









本文来源公众号“Coggle数据科学”,仅用于学术分享,侵权删,干货满满。
原文链接:行业落地分享:蚂蚁TuGraph图数据库
随着数据量的爆发式增长,传统的搜索方式已经难以满足用户对精准信息的需求。GraphRAG(Retrieval-Augmented Generation)作为一种创新的搜索技术,结合了检索和生成的优势,为 AI 搜索带来了新的突破。
TuGraph 产品介绍
图(Graph)是一种由顶点(Vertex)和边(Edge)构成的数据结构。顶点代表实体或概念,而边则表示这些实体和概念之间的关系。
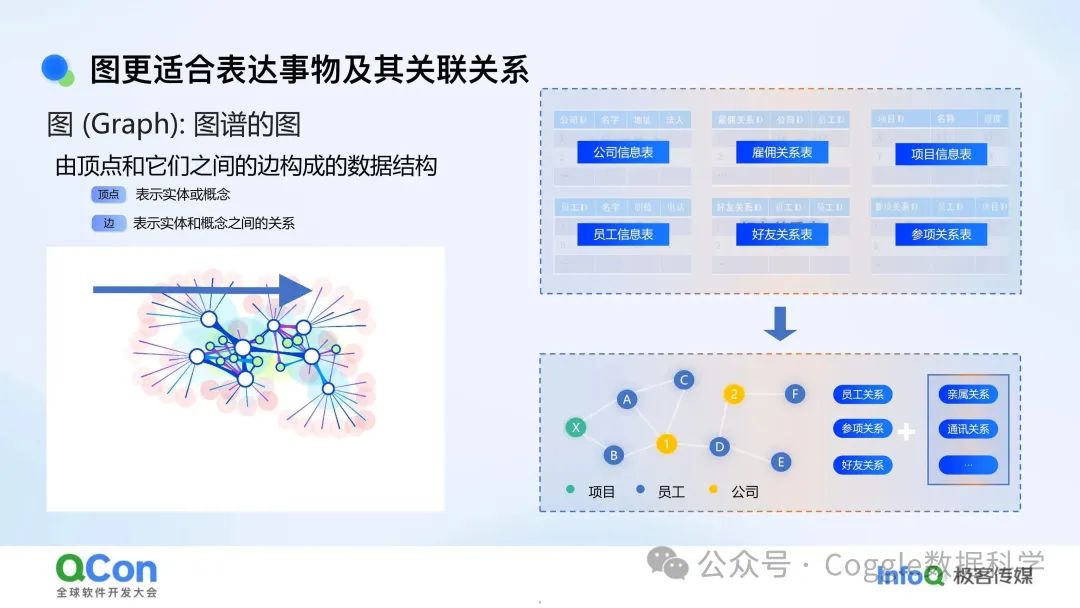
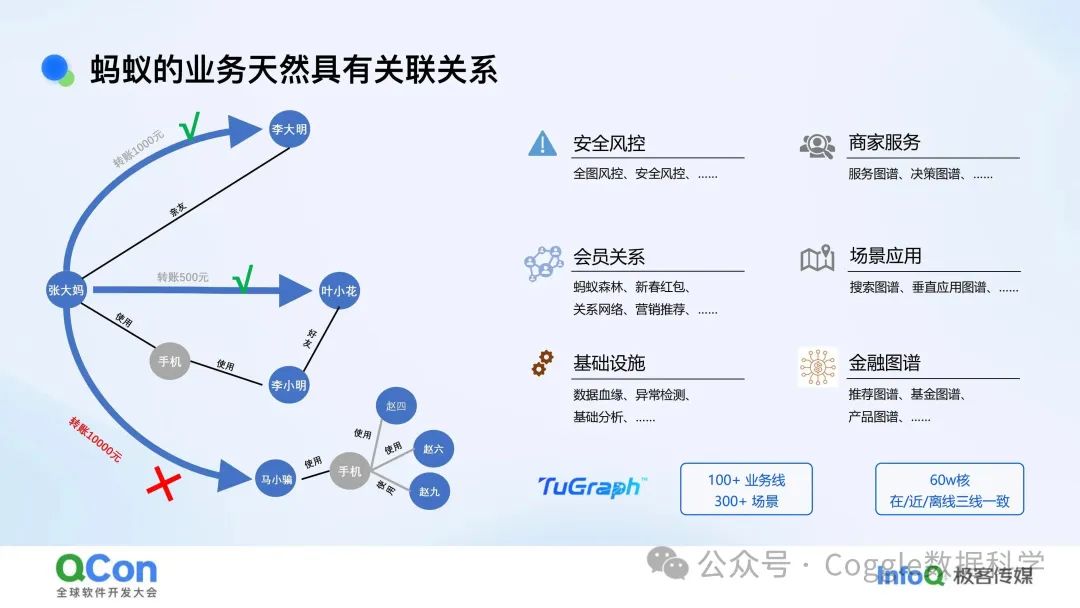
这种结构非常适合表达事物之间的复杂关联关系。比如,公司信息表、雇佣关系表、项目信息表、员工信息表、好友关系表等,都可以用图数据库来高效地存储和管理。
在图数据库中,每个节点(顶点)可以代表一个实体,比如一个人、一个项目、一个公司;而边则可以表示这些实体之间的关系,比如“雇佣”“参与”“好友”“亲属”“通讯”等。通过这种结构,我们可以清晰地看到事物之间的联系,而不仅仅是孤立的数据。
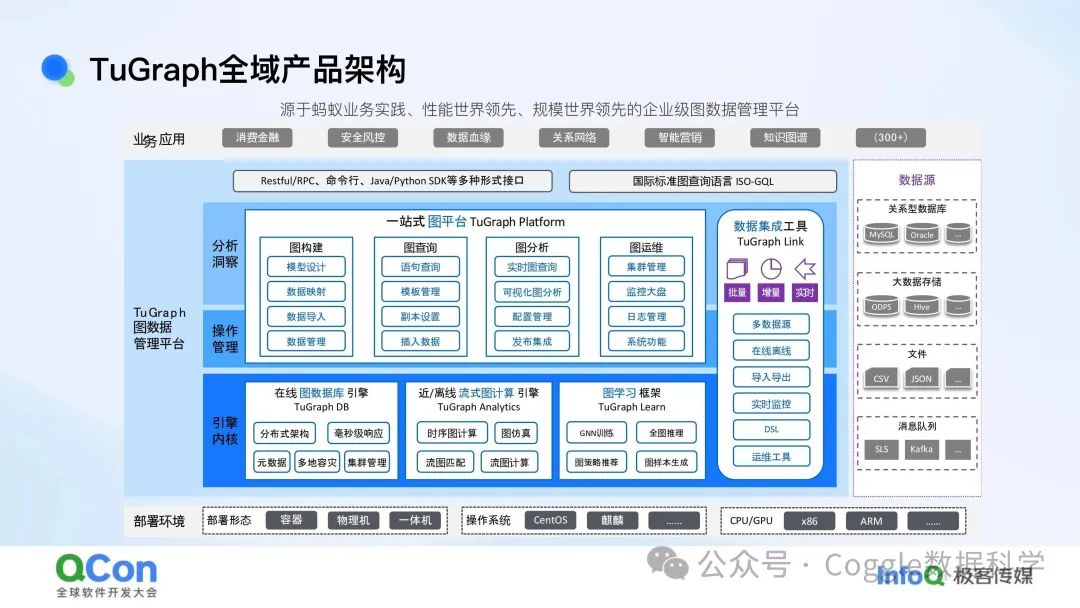
TuGraph™ 是一款源于蚂蚁集团业务实践的图数据管理平台,它在性能和规模上均处于世界领先水平。
TuGraph Platform 是 TuGraph™ 的一站式图平台,它为企业提供了一个完整的图数据管理和分析解决方案。通过 TuGraph Platform,用户可以轻松完成图数据的构建、查询、分析和运维。
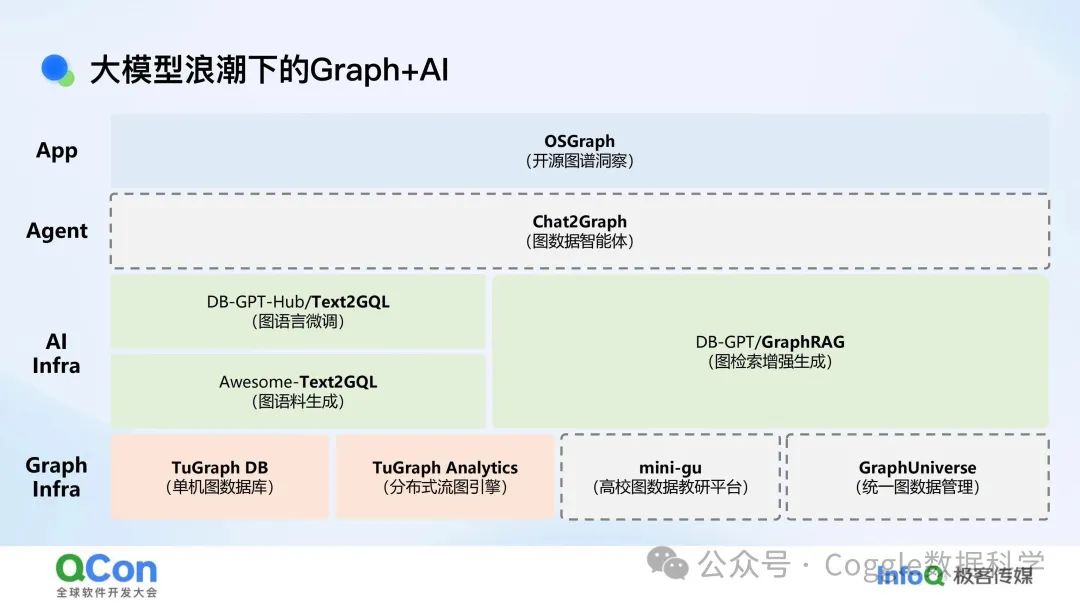
GraphRAG 增强AI检索
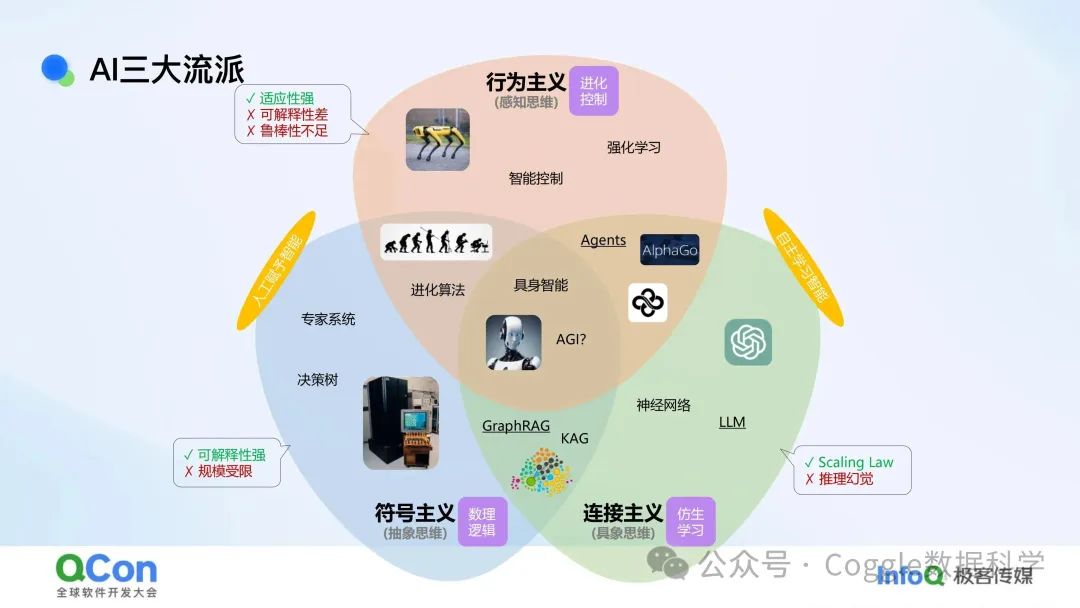
人工智能(AI)的发展历程中,出现了三大流派:行为主义、符号主义和连接主义。每个流派都有其独特的理念、方法和应用场景,它们共同推动了AI技术的进步。
-
行为主义是AI的早期流派之一,它强调通过感知和控制来实现智能行为。
-
符号主义是AI的另一大流派,它强调通过符号和逻辑来实现智能。
-
连接主义是AI的第三大流派,它强调通过神经网络来模拟人脑的神经元连接,从而实现智能。
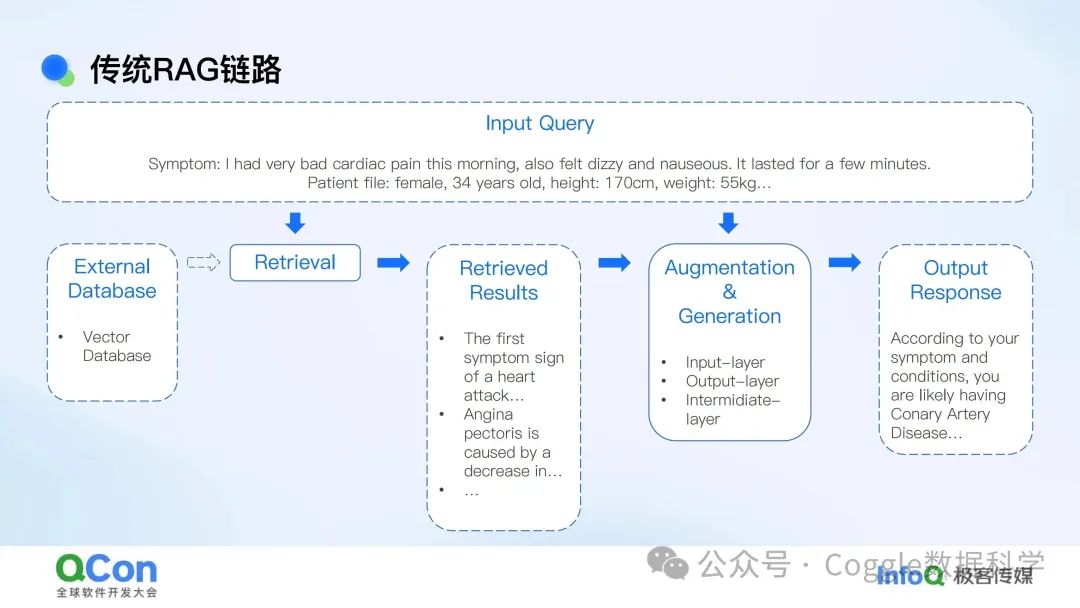
RAG链路是一种结合了检索(Retrieval)和生成(Generation)的自然语言处理技术。它通过检索外部数据库中的相关信息,增强语言生成模型的上下文理解能力,从而生成更准确、更有针对性的回答。
-
RAG链路的起点是用户的输入查询。以医疗场景为例,用户可能会输入一段描述自己症状和身体状况的文字。
-
在用户输入查询后,RAG链路会进入检索阶段。系统会将用户的输入查询发送到外部数据库,这些数据库可以是医学知识库、患者病历、文献资料等。
-
检索到相关信息后,RAG链路进入增强与生成阶段。系统会将检索到的结果与用户的输入查询结合起来,通过一个预训练的语言生成模型(如Transformer架构)生成最终的回答。
传统 RAG 方法在处理文档时,往往将每个文档视为独立的单元,忽略了文档之间的关系。相比之下,GraphRAG 通过图结构捕捉并利用信息片段之间的关系,为每个片段提供了更丰富的上下文。它能够识别文本中的实体(如艺术家、艺术流派)以及它们之间的关系(如影响、继承),并以图的形式将这些信息组织起来。
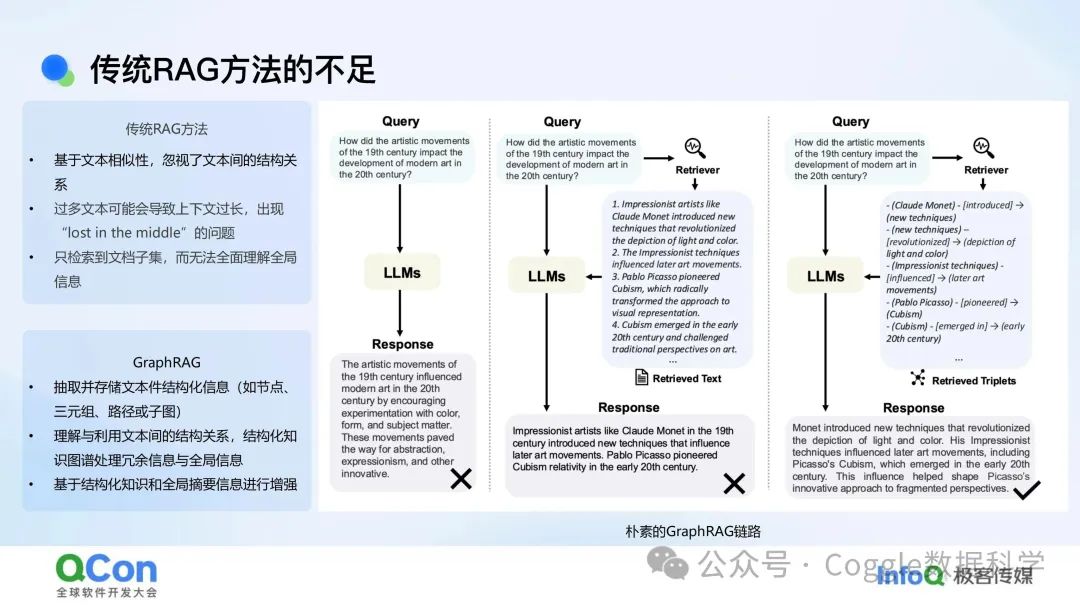
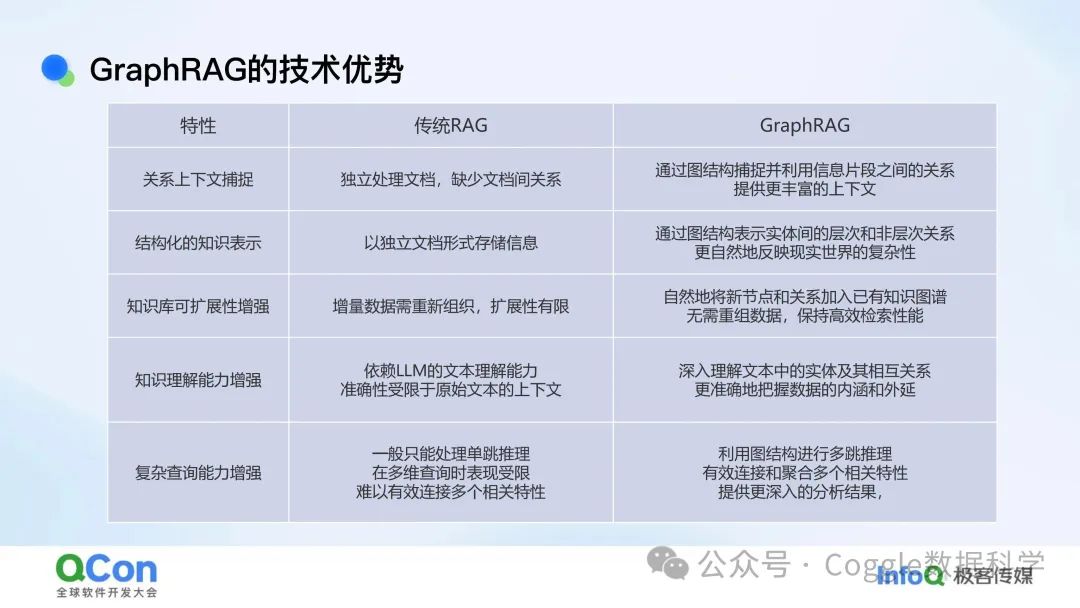
GraphRAG 则通过图结构表示实体间的层次和非层次关系,提供了一种更自然、更立体的知识表示方式。GraphRAG 则能够自然地将新节点和关系加入已有知识图谱,无需重组数据,从而保持高效的检索性能。GraphRAG 则利用图结构进行多跳推理,能够有效连接和聚合多个相关特性。它可以通过图路径分析,从一个实体出发,沿着关系边逐步推理到其他相关实体,从而提供更深入的分析结果。
GraphRAG ⽅法与实践
GraphRAG框架是一种结合了图数据库和生成式语言模型的创新架构,旨在通过图结构的检索和增强,提升智能问答系统的性能和用户体验。它从用户输入的查询开始,经过一系列复杂的处理步骤,最终生成高质量的回答。
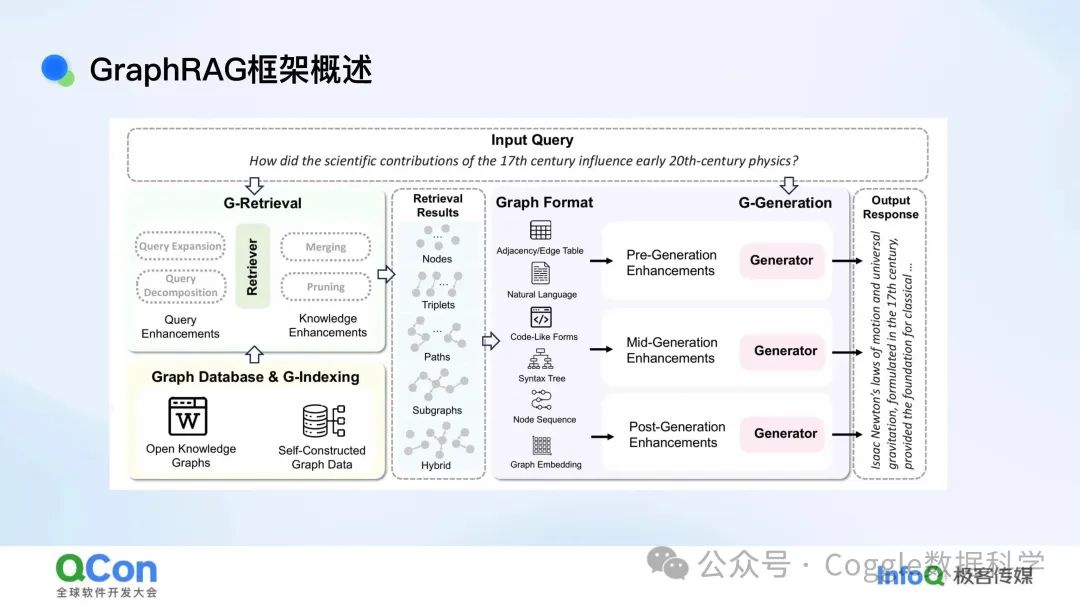
1. 输入查询:用户的问题
一切始于用户的输入查询。例如,用户可能会问:“17世纪的科学贡献如何影响20世纪初的物理学?”这个问题涉及多个历史时期和复杂的科学概念,需要系统深入理解并提供全面的回答。
2. G-Retrieval:图检索与增强
-
查询扩展与分解
在GraphRAG框架中,输入的查询首先会经过查询扩展和分解。系统会自动识别查询中的关键概念和关系,并将其分解为更细粒度的子查询。例如,“17世纪的科学贡献”和“20世纪初的物理学”会被分别处理,同时系统还会扩展相关的概念,如“牛顿的运动定律”和“经典力学”。
-
检索与合并
接下来,系统会利用图数据库和G-Indexing(图索引)技术,从开放知识图谱和自建图数据中检索相关信息。这些信息可能包括节点(如科学家、科学理论)、三元组(如“牛顿-提出-运动定律”)、路径和子图。检索结果会经过合并和剪枝,去除冗余信息,保留最相关的内容。
-
知识增强
检索到的结果不仅包括文本信息,还会以图的形式呈现,如邻接表、边表、代码形式、语法树或节点序列等。这些图结构的信息为后续的生成过程提供了丰富的上下文和结构化知识。
3. G-Generation:图增强生成
-
预生成增强 在生成回答之前,系统会对检索到的图结构信息进行预处理。这一步骤包括对图的嵌入(Graph Embedding)和对关键节点的标注,以便生成器更好地理解信息的结构和重要性。
-
生成过程
生成器会根据处理后的图结构信息,生成初步的回答。这个过程不仅考虑了文本内容,还利用了图结构中的关系和层次信息,使得生成的回答更加连贯和准确。
-
后生成增强
生成的回答会经过进一步的优化和校验。系统会检查回答的逻辑连贯性,确保所有提到的概念和关系都与原始查询一致。同时,系统还会利用图数据库中的额外信息,对回答进行补充和细化。
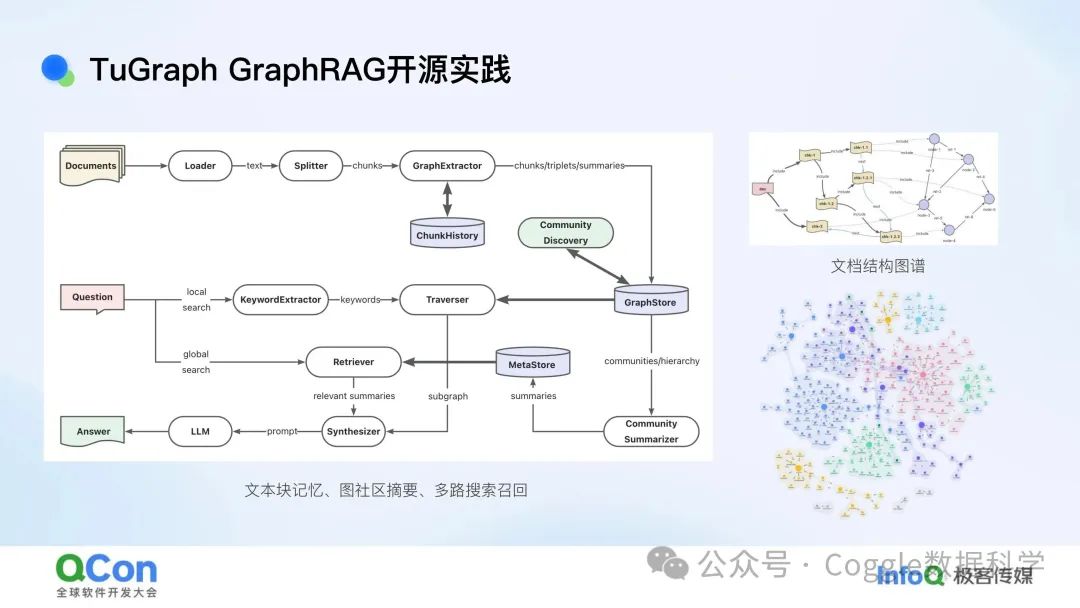
⾃然语⾔驱动的GraphRAG




THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









