







【导读】目前 58 旗下存在租房、安居客、招聘、二手车、黄页等多个业务线,其中每个业务线在 58 APP 中存在一个或多个业务 pod。在研发层面上,58 同城其实早已实现了并行研发,不过,在并行研发极大地提高了研发效率的同时,我们还发现 APP 体积对 APP 的下载和留存有着重要的影响。
那么如何在业务场景不断增长的情况下,实现 APP 的瘦身。对此,来自 58 同城用户价值增长部 iOS 技术部的邓竹立,分享了快速便捷地分析出业务模块的体积与增量的最佳实践,希望对大家有所裨益。
作者 | 邓竹立,用户价值增长部 iOS 技术部
责编 | 屠敏
出品 | CSDN(ID:CSDNnews)
伴随着需求场景的变化,客户端的架构也在不断演进。支持并行研发已经成为大型客户端APP架构最基本的要求。并行研发能极大地提高研发效率,但是也带来了一些管理和维护上的问题。本文主要介绍的是基于并行研发架构的前提下,如何方便快捷的分析出一个组件在ipa中所占的体积并能对APP中所有的组件形成版本统计,快速对比出前后两个版本组件的体积变化。

背景介绍
随着业务的发展,58同城早已实现了并行研发,目前58存在租房、安居客、招聘、二手车、黄页等多个业务线。每个业务线在58 APP中存在一个或多个业务pod。并行研发极大地提高了研发效率,但是也引入了新的问题,众所周知,APP体积是APP重要的性能指标,APP体积对APP的下载和留存有着重要的影响,因此APP瘦身是一个长盛不衰的话题。为了实现APP瘦身,就必须要明确各个业务模块各自的代码和资源体积。基于此背景,58开始探索如何快速便捷地分析出业务模块的体积与增量。

常见技术手段介绍
目前对组件的体积分析常见的技术手段主要有两种:
1. 空项目接入组件
将组件接入到空项目中,编译后对比前后包大小,增量即为业务模块的体积。这种方案比较容易想到,但是58同城对代码拆分粒度较细,单一业务模块很难独立编译运行,并且此方案需要多次进行编译才能获得多个组件集合的各自的体积,效率较低,因此此方案不适用于58同城。
2. linkmap文件分析
linkmap文件分析是目前比较主流的技术手段,其原理为借助应用链接时产生的linkmap文件分析组件体积。linkmap文件格式如图1所示:
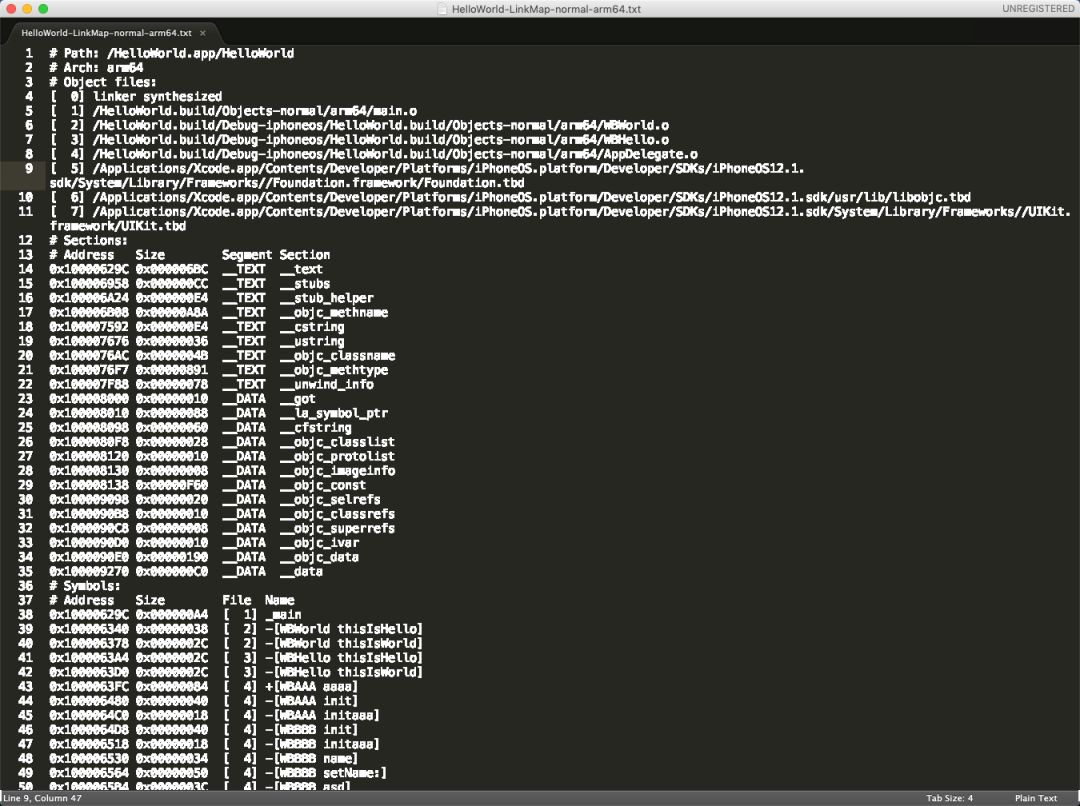
图 1
其主要包括如下信息:
可执行文件路径。
可执行文件架构信息。
目标文件及目标文件编号,其格式为:[文件编号]+目标文件绝对路径。
section 目录,其格式为:起始地址+字节数+段名+节名。
各个section的详细信息,其格式为:地址+字节数+[文件编号]+符号化输出的内容。
基于以上信息分析linkmap文件,即可根据文件编号获取Mach-O文件中__TEXT段和__DATA段的数据来源和大小,从而确定每个组件的代码体积。在获取linkmap文件之后,即可计算出各个节中的体积增量来自哪个目标文件。进而根据目标文件路径可知目标文件所属哪个组件。
这种方案与方案一相比效率有了明显的提升,只需对APP做一次编译即可,避免了多次编译打包。但是这种方案也存在以下不足之处:
扩展性差
58同城采用cocoapods管理了许多组件,这些组件的路径可能非常繁多,并且存在一个组件下有多个静态库的情况。在58同城项目中共有63个组件,并且随着垂直业务平移和中间件的引入,APP的组件会持续变更。由于linkmap文件中所对应的文件信息是目标文件的绝对路径,因此需要维护一个映射表用于确定哪些路径下的文件归属于哪个组件。但是随着组件的变更,这个映射表可能会进行频繁修改。并且在不同的打包机器上,组件绝对路径存在不一致的情况,因此在不同的服务器上打包也需要修改相应的映射表才能分析出组件的体积。
无法统计资源体积
组件除了代码之外还有较多的资源文件。在58同城APP中,代码和资源的比例已经达到了12:5的比例。因此对组件资源的统计也是很有必要的。在linkmap文件中只记录了二进制的链接信息,不包含资源信息,因此只能统计代码体积无法统计资源体积。如果想统计各个组件的资源,则需要额外再遍历组件路径下的所有资源。
链接顺序会影响模块体积
linkmap文件除了上述两个问题外,还有一个不易察觉的问题。链接器在工作时会按一定的顺序进行链接,在链接时,目标文件中的section中的数据如果
在可执行程序中已经存在,则不会再次链接到可执行文件中。这就带来一个问题,如果A组件和B组件各个section中重复内容较多,则linkmap文件只记录先参与链接的组件。基于58现有的架构,各个业务组件依赖大量重复的中间件,因此相同的符号存在较多的重复,并且不同的业务组件彼此之间不依赖,因此编译和链接时基本可以认为组件中的类都是依次连续进行的,这就导致先参与编译链接的组件承担了其他组件的共同部分的体积。

58技术方案思路
58目前采用的是cocoapods管理组件,每个组件都是一个独立的pod。为了能够加快编译速度,我们对每个组件创建了一个静态库pod和源码pod。因此我们期望能利用静态库pod编译后的信息,直接分析出每个pod中静态库体积和资源体积,而不需要再借助宿主工程进行链接获取信息。在获取到链接静态库体积和资源体积后,保存各个pod各个版本的数据,提取任意两个版本的数据后,形成相应的excel表,从而一目了然地看出组件的体积变化。从上述描述可以得知,整个方案的关键步骤在于能否模拟出链接器的工作过程。因此我们需要了解以下两件事情:
静态库是由什么构成?都包含哪些信息?
链接器的工作流程是什么?哪些流程主要影响了应用的体积?
1. 静态库的组成
在介绍静态库组成之前,先简单介绍下Mach-O文件。Mach-O的全称为Mach Object,它是一种特定的文件格式,一般比较常见的文件有:应用程序、目标文件、动态库、bundle等。图2为可执行文件的二进制展示。
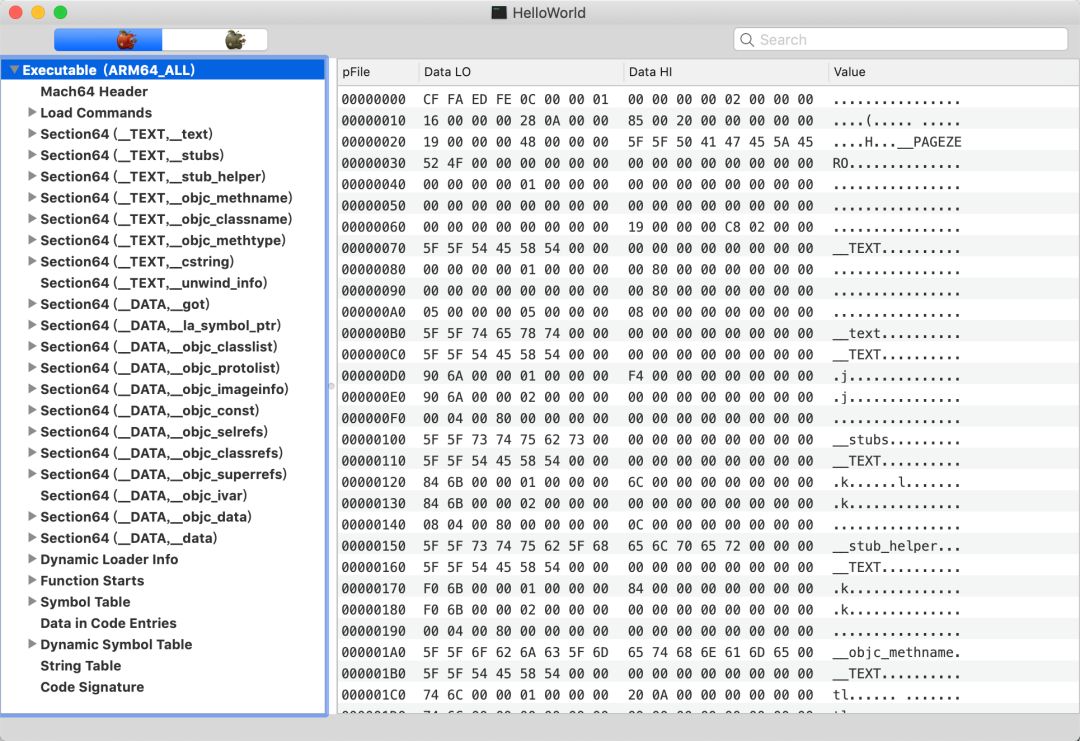
图 2
Mach-O文件主要分为5个部分,分别是:
Header
Load Commands
文本段
数据段
符号表和字符串表
其中,Header是文件的头部信息,包括CPU信息、文件类型、Command条数及Size信息。LoadCommands描述的是文件的加载信息,加载信息有很多,加载的段、符号表、动态库信息等都在LoadCommands中取到。文本段记录的是代码信息,如类名字符串、方法名字符串、汇编指令等。数据段在iOS中大部分字节存储的是类的结构信息以及数据所指向的文本段的地址,少部分字节存储的是静态变量。字符串表记录的是全局的符号字符串,符号表记录的是符号与地址的映射关系。
接下来再介绍下静态库的组成。通过MachOView查看可以得知,静态库与可执行文件一样存在多架构文件。(如图3所示)
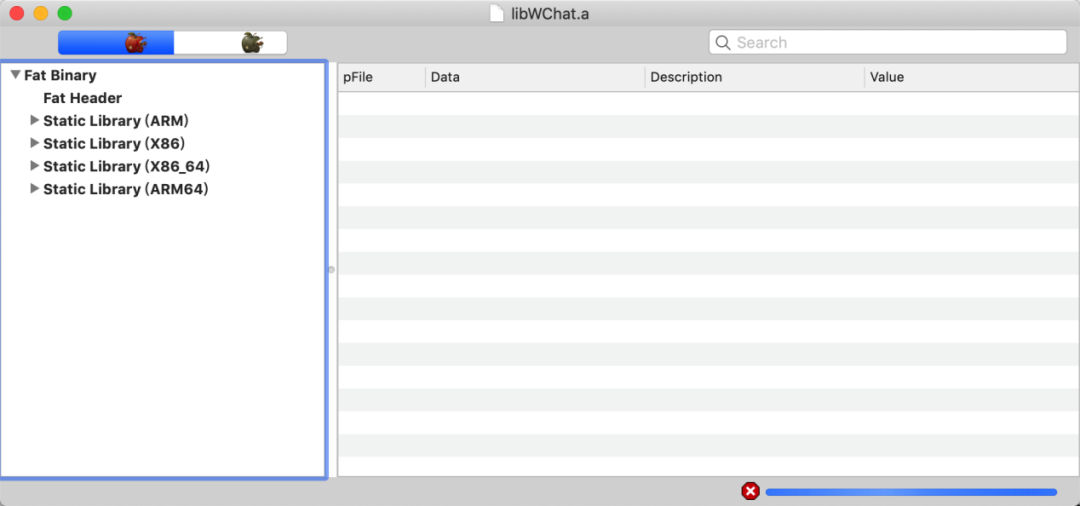
图 3
每个架构由符号表Header、符号表、字符串表和多组目标文件Header+目标文件组成,每个目标文件又是一个单独的Mach-O文件。从表现上来看,一个静态库可能多达几百兆字节的体积,但是最终链接后整个可执行文件的体积也不过几十兆字节,也就是说静态库中很多数据信息在链接时被抛弃了。静态库为什么会在链接前后存在如此大的差距呢?经过调研发现,静态库之所以在参与链接前体积较大链接后体积较小,主要是由于以下几方面原因:
静态库存在多个架构
存在多个架构信息的Mach-O文件即为胖二进制文件,此类文件的每个架构信息都是独立的,多个架构也就意味着体积会成倍数增长。但是在上传到App Store后,用户下载的应用程序中只存在一个架构,其他架构的信息并不会存在于可执行文件中。同理,在真机调试运行时,APP也是以单架构的形态存在的。
目标文件中存在bitcode信息
为了解决架构频繁升级导致的兼容问题,苹果推出了bitcode。bitcode作为编译时期产生的中间码可以被转换成任意一种架构的机器码,在新机型新架构产生时,中间码可以快速产生新的二进制文件以供用户下载。因此bitcode作为中间信息,并不会在用户下载的可执行文件中。开发者可以对bitcode 进行选择性地使用,在58同城中bitcode是关闭状态,因此在最终提交市场的可执行文件中,不存在bitcode信息,因此包含bitcode数据的静态库在链接前会偏大。
目标文件中存在debug信息
Mach-O文件中存在一个__DWARF段。这个段中存放了开发者的debug信息,如文件信息、变量信息等等,__DWARF段主要是调试所用,其数据格式为DWARF格式,在上传App Store时,会连同符号表一同被剥离,不会在执行性文件中。
目标文件中存在符号表
符号表作为符号地址与符号的映射关系,从安全方面考虑,大多数APP在上传App Store时,会将符号表中的本地符号剥离。
以上四方面是造成静态库本身体积远大于真实链接后体积的原因。以微博SDK为例,本地静态库大小为13.3MB。在拆分架构、在剥离bitcode、去除debug信息、剥离符号表后,其大小为793KB。但是这793KB并不是其在链接到可执行文件中的真实体积。在arm64的真机上,微博SDK的真实体积为202KB,与793KB存在不小的差距。造成这种差异的主要原因在于链接器对文件的处理,因此需要了解链接器在连接过程中做了哪些操作,才能准确分析出静态库的体积。
2. 链接器的工作流程
链接器的作用是将编译好的目标文件进行链接,输出可执行文件。其工作流程主要包括:空间地址重分配、符号决议和重定位。其中空间地址重分配是指对参与链接的目标文件的各个段数据进行收集,放入统一文件中。符号决议和重定位是指经过空间地址重分配后,对可执行文件的符号信息进行解析调节,对地址信息进行修正,但是并不会对空间进行修改和调节。因此在链接过程中,对可执行文件的体积有较大影响的是空间地址重分配的过程。
对于多个目标文件,链接器是如何进行空间地址重分配的呢?链接的空间分配策略主要有两种:
按序叠加
相似段合并
按序叠加是指将输入的目标文件按顺序依次叠加,形成统一的文件。这种方案十分简单,但是对空间的浪费比较严重。因为每个目标文件都存在相似的数据和结构。
相似段合并是链接器实际采用的策略,即对相同段的相同数据进行合并,因此在最终的二进制文件中相同的段中的数据量会大大减少。如目标文件a.o和目标文件b.o的(__TEXT,__objc_methname)中都存在helloWorld的方法名,在经过链接器链接后,最终的可执行文件中只存在一个helloWorld。以目标文件Hello.o和目标文件World.o为例,假设两个目标文件中都存在方法名“thisIsHello”和方法名“thisIsWorld”。(如图4和图5所示)
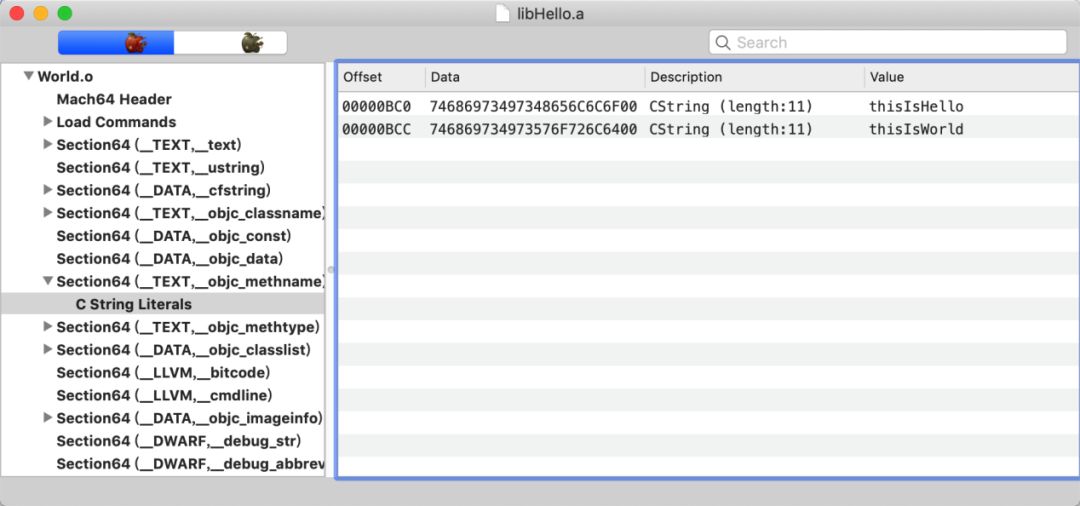
图 4
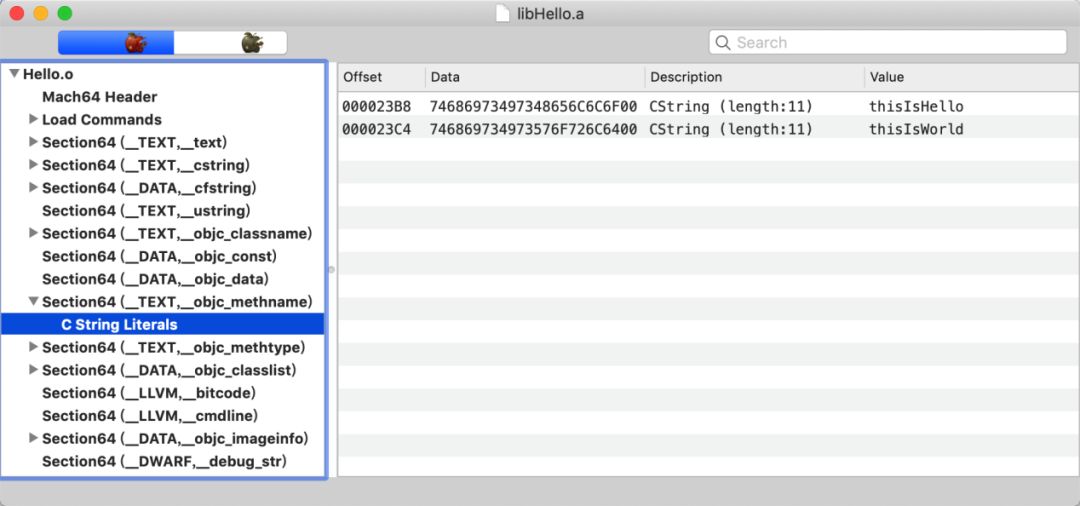
图 5
在最终链接后,可执行文件中只存在一个“thisIsHello”和一个“thisIsWorld”,如图6所示。
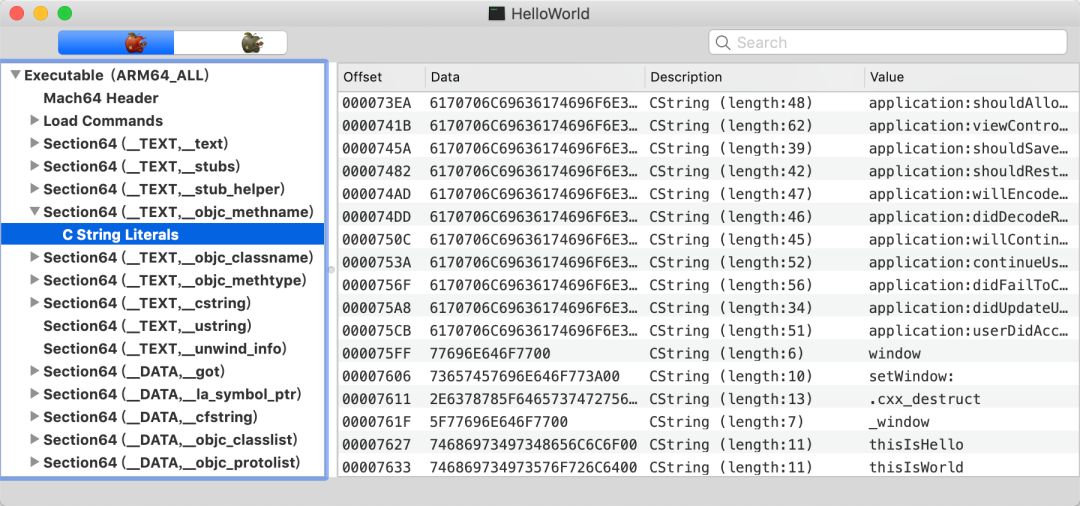
图 6
3. 方案流程
基于上述信息,58的组件体积分析方案可以总结如下:
首先对各个扫描静态库进行架构拆分,提取arm64架构的静态库。
通过lipo -thin 命令可以提取指定架构的二进制文件。提取arm64架构静态库的目的是为了减少工作量。由于arm64 和armv7的文件在数据结构上存在差异,如Command的结构体segment_command和segment_command64,字节数并不一致。
struct segment_command { /* for 32-bit architectures */
uint32_t cmd; /* LC_SEGMENT */
uint32_t cmdsize; /* includes sizeof section structs */
char segname[16]; /* segment name */
uint32_t vmaddr; /* memory address of this segment */
uint32_t vmsize; /* memory size of this segment */
uint32_t fileoff; /* file offset of this segment */
uint32_t filesize; /* amount to map from the file */
vm_prot_t maxprot; /* maximum VM protection */
vm_prot_t initprot; /* initial VM protection */
uint32_t nsects; /* number of sections in segment */
uint32_t flags; /* flags */
};。
struct segment_command_64 { /* for 64-bit architectures */
uint32_t cmd; /* LC_SEGMENT_64 */
uint32_t cmdsize; /* includes sizeof section_64 structs */
char segname[16]; /* segment name */
uint64_t vmaddr; /* memory address of this segment */
uint64_t vmsize; /* memory size of this segment */
uint64_t fileoff; /* file offset of this segment */
uint64_t filesize; /* amount to map from the file */
vm_prot_t maxprot; /* maximum VM protection */
vm_prot_t initprot; /* initial VM protection */
uint32_t nsects; /* number of sections in segment */
uint32_t flags; /* flags */
};因此需要对不同架构的二进制文件进行按不同的字节数解析,这从一定程度上增加了开发成本。目前市场上主流机型都是arm64架构,因此我们可以暂且统计64位架构下的体积即可。
其次扫描arm64架构静态库中的目标文件,按Mach-O格式解析获取文本段和数据段的信息。
其主要过程如流程图图7所示
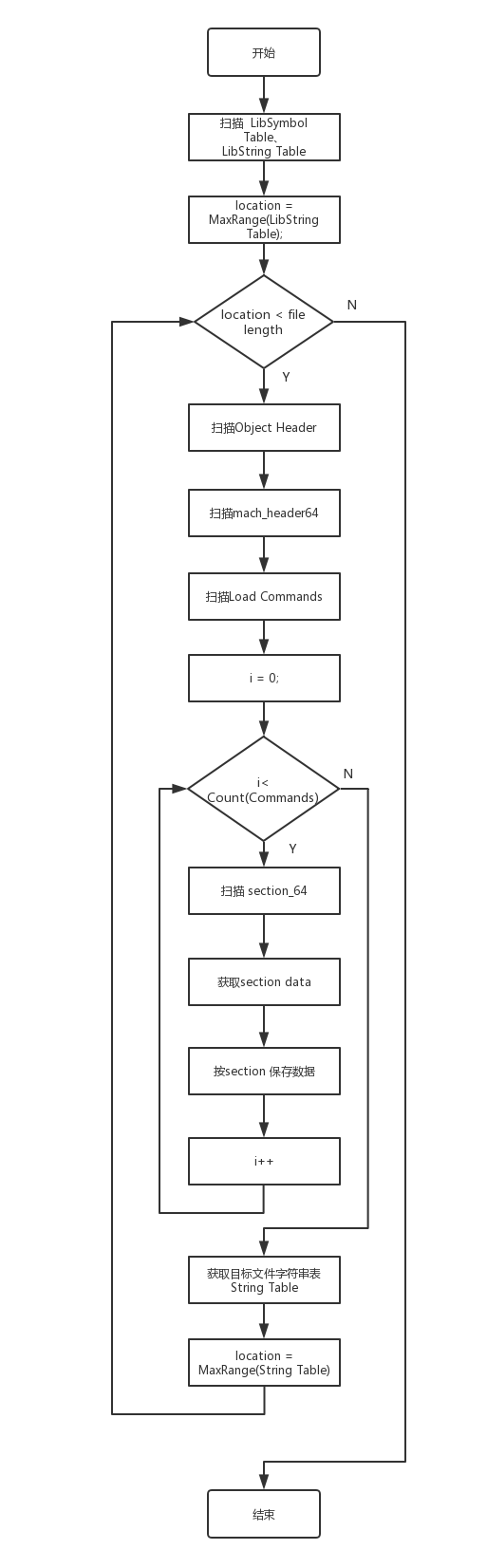
图 7
如何按Mach-O格式解析文件?假设文件读取到内存后为NSData * fileData,则解析Header信息的方式为:
//获取mach-o header
mach_header_64 mhHeader;
tmpRange = NSMakeRange(range.location, sizeof(mach_header_64));
[fileData getBytes:&mhHeader range:tmpRange];在理解Mach-O文件的格式后,即可知道文件的某个数据结构位于二进制文件的范围,因此可以通过将指定范围的二进制文件按指定结构读取数据。
对扫描到的各个段信息按位置合并到一个整体表中。最终得到的整体表的大小即为整个静态库链接后的大小,并保存数据。
Mach-O文件中存在多种数据类型,主要包括:字符串(S_CSTRING_LITERALS)、4字节常量(S_4BYTE_LITERALS)、8字节常量(S_8BYTE_LITERALS)、16字节常量(S_16BYTE_LITERALS)等。按上述步骤解析Mach-O文件,在获取到节的section_64后,根据section_64的flags可以判断出数据类型。
section_64 sectionHeader;
Type = sectionHeader.flags & SECTION_TYPE;再根据数据类型获取数据,并以段+节作为字符串key,保存到目标文件的字典中。
在扫描完所有的目标文件后,对各个目标文件的字典进行合并,保证每个key对应的数组中不存在重复数据。
按版本提取各个pod的组件体积信息,并利用libxl对数据整理输出成Excel文件。
58同城将提取后的数据输出到一个plist中,如图8所示,
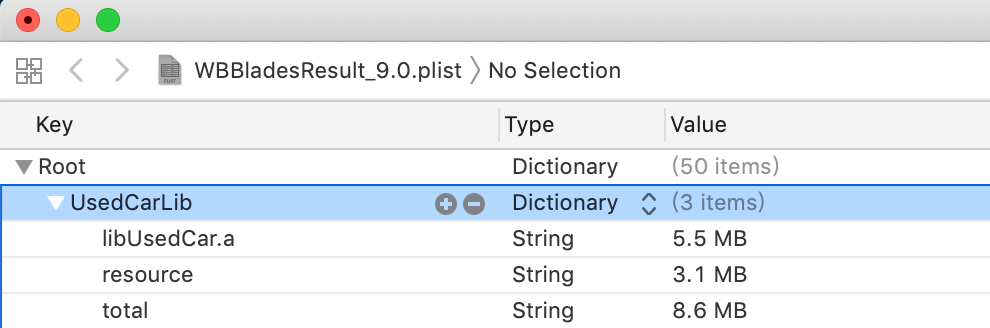
图 8
利用libxl可以将任意两个版本的数据处理成Excel文件。

方案实施过程
基本方案确定后,如何实施才是关键。在方案开始之前,首先要考虑的是工具选型的问题。很多工具既可以通过创建成可视化UI应用,也可以创建成命令行工具,具体采用哪种形态取决于工具使用的场景。考虑到组价体积分析与监控以后可能集成到可持续交付工具中,因此将工具创建成命令行工具可能更好地实现自动化和保持扩展性。对工具期望能做到输入任意文件路径即可将该路径下的分析出资源和代码的体积,并输出plist数据文件。输入任意两个版本的plist文件,即可形成对照表,以Excel文件的形式输出。
在实际开发过程中,主要问题与解决方案如下:
字节对齐问题
静态库以smart、静态库符号表Header、静态库符号表、静态库字符串表、目标文件Header、目标文件的顺序存储数据。当存静态库中存在多个目标文件时,目标文件Header和目标文件会依次向后排列。静态库中目标文件与目标文件之间并不是紧密排布,而是存在8字节对齐问题。当目标文件的字节数不足8的倍数时,会对不足的字节存入数据0补齐字节。但是在静态库符号表却不存在8字节对齐的问题。静态库符号表的大小为4+8*N 字节,按8字节对齐方式的话,静态库字符串表会与静态库符号表的末尾存在4字节的补齐,实际上两者紧密排列,因此在文件扫描时应该注意字节对齐的问题。
目标文件地址偏移问题
静态库作为一个独立文件整体,它的地址是连续的。无论静态库符号表Header、静态库符号表、静态库字符串表、目标文件Header还是目标文件,他们的物理位置偏移都是相对于静态库而言。但是在目标文件作为一个独立的Mach-O文件,它的文件中所记录的文件偏移是相对于目标文件自身的偏移。如目标文件a.o起始位置在静态库的0x1000位置,目标文件a.o中的字符串表偏移为0x2000,那么在扫描a.o中的字符串表时应该从静态库的0x3000开始。
中文字符串提取
在模拟链接器的相似段合并时,需要将各个段的信息都提取翻译出来,否则很难确定是否有重复内容。以字符串为例,字符串表存放的是连续的字符串信息。当两个目标文件的字符串表做合并时,就需要明确每个字符串表中到底存放的是那些字符串,每个字符串的长度是多少。否则单纯的按字节进行数据对比比较难处理。在Mach-O文件中,英文字符串存储在__cstring中,每个字符占1个字节,以0x00结尾。中文字符则每个中文占2个字节,以0x0000结尾,中文字符串存储于__ustring中并没有存储在字符串表或__ctring中。获取到中文的16进制数据后需要按NSUTF16LittleEndianStringEncoding的编码格式获取中文。获取到中文字符串后,数据的合并就比较容易了。
目标文件长度定位
目标文件与下个目标文件的Header经过字节对齐后相邻排布,如果想获取下个目标文件的Header,则必须要明确当前的目标文件范围。在目标文件的Header信息中存放着一个size字段,但是很遗憾,这个字段并不等于目标文件的大小。因此58同城采取了一种间接的方式。经过观察发现,目标文件的字符串表总是位于最后,也就是说目标文件的字符串表经过字节对齐后,后续地址即为下个目标文件Header的地址。
单目标文件与静态库嵌套
在上文中,静态库都是基于多目标文件的条件下分析的。但是在实际情况中,存在整个静态库中只存在一个目标文件的情况。此时,静态库的数据存储顺序由smart->静态库符号表Header->静态库符号表->静态库字符串表->目标文件Header->目标文件的顺序简化为只有一个目标文件。因此需要对此特殊情况进行适配。除此情况外,静态库还存在嵌套的情况,即目标文件的相邻的数据可能不是目标文件的Header,而是一个.a文件。因此需要递归处理每个静态库。
__TEXT与__DATA
__TEXT与__DATA分别存储的不同的数据。代码的文本信息,包括:类名、方法名、字符串、中文字符串、汇编指令等都存在与__TEXT段中。可以说__TEXT更接近与源码信息,因此苹果对应用加了一层保护壳,App Store的应用都对__TEXT做了加密,当应用程序在iOS系统中运行时才会进行解密。通常所说的砸壳即是指对__TEXT进行解密。苹果之所以对__DATA没有做加密是因为__DATA主要存储的是__TEXT中的数据地址以及类的结构信息等,数据段并不会直接存储文本数据。以__DATA中的__objc_selrefs 节为例,__objc_selrefs中存储的是在代码中被使用到的方法名,在Mach-O文件中__objc_selrefs 存储的是位于__TEXT段中__objc_methname节中的字符串地址,而不是直接存储字符串化的方法名。在可执行文件中,经过链接器的符号决议和重定位后,__objc_selrefs存储的都是地址。但是在静态库中,__objc_selrefs存储的都是地址0。包括主要存储类结构信息的__objc_const节中,存储的数据也都是0。因此对__DATA段做相似段合并是相对困难的,因为无法得知到每个地址结构中到底存储的是哪个类。但是这并不会有太大的影响,因为尽管类结构中的数据都是0,但是数量和占据的空间都是正确的,并且在如果存在相同的类结构无法连接成可执行程序,因此可以认为静态库中__DATA段的大小接近链接后的大小。
xcasset文件处理
上文中主要在说明如何对静态库进行扫描和处理,那么资源如何处理呢?对组件的静态库pod进行资源统计有个天然的好处,就是组件的xib、storyboard资源已经被编译成了nib文件,无需再进行编译,nib文件大小即为对应的xib或storyboard文件在ipa包中的大小。xcasset是苹果推出的用于存储图片资源文件,存放于xcasset的图片资源会被编译压缩,并且App Store会根据用户手机的屏幕来决定下发2x图还是3x图。为了保证统计的资源体积接近线上用户真实的资源体积,需要对xcasset文件进行编译,Xcode提供了actool命令可以对xcasset文件按指定机型进行压缩和编译。
路径屏蔽
在pod组件的路径下,很多中间件存在demo、文档以及git信息,因此在遍历pod路径时需要对此类型文件和路径进行屏蔽。否则会对pod组件进行额外的数据统计甚至是重复统计。
按模块统计
在58同城项目中,一些pod组件尽管是彼此独立的,但是从业务上或者从团队划分上属于一个模块,因此在获取到扫描后的数据后,需要按模块对各个pod进行整合展示。以安居客为例,在58同城中,安居客模块占据了6个pod组件,因此需要统计这6个pod的整体数据并展示在Excel中。

数据展示
目前此方案已经成为58同城每个版本进行组件体积分析与统计的重要手段。并且已经经历过3个版本的检测。经过与版本发版时的数据对比,目前整体体积的误差率控制在10%以内,体积增量的误差率在5%以内。通过组件分析和统计,使58对整个项目的代码和资源体积结构有了较为清晰的认识,并且能够快速帮助58评估业务接入和SDK接入的体积成本。图9为58同城8.24版本与8.25版本的数据对比图。
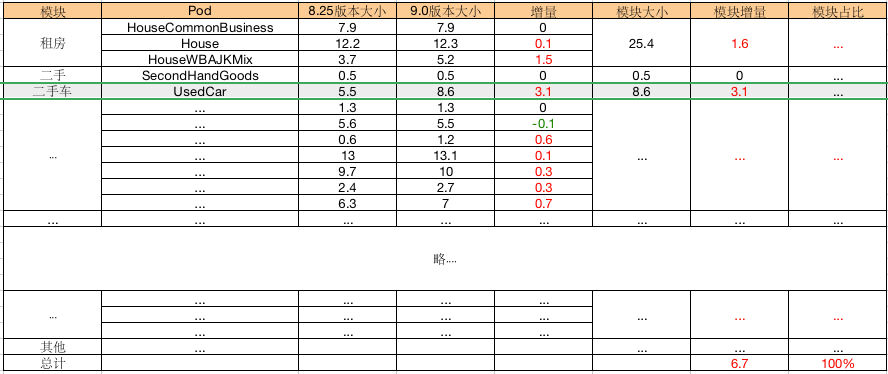
图 9

总结
此方案为多团队并行研发性能指标的建立提供了基础,并为APP的瘦身从数据上提供了方向。其优势主要体现在以下几点:
使用方便,在控制台中拖入路径即可分析出该路径下的静态库体积、资源体积以及总体积,无需编译可执行文件。
维护成本低,引入垂直业务或者中间件无需修改代码或者配置文件。
能够接近正式包的处理方式预先处理资源文件,使资源体积的统计更加准确。
对不同模块的静态库进行独立模拟链接,屏蔽了业务模块之间由于参与链接时间不同导致的偏差。
易扩展、易推广,可持续交付系统可以很容易接入体积分析工具。
参考文献:
1.趣探 Mach-O:加载过程,https://www.jianshu.com/p/8498cec10a41
2.《程序员的自我修养》
3.OS X ABI Mach-O File Format Reference,https://developer.apple.com/library/mac/documentation/DeveloperTools/Conceptual/MachORuntime/index.html
4. libxl使用文档,http://www.libxl.com/documentation.html
5. 链接器和装入器的基本工作原理,https://blog.csdn.net/xiaofei0859/article/details/50563572
作者:邓竹立,58 同城用户价值增长部-iOS 技术部高级研发工程师。专注于客户端架构与性能优化,目前主要负责 58 同城 iOS 客户端微聊中间件的研发及 APP 工厂提效工具研发。
【End】

热 文 推 荐
☞支付宝回应 AI 换脸风险;新 iPhone 或将于 13 号接受预订;Linux Lite 4.6 发布 | 极客头条
☞Dropout、梯度消失/爆炸、Adam优化算法,神经网络优化算法看这一篇就够了
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











