









本文来源公众号“AI生成未来”,仅用于学术分享,侵权删,干货满满。
原文链接:只需一张图,万物皆可插!Insert Anything开源啦!开创AI图像插入新时代|浙大&哈佛等

文章链接:https://arxiv.org/pdf/2504.15009
开源地址:https://song-wensong.github.io/insert-anything/


亮点直击
发布了AnyInsertion数据集,这是一个包含120K提示-图像对的大规模数据集,涵盖了广泛的插入任务,例如人物、物体和服装插入。
提出了Insert Anything框架,这是一个统一框架,通过单一模型无缝处理多种插入任务(人物、物体和服装)。
首个利用DiT(Diffusion Transformer)进行图像插入的研究,充分发挥了其在不同控制模式下的独特能力。
开发了上下文编辑技术,采用双联画(diptych)和三联画(triptych)提示策略,将参考元素无缝整合到目标场景中,同时保持身份特征。
商业广告和流行文化领域有大应用




总结速览
解决的问题
-
任务局限性:现有方法仅针对特定任务(如人物插入、服装插入),缺乏通用性。
-
控制模式单一:依赖固定控制方式(仅掩码或仅文本引导),灵活性不足。
-
视觉-参考不协调:插入内容与目标场景风格不一致,或丢失参考图像的细节特征。
提出的方案
-
AnyInsertion 数据集:
-
包含 120K 提示-图像对,覆盖人物、物体、服装插入等多样化任务。
-
支持多控制模式(58K mask-提示对 + 101K 文本-提示对)。
-
-
统一框架 Insert Anything:
-
掩码提示双联画(Mask-prompt diptych):左参考图 + 右掩码目标图。
-
文本提示三联画(Text-prompt triptych):左参考图 + 中源图 + 右文本生成结果。
-
基于 Diffusion Transformer (DiT) 的多模态注意力机制,联合建模文本、掩码与图像关系。
-
上下文编辑机制:将参考图像作为上下文,通过两种提示策略实现自适应融合:
-
应用的技术
-
扩散Transformer(DiT) :利用其多模态注意力机制,支持掩码和文本双引导编辑。
-
上下文学习:通过参考图像与目标场景的隐式交互,保持特征一致性。
-
多样化提示策略:适配不同控制模式,确保插入内容的自然融合。
达到的效果
-
通用性强:单一模型支持多任务(人物、物体、服装插入等),无需针对任务单独训练。
-
灵活控制:同时支持掩码引导和文本引导编辑,满足多样化需求。
-
高质量生成:
-
在 AnyInsertion、DreamBooth 和 VTON-HD 基准测试中优于现有方法。
-
保留参考图像细节特征,同时实现与目标场景的颜色、纹理和谐融合。
-
-
应用广泛:适用于创意内容生成、虚拟试衣、场景合成等实际场景。
AnyInsertion数据集
为了实现多样化的图像插入任务,提出了一个新的大规模数据集AnyInsertion。首先与现有数据集进行比较,随后详细描述数据集构建过程,最后提供详细的数据集统计信息。
与现有数据集的比较
现有数据集存在以下局限性:
-
数据类别有限:FreeEdit数据集主要关注动植物,VITON-HD数据集专攻服装领域。即使AnyDoor和MimicBrush包含大规模数据,它们也仅涉及极少量的人物插入样本。
-
提示类型受限:FreeEdit仅提供文本提示数据,而VITON-HD仅支持掩码提示数据。
-
图像质量不足:AnyDoor和MimicBrush使用了大量视频数据,这些视频数据集常存在低分辨率和运动模糊问题。
为解决这些问题,本文构建了AnyInsertion数据集。如下表1所示,与现有数据集[5,11]相比,AnyInsertion涵盖多样类别,提供更高分辨率图像,同时支持掩码和文本提示,并包含更多样本。

数据构建
数据收集
图像插入需要成对数据:包含待插入元素的参考图像,以及插入操作的目标图像。如下图2a所示,采用图像匹配技术创建目标-参考图像对,并从互联网来源收集对应标签,利用大量展示配饰及佩戴者的图像。对于物体相关数据,我们从MVImgNet中选择多视角常见物体图像作为参考-目标对。对于人物插入,我们应用头部姿态估计从HumanVid数据集中筛选头部姿态相似但身体姿态不同的高分辨率真实场景视频帧,并通过模糊检测过滤过度运动模糊的帧,获得高质量人物插入数据。

数据生成
本文的框架支持两种控制模式:掩码提示和文本提示。
-
掩码提示编辑:需要掩码指定目标图像的插入区域,使用参考图像元素填充目标图像的掩码区域。每个数据样本表示为元组:(参考图像,参考掩码,目标图像,目标掩码)。具体使用Grounded-DINO和Segment Anything(SAM)从输入图像和标签生成参考与目标掩码。
-
文本提示编辑:需要文本描述参考图像元素如何插入源图像以形成目标图像。每个数据样本表示为元组:(参考图像,参考掩码,目标图像,源图像,文本)。源图像、文本描述和参考掩码按以下方式生成:
-
源图像生成:通过对目标图像应用替换或移除操作生成。替换操作使用类别特定指令模板(如“将[source]替换为[reference]”)和基于文本的编辑模型生成初始编辑。为保持图像协调性,采用FLUX.1 Fill[dev]保留未编辑区域,仅修改掩码区域。移除操作则使用DesignEdit模型结合目标掩码获得结果。
-
文本生成:替换操作适配指令模板(如“将[source]替换为[reference]”),添加操作使用格式“添加[label]”描述变换。
-
参考掩码提取:方法与掩码提示编辑相同。
-
数据集概览
AnyInsertion数据集包含训练和测试子集。训练集共159,908个样本,分为两类提示:
-
58,188个掩码提示图像对(参考图像、参考掩码、目标图像、目标掩码)
-
101,720个文本提示图像对(参考图像、参考掩码、源图像、目标图像、文本)
如前面图2b所示,数据集覆盖人类主体、日用品、服装、家具和各类物体等多样类别,支持人物插入、物体插入和服装插入等多种任务,适用于广泛的实际应用。评估使用的测试集包含158对数据:120对掩码提示和38对文本提示。掩码提示子集包括40对物体插入、30对服装插入和60对人物插入(30对简单场景和30对复杂场景)。
Insert Anything 模型
概述
图像插入任务需要三个关键输入:
-
包含待插入元素的参考图像
-
提供背景环境的源图像
-
指导插入过程的控制提示(掩码或文本)
目标是生成一个目标图像,将参考图像中的元素(以下简称“参考元素”)无缝整合到源图像中,同时满足:
-
保持参考元素的身份特征(定义该元素的视觉特征)
-
严格遵循提示的规范
如下图3所示,本文的方法包含三个核心组件:
-
多联画上下文格式:通过组织输入数据利用上下文关系
-
语义引导机制:从文本提示或参考图像中提取高层信息
-
基于DiT的架构:通过多模态注意力融合上述元素
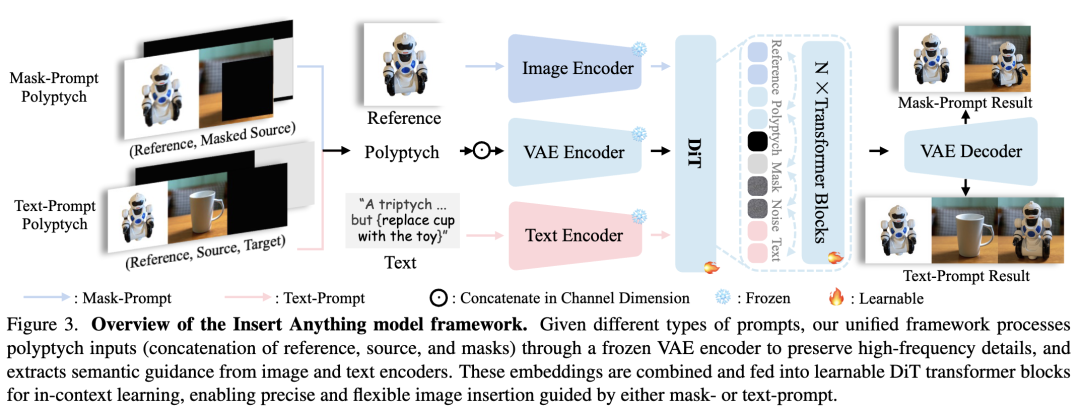
这些组件共同实现了灵活控制,同时确保插入元素与周围环境的视觉协调性。
上下文编辑
上下文编辑的核心是将参考元素整合到源图像中,同时维持它们之间的上下文关系。具体步骤如下:


多控制模式
本文的框架支持两种图像插入控制模式:
-
掩码提示:通过手动标注掩码指定插入区域
-
文本提示:通过文字描述控制插入过程
这两种模式通过以下架构实现灵活整合:
多模态注意力机制
基于DiT的多模态注意力机制,采用双分支结构:
-
图像分支:处理视觉输入(参考图像/源图像/对应掩码)
-
将输入编码为特征表示
-
沿通道维度与噪声拼接以准备生成
-
-
文本分支:编码文本描述以提取语义引导

掩码提示(Mask-Prompt)
在掩码提示编辑中,源图像的插入区域通过二进制掩码指定。该掩码与经过VAE处理的双联画沿通道维度拼接后,与噪声一起输入DiT模型的图像分支。同时,通过CLIP图像编码器提取参考图像的语义特征并传入文本分支,以提供上下文引导。
文本提示(Text-Prompt)
在文本提示编辑中,插入操作由文本描述引导。参考图像指示预期修改内容,而文本提示具体说明变更要求。源图像将根据文本描述进行相应调整。为此我们设计专用提示模板:"一幅由三张并置图像组成的三联画。左侧是[label]的照片;右侧场景与中部完全相同,但左侧需[instruction]。" 该结构化提示提供语义上下文——[label]标识参考元素类型,[instruction]指定修改要求。输入经文本编码器处理后引导DiT文本分支,三联画结构经VAE处理输入图像分支,文本标记与图像特征拼接以实现分支间的联合注意力。
实验
实验设置
实现细节
本文的方法基于FLUX.1 Fill [dev]——一种采用DiT架构的图像修复模型。框架整合了T5文本编码器与SigLIP图像编码器,并使用秩为256的LoRA进行微调。训练时,掩码提示的批大小为8,文本提示为6,所有图像统一处理为768×768像素分辨率。采用Prodigy优化器,启用安全预热(safeguard warmup)和偏置校正(bias correction),权重衰减设为0.01。实验在4块NVIDIA A800 GPU(每块80GB)集群上完成。训练数据主要来自自建的AnyInsertion数据集,针对两种提示类型(掩码与文本)各训练5000步。采样阶段执行50次去噪迭代,训练损失函数遵循流匹配(flow matching)方法。
测试数据集
在三个多样化数据集上评估方法性能:
-
Insert Anything:从自建的Insert Anything数据集中选取40个样本用于物体插入评估,30个用于服装插入,30个用于人物插入(简单场景);
-
DreamBooth:构建含30组图像的测试集,每组包含一张参考图像和一张目标图像;
-
VTON-HD:作为虚拟试穿与服装插入任务的标准基准。
定量结果
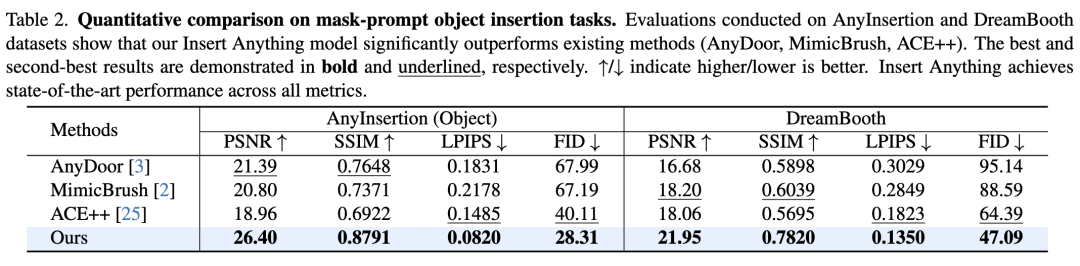
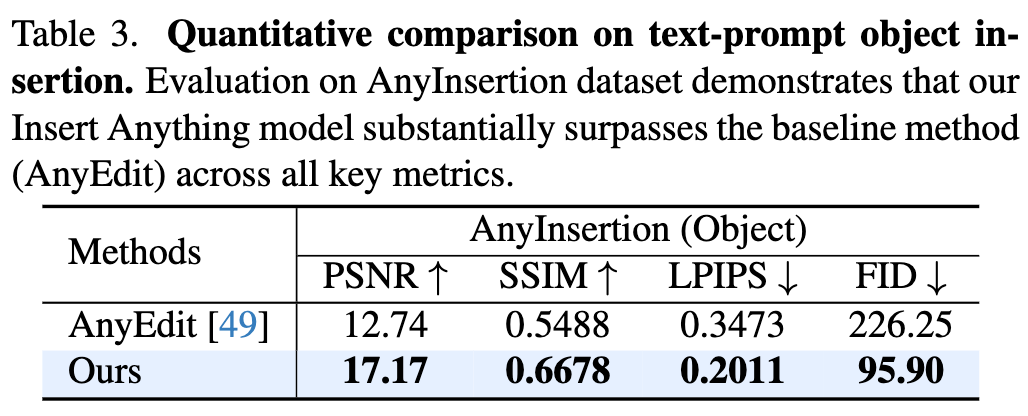
物体插入性能
如下表2和表3所示,Insert Anything在掩码提示和文本提示的物体插入任务中,所有指标均超越现有方法。掩码提示插入任务中,本方法将AnyInsertion数据集的SSIM从0.7648提升至0.8791,DreamBooth数据集从0.6039提升至0.7820;文本提示插入任务中LPIPS从0.3473降至0.2011,表明感知质量显著提升。这些改进证明了模型在保持物体身份特征的同时,能与目标场景实现完美融合的卓越能力。
服装插入性能
如下表4所示,Insert Anything在两个评估数据集上全面超越统一框架和专用服装插入方法。在广泛使用的VTON-HD基准测试中,LPIPS从0.0513优化至0.0484,同时PSNR(26.10 vs. 25.64)和SSIM(0.9161 vs. 0.8903)均有显著提升。与ACE++等统一框架相比优势更为明显,印证了本方法在专用任务质量与统一架构结合方面的有效性。

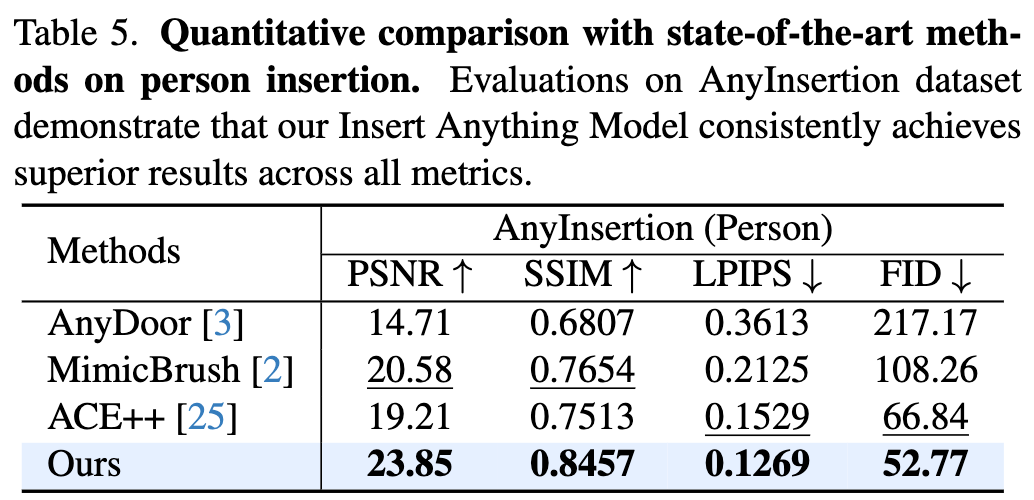
人物插入性能
如下表5所示,在AnyInsertion数据集的人物插入任务中,本方法所有指标均显著领先。相比原有最佳结果,结构相似性(SSIM: 0.8457 vs. 0.7654)和感知质量(FID: 52.77 vs. 66.84)提升尤为突出,这在需要保持人物身份特征的复杂插入场景中具有重要意义。
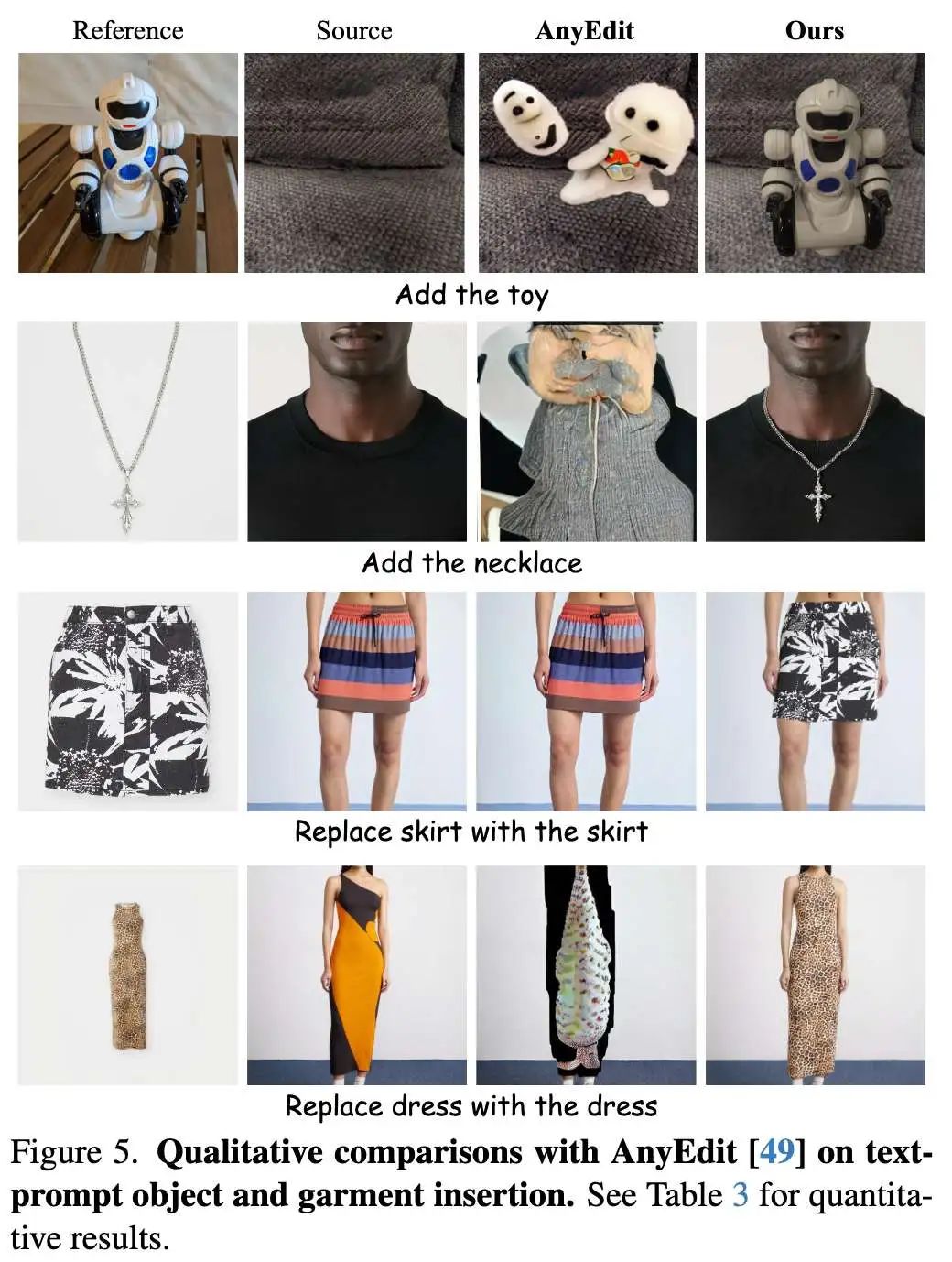
定性分析
下图4展示了三类任务的视觉对比结果,凸显Insert Anything的三大优势:

-
物体插入:在物体-人物/物体-物体交互的复杂场景中,能完美保持参考物体细节特征并实现自然融合;
-
服装插入:对服装logo/文字保留和裤裙转换等形状变化任务,细节保持和自然贴合度均优于专用方法;
-
人物插入:在人物-人物/人物-动物/人物-物体交互场景中,身份特征保持与场景融合效果最佳。
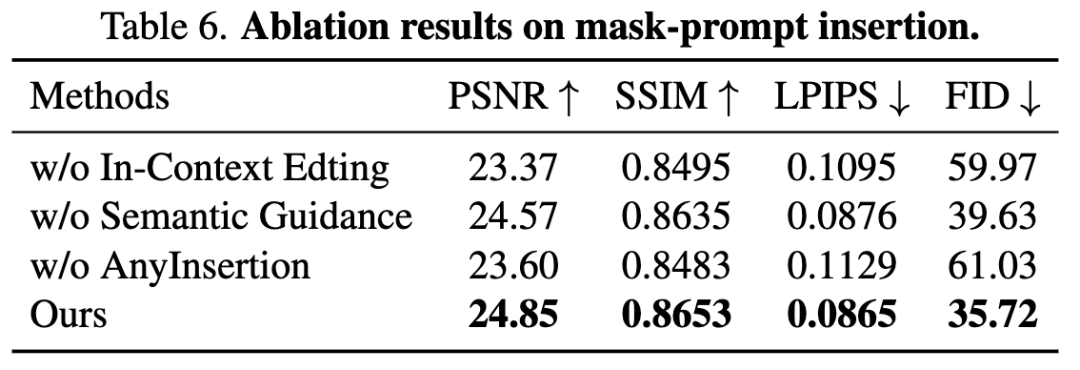
消融实验
针对掩码提示插入任务进行消融研究(下表6为加权平均结果,权重比=物体:服装:人物=4:3:3):
-
上下文编辑:移除该模块会导致纹理等高频细节丢失(下图6),PSNR/SSIM/LPIPS指标显著下降;
-
语义引导:取消参考图像语义引导时,生成图像会丢失颜色等高阶特征(图6);
-
AnyInsertion数据集:仅使用免训练模型推理时,人物面部细节保持能力明显退化(图6),所有指标同步下降。

结论
本文提出统一框架Insert Anything,通过支持掩码/文本双引导模式突破专用方法局限。基于12万提示-图像对的AnyInsertion数据集和DiT架构,创新性地采用双联画/三联画提示策略实现上下文编辑机制,在保持身份特征的同时确保视觉协调性。三大基准测试表明,本方法在人物/物体/服装插入任务中全面超越现有技术,为基于参考的图像编辑树立新标杆,为实际创意应用提供通用解决方案。
参考文献
[1] Insert Anything: Image Insertion via In-Context Editing in DiT
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 309
309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









