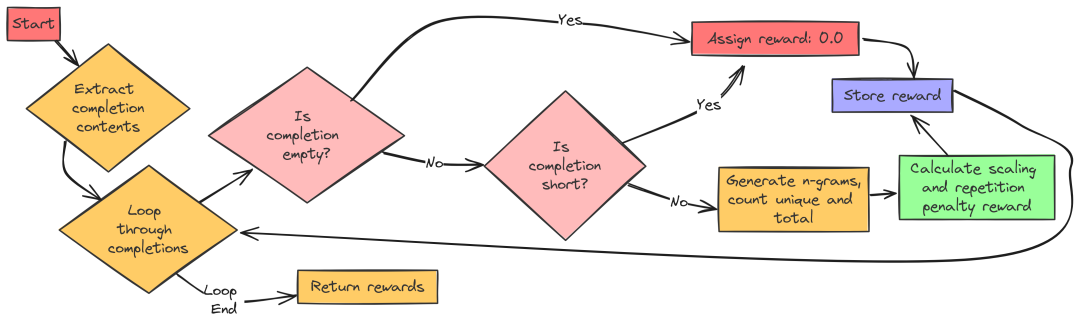
从 R1 Zero 到 R1
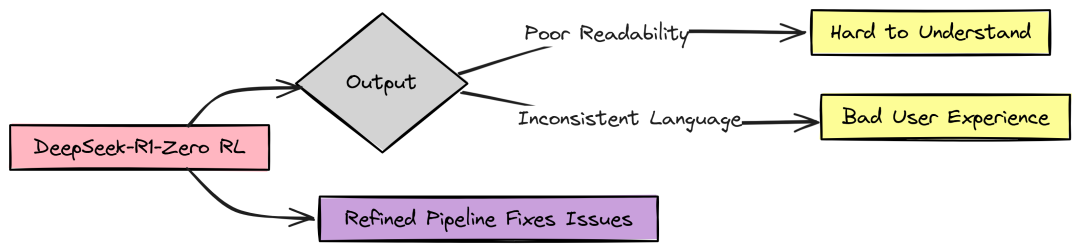
R1 Zero 的两大问题
尽管 R1 Zero 在推理测试中表现出色,甚至在某些任务上与更先进的模型(如 OpenAI-01–0912)不相上下,但它仍然存在一些关键问题,这些问题限制了其在实际应用中的表现:
-
推理过程难以理解
R1 Zero 的推理过程虽然能够生成正确的答案,但其逻辑和步骤往往难以理解。例如,模型在 <think> 标签中的推理过程可能显得杂乱无章,缺乏清晰的结构,这使得人类难以分析和理解其推理逻辑。
-
语言混合问题
当处理多语言问题时,R1 Zero 有时会在同一回答中混合使用不同语言,导致输出结果不一致且令人困惑。例如,当用西班牙语提问时,模型的回答可能是一团英语和西班牙语的混合体,这种语言混合问题严重影响了模型的可用性。
冷启动数据与监督微调
为了解决 R1 Zero 的问题,研究人员采用了冷启动数据(Cold Start Data)和监督微调(Supervised Fine-Tuning, SFT)的方法。这种方法的核心思想是为模型提供一个良好的推理基础,然后再进行强化学习训练。
-
冷启动数据的准备
冷启动数据是通过精心设计的训练数据集来实现的。这些数据集不仅包含问题和答案,还提供了清晰、结构化的推理过程示例。例如,Bespoke-Stratos-17k 数据集包含 17,000 个数学和代码问题,每个问题都配有详细的推理过程和答案,非常适合用于训练模型的推理能力。
-
监督微调(SFT)
监督微调是一种监督学习方法,通过提供输入和期望的输出对来训练模型。在 R1 的训练中,SFT 的目标是让模型学习如何生成清晰、结构化的推理过程,并避免语言混合问题。SFT 的训练过程可以分为以下几个步骤:
少样本提示(Few-shot Prompting)与直接提示(Direct Prompting)
为了进一步提升模型的推理能力,研究人员采用了少样本提示(Few-shot Prompting)和直接提示(Direct Prompting)的方法。
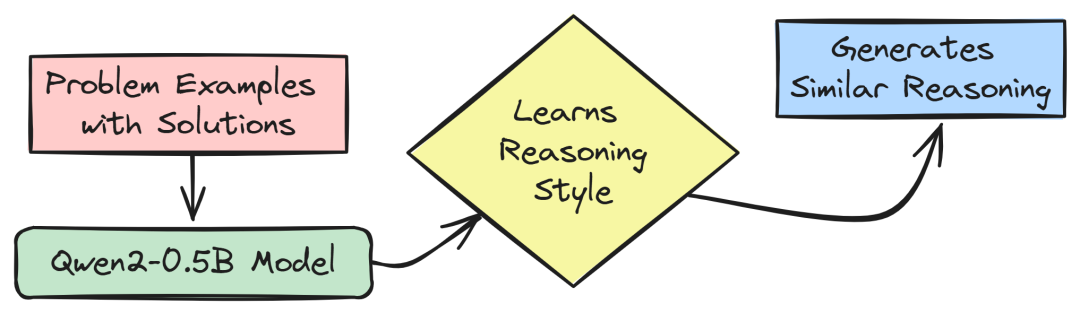
少样本提示通过向模型展示几个详细的推理示例,引导模型学习如何生成清晰、结构化的推理过程。例如,对于问题 “2 + 3 * 4”,可以提供以下示例:
Problem: What's the square root of 9 plus 5?
Solution: <|special_token|> First, find the square root of 9, which is 3. Then, add 5 to 3. 3 + 5 equals 8. <|special_token|> Summary: The answer is 8.
Problem: Train travels at 60 mph for 2 hours, how far?
Solution: <|special_token|> Use the formula: Distance = Speed times Time. Speed is 60 mph, Time is 2 hours. Distance = 60 * 2 = 120 miles. <|special_token|> Summary: Train travels 120 miles.
Problem: What is 2 + 3 * 4?
Solution:
通过这些示例,模型能够学习如何逐步解决类似的问题。
直接提示则通过直接向模型提出问题,并要求其逐步展示推理过程并验证答案。例如:
Problem: Solve this, show reasoning step-by-step, and verify:
What is 2 + 3 * 4?
这种方法直接引导模型生成详细的推理过程和验证步骤,从而提升其推理能力。
后处理优化(Post Processing Refinement)
为了进一步提升模型的输出质量,研究人员采用了后处理优化(Post Processing Refinement)的方法。这种方法通过人工标注和优化模型的输出,使其更加清晰、结构化。例如,将以下杂乱的输出:
<think> ummm... multiply 3 and 4... get 12... then add 2... </think>
<answer> 14 </answer>
<|special_token|> Reasoning: To solve this, we use order of operations, doing multiplication before addition.
Step 1: Multiply 3 by 4, which is 12.
Step 2: Add 2 to the result: 2 + 12 = 14.
<|special_token|> Summary: The answer is 14.
这种优化方法虽然简单,但却能显著提升模型输出的质量和可读性。
SFT 阶段 2:推理能力的进一步提升
在 SFT 阶段 1 的基础上,研究人员进一步优化了模型的推理能力。这一阶段的训练数据更加多样化,不仅包括推理任务,还涵盖了人类偏好的数据(例如,哪个输出更有帮助、更安全)。通过这种多样化的训练数据,模型不仅能够生成准确的答案,还能生成更有帮助、更安全的输出。
在这一阶段,奖励系统不仅关注答案的准确性,还关注模型输出的帮助性和安全性。具体来说:
-
帮助性:模型的输出是否有用、是否提供了足够的信息?
-
安全性:模型的输出是否安全、是否避免了偏见和不道德的内容?
通过这种奖励系统,模型能够在推理任务中表现出色,同时也能在其他场景中提供安全、有帮助的输出。
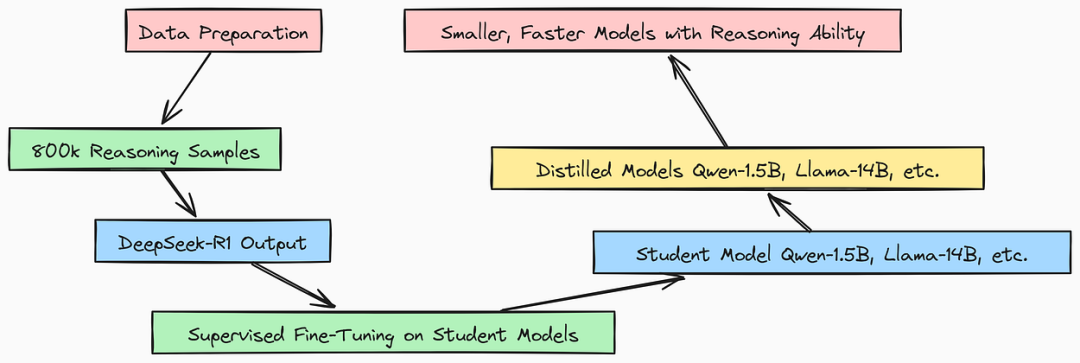
知识蒸馏(Distillation)
为了使 DeepSeek R1 更加实用,研究人员采用了知识蒸馏(Distillation)的方法。这种方法将大型“教师”模型(如 DeepSeek R1)的知识转移到小型“学生”模型中。通过这种方式,小型模型能够保留大型模型的推理能力,同时具备更快的运行速度和更低的资源消耗。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









