










本文来源公众号“CourseAI”,仅用于学术分享,侵权删,干货满满。
-
多模态检索增强生成 (MRAG) 通过将多模态数据(例如文本、图像和视频)集成到检索和生成过程中。
-
MRAG 通过扩展 RAG 框架以包含多模态检索和生成来解决此限制,从而实现更全面和上下文相关的响应。
-
在 MRAG 中,检索步骤涉及从多种模态中定位和整合相关知识,而生成步骤则利用多模态大型语言模型 (MLLM) 来生成包含多种数据类型信息的答案。
一、MRAG1.0
-
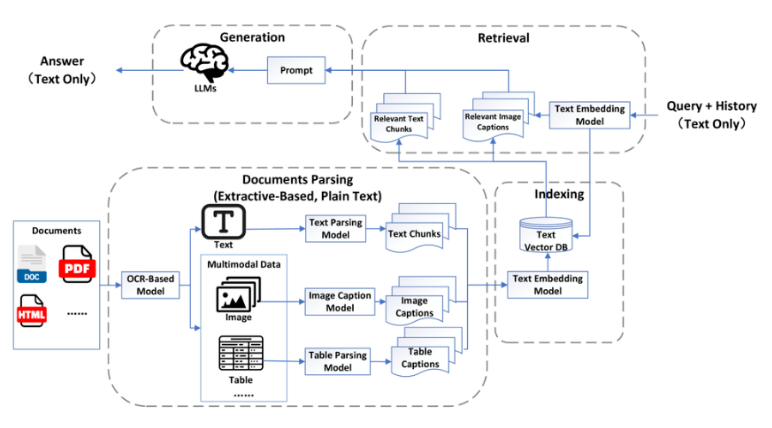
第一阶段与传统的 RAG 非常相似,包含三个模块:文档解析和索引、检索和生成。
-
关键区别在于文档解析阶段,采用专门的模型将不同的模态数据转换为特定于模态的标题。
-
然后将这些标题与文本数据一起存储,以便在后续阶段使用。
-
文档解析和索引:
-
此组件负责处理Word、Excel、PDF和HTML等格式的多模态文档。
-
使用光学字符识别 (OCR) 或特定格式的解析技术提取文本内容。
-
然后利用文档布局检测模型将文档分割成结构化元素,包括标题、段落、图像、视频、表格和页脚。
-
对于文本内容,采用分块策略对语义连贯的段落进行分割或分组。
-
对于多模态数据,使用专门的模型来生成描述图像、视频和其他非文本元素的标题。
-
这些片段和标题使用嵌入模型编码成向量表示,并存储在向量数据库中。
-
-
检索:
-
使用传统RAG相同的嵌入模型将用户查询编码成向量表示来处理它们。
-
然后,查询向量用于从向量数据库中检索最相关的片段和标题,通常使用余弦相似度作为相关性度量。
-
取前k个召回的片段和标题,合并以创建一组整合的外部知识,随后将其整合到生成阶段的提示中。
-
-
生成:
-
在生成阶段,MRAG 系统将用户的查询和检索到的文档合成一个连贯的提示。
-
大型语言模型 (LLM) 通过将其参数知识与检索到的外部信息相结合来生成响应。
-
这种方法增强了响应的准确性和及时性,尤其是在特定领域的环境中,同时降低了 LLM 输出中常见的幻觉风险。
-
在多轮对话中,系统将对话历史整合到提示词中,从而实现上下文感知和无缝交互。
-
MRAG1.0的局限性
-
繁琐的文档解析:
-
将多模态数据转换为文本描述为系统带来了巨大的复杂性。
-
这需要针对不同数据模态使用不同的模型进行处理,从而增加了计算开销和系统复杂性。
-
此外,转换过程常常导致多模态信息丢失。
-
例如,图像描述通常只提供粗粒度的描述,无法捕捉到精确检索和生成所需的关键细粒度细节。
-
-
检索瓶颈:
-
与传统的RAG类似,文本分割的切分策略常常会分割关键词,导致某些内容无法检索到。
-
此外,将多模态数据转换为文本,虽然能够检索非文本数据,但也引入了额外的信息丢失。
-
这些问题共同造成了瓶颈,限制了系统检索全面准确信息的能力。
-
-
生成方面
-
不仅需要处理文本片段,还需要处理图像描述和其他多模态数据。
-
将不同的元素有效地组织成连贯的prompt,同时最大限度地减少冗余并保留相关信息,是非常难的,非常影响生成响应的稳健性和可靠性。
-
二、 MRAG2.0
为了解决上述问题,MRAG2.0 通过文档解析和索引保留多模态数据,同时引入了多模态检索和多模态大语言模型进行答案生成,真正进入了多模态时代。
通过利用多模态大语言模型 (MLLM) 的能力,生成模块现在可以直接处理多模态数据,最大限度地减少数据转换过程中的信息丢失。
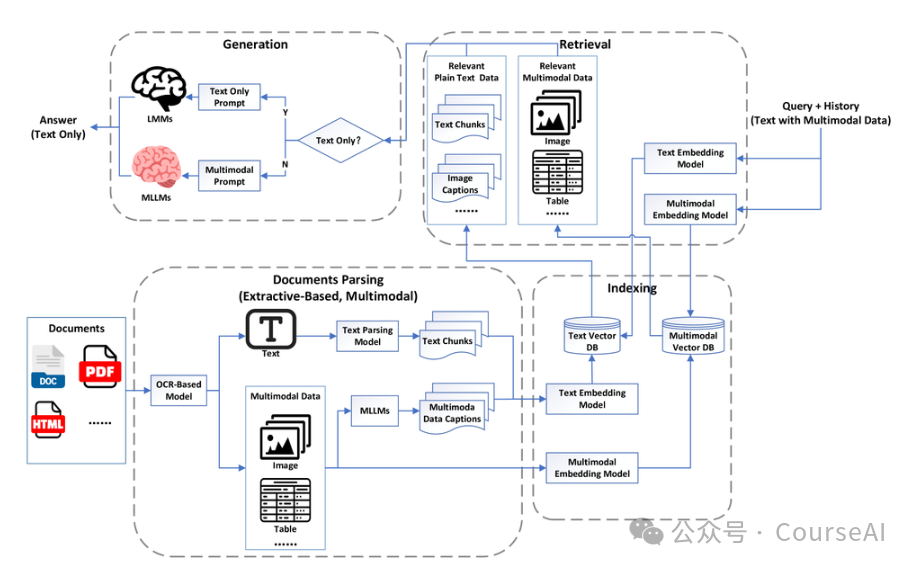
主要有以下三个优化点:
-
MLLMs 描述:
-
MRAG2.0 利用单个统一的 MLLM或多个 MLLM从多模态文档中提取图片描述。
-
取代了使用不同模态的独立模型的传统范式,简化文档解析模块并降低了其复杂性。
-
-
多模态检索:
-
MRAG2.0通过保留原始多模态数据,并启用跨模态检索来支持多模态用户输入。
-
允许基于文本的查询直接检索相关的多模态数据,将基于标题的召回与跨模态搜索能力相结合。
-
双重检索方法丰富了下游任务的数据来源,同时最大限度地减少了数据丢失,提高了下游任务的准确性和鲁棒性。
-
-
多模态生成:
-
MRAG2.0通过集成MLLM能够将用户查询和检索结果合成一个连贯的提示。
-
当检索结果准确且输入包含原始多模态数据时,生成模块可减轻通常与模态转换相关的信息丢失。
-
能显著提高了问答 (QA) 任务的准确性,尤其是在涉及相互关联的多模态数据的场景中。
-
MRAG2.0的局限性
-
集成多模态数据输入可能会降低传统文本查询描述的准确性。
-
当前的多模态检索能力仍然不如基于文本的检索,这可能会限制检索模块的整体准确性。
-
数据格式的多样性给生成模块带来了新的挑战。
-
有效地组织这些多样化的数据形式,并明确定义生成的输入是需要进一步探索和优先考虑的关键领域。
三、 MRAG3.0
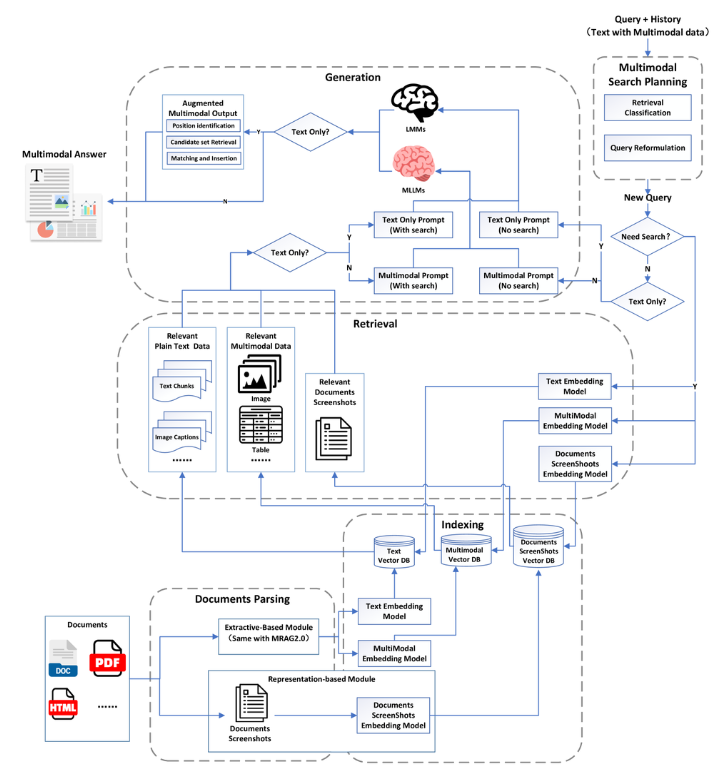
MRAG3.0在结构和功能上做了如下创新:
-
增强的文档解析:
-
在解析过程中保留文档页面截图,最大限度地减少数据库存储中的信息丢失。
-
-
真正的端到端多模态:
-
早期版本强调知识库构建和系统输入中的多模态能力,MRAG3.0引入了多模态输出能力,完成了端到端的多模态框架。
-
-
场景扩展:
-
传统方案主要应用于依赖知识库的VQA(视觉问答)场景
-
新范式通过模块调整和添加整合理解和生成能力。
-
1.3.1 MRAG3.0的改进
-
文档解析和索引
-
在解析过程中保留文档屏幕截图,解决以往方法固有的信息丢失问题。
-
利用微调的MLLM,将文档屏幕截图矢量化并建立索引,从而能够根据用户查询,有效检索相关的文档屏幕截图。
-
这种优化不仅提高了知识库的可靠性,也为高级多模态检索能力铺平了道路。
-
-
生成阶段
-
基于原生MLLM的输出:使用统一的MLLM一步生成所需的多模态输出,确保在统一的框架内无缝集成各种数据类型,例如文本、图像或音频。
-
增强的多模态输出:生成文本后,执行以下三个连续子任务:
-
1、位置识别:确定文本中最佳的插入点,以便在此处集成多模态元素(例如,图像、视频、图表)以补充或阐明内容。
-
2、候选集检索:通过查询和过滤最匹配文本上下文和意图的潜在候选者,从外部来源(例如网络或知识库)检索相关多模态数据。
-
3、匹配和插入:系统根据相关性、质量和一致性,从检索到的候选集中选择最合适的多模态元素。
-
然后将所选数据无缝集成到已识别的位置,从而生成连贯且丰富的多模态答案。
-
在MRAG架构层面统一推理和生成场景。
-
通过结合多模态输出增强子模块,它促进了从基于文本的答案向混合多模态答案的转变。
-
生成的实现方法有两类:
-
-
多模态搜索规划
-
通过整合文本和视觉线索来改进查询,从而提高检索的准确性和全面性。
-
用于确定多模态查询的相关性和类别,以引导搜索指向最合适的数据源。
-
例如,在多跳的场景中,在初始一轮中检索视觉信息后,检索分类模块可以利用累积的知识来确定后续动作,是继续基于文本检索还是直接生成
-
检索分类:
-
查询改写:
-
四、案例应用
4.1 视觉问答 (VQA)
-
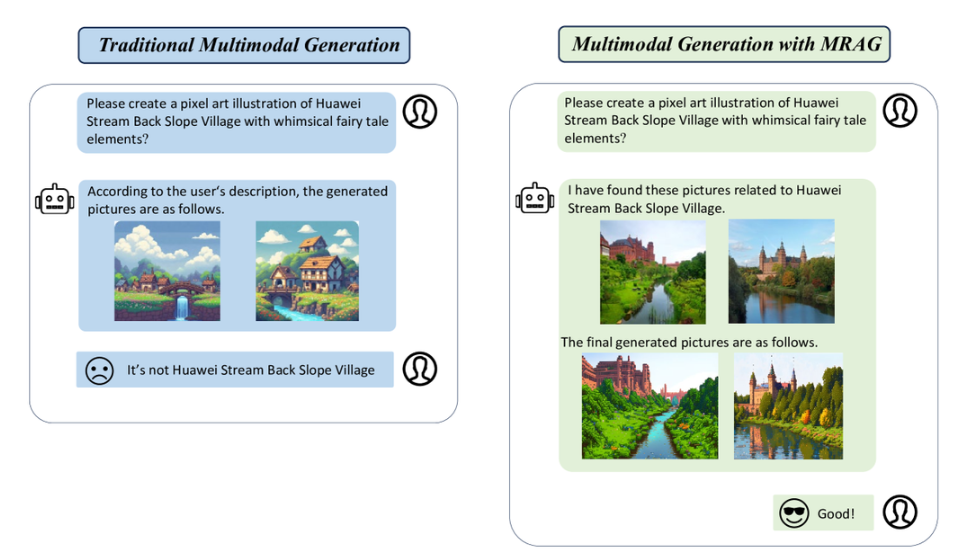
用户的目标是生成描绘“Huawei Stream Back Slope Village.”的图像。
-
由于该位置的模糊性和模型知识的有限性,它可能会产生不准确的表示,例如:溪流旁房屋的图像。
-
通过集成检索增强功能,模型可以预先访问相关信息,从而生成精确且符合语境的图像。
4.2 融合多模态输出
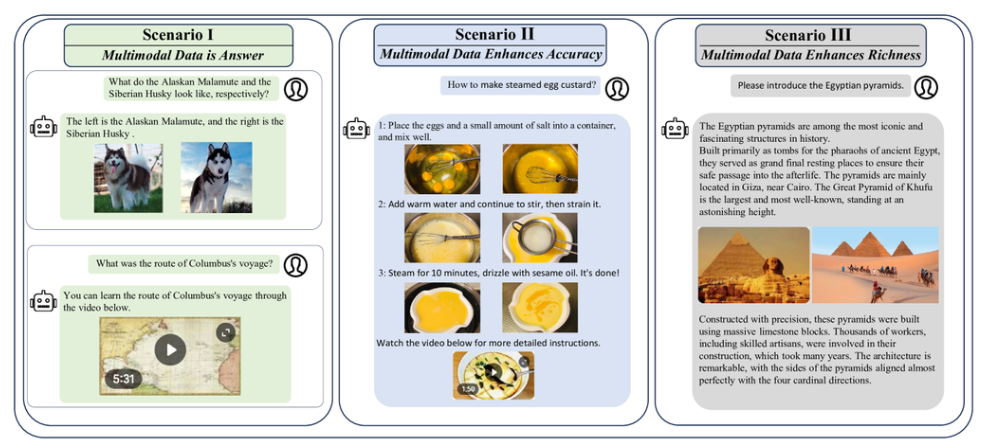
问答场景中的多模态输出可以分为三种不同的类型。
-
在子场景I中,用户的查询只需使用图像或视频即可完全解决,无需补充文本信息。
-
在子场景II涉及一个结合文本和图像的逐步解释,以确保清晰和精确;省略图像可能会导致用户在特定步骤感到困惑。
-
在子场景III中,补充图像丰富了答案中传达的信息,但删除它们不会影响答案的准确性。
下期,介绍多模态RAG的五个关键技术,敬请期待!
https://arxiv.org/pdf/2504.08748
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 907
907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









