










arxiv Jan,17,2024
【核心思想】
核心思想是提高MRI脑肿瘤分级的准确性。该研究提出了一种结合多模态学习、跨模态引导模块和双重注意力机制的新方法。这种方法有效利用不同MRI模态的互补信息,平衡模型效率和效果。双重注意力机制关注空间和切片维度,捕捉相关的语义关联。在BraTS2018和BraTS2019数据集上,该方法展现出优越性能,超越了单模态方法和多种最新的多模态方法,实现了高准确性和鲁棒性的脑肿瘤分级。
主要贡献如下:
- 通过初步实验,作者发现不同模态编码的诊断信息差异很大,通用的模态融合策略不够鲁棒,甚至可能导致性能大幅下降。
- 提出了一种新型的多模态框架,采用轻量级的ResNet Mix Convolution架构,旨在解决MRI脑肿瘤分级问题,实现了模型效率和效果之间的良好平衡。
- 设计了一种跨模态引导辅助模块,能够有效地利用多种模态进行训练,其中主要模态的主要贡献可以在很大程度上得到保留和利用
【方法】
-
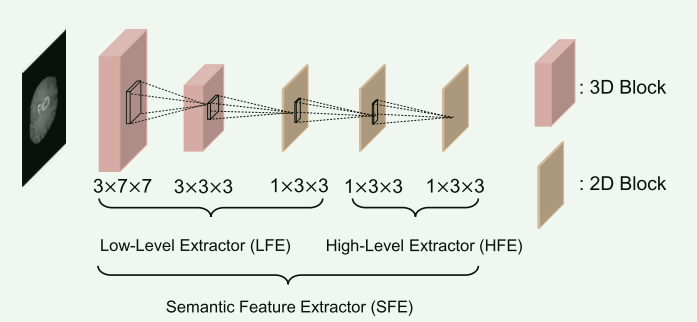
A. ResNet混合卷积(ResNet Mixed Convolution, RMC)
-
目的:使用RMC来学习特定的空间和时间关系,同时降低计算成本。
-
特点:RMC结合了2D和3D卷积,包括一个包含3D卷积层的主体,一个3D卷积块和三个2D卷积块。这种结构显示出比纯3D ResNet和其他时空模型(如ResNet (2+1)D)更优越的性能。
-
应用:RMC作为基线方法,并被采用为特征提取的主要网络框架。
-
-
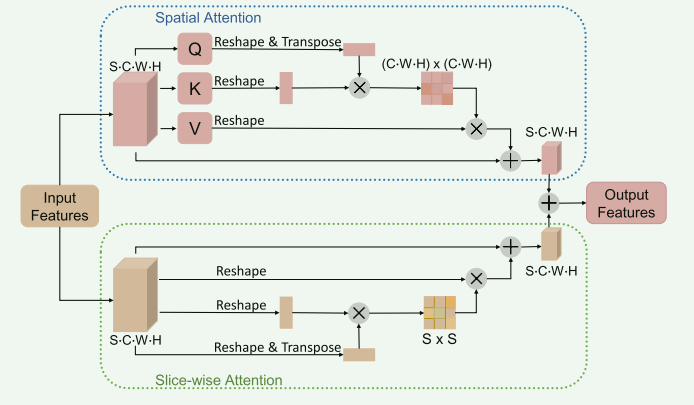
B. 双重注意力(Dual Attention)
-
原理:基于自注意力机制开发的双重注意力技术,用于同时计算通道和位置维度上的注意力。
-
重要性:在MRI脑肿瘤分级任务中,考虑到肿瘤位置和大小两个影响因素,双重注意力可以为模型提供特定位置和切片维度的注意力图。
-
作用:双重注意力被插入到特征提取模块中,用于放大或抑制MRI体积中的不同区域,从而使模型更强大和稳健。
-
-
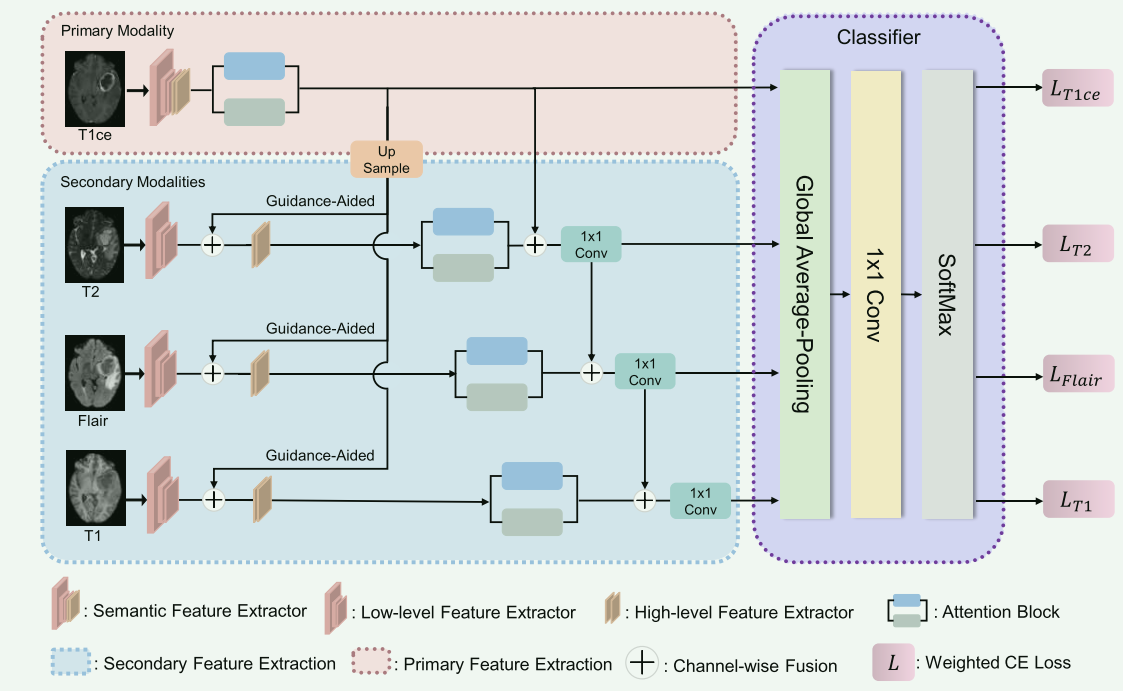
C. 引导辅助特征提取模块(Guidance-aided Feature Extraction Module)
-
设计理念:该模块旨在利用更多模态的互补信息来提高脑肿瘤分级的性能。根据单模态模型的表现,将模态分为主要模态和次要模态。
-
操作过程:
- 主要模态特征提取:利用语义特征提取器(Semantic Feature Extractor, SFE)生成主要模态图像的特征图,随后通过双重注意力操作生成高级别特征表示。
- 次要模态特征提取:首先使用低级别特征提取器(Low-level Feature Extractor, LFE)提取次要模态的低级别特征,然后将主要模态的高级别特征与次要模态的低级别特征进行通道融合。融合的特征随后通过高级别特征提取器(High-level Feature Extractor, HFE)生成次要模态的特征图。
-
特点:利用主要模态的高级别特征和次要模态的低级别特征之间的引导,来强调更具信息性的特征,同时抑制较少信息的特征。这种方法允许模型更有效地利用多模态的互补信息。
-
【数据集】
BraTS2018 and BraTS2019
【实验效果】
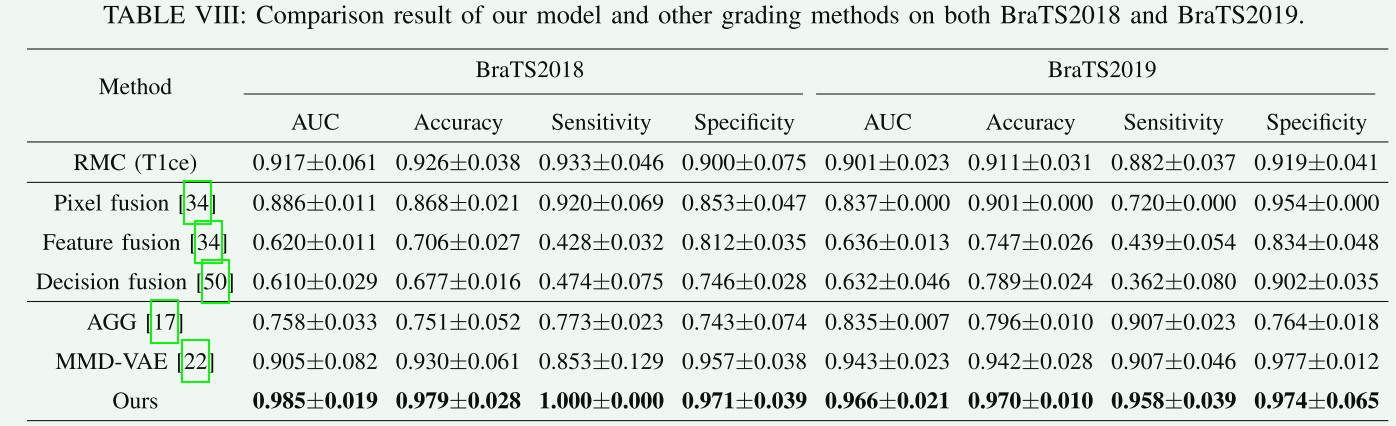
将其提出的方法与三种基本的多模态融合方法以及两种现有的MRI多模态分类方法进行了比较。
- 基本多模态融合方法:这些方法使用预训练的RMC模型作为主干模型,并包括:
- 像素融合:将四种模态堆叠在通道维度作为单一输入。
- 特征融合:分别将四种模态输入特征提取器,然后将相应的特征串联并分类。
- 决策融合:单独对每种模态进行分类,然后将相应的概率串联,通过三层多层感知器得出最终预测。
- 现有的多模态MRI分类方法:
- 自动胶质瘤分级(AGG):使用类似UNet的网络进行肿瘤分割,然后基于分割结果从MRI图像中裁剪肿瘤区域,最后构建3D CNN网络进行分类。
- 多模态解离变分自编码器(MMD-VAE):从提供分割地面真值的MRI图像中提取放射组学特征,解离VAE以获得模态间的相似和互补信息进行预测。
- 结果和讨论:
- 三种基本多模态融合方法未能达到令人满意的结果,所有的AUC均低于0.9。
- 相比于基线模型,像素融合、特征融合和决策融合导致性能显著下降,甚至比单模态模型的集成效果还差。
- AGG模型在BraTS2018数据集上的性能大幅下降,而MMD-VAE模型虽然在BraTS2019数据集上比基线模型有所改善,但在BraTS2018数据集上未能提高性能。
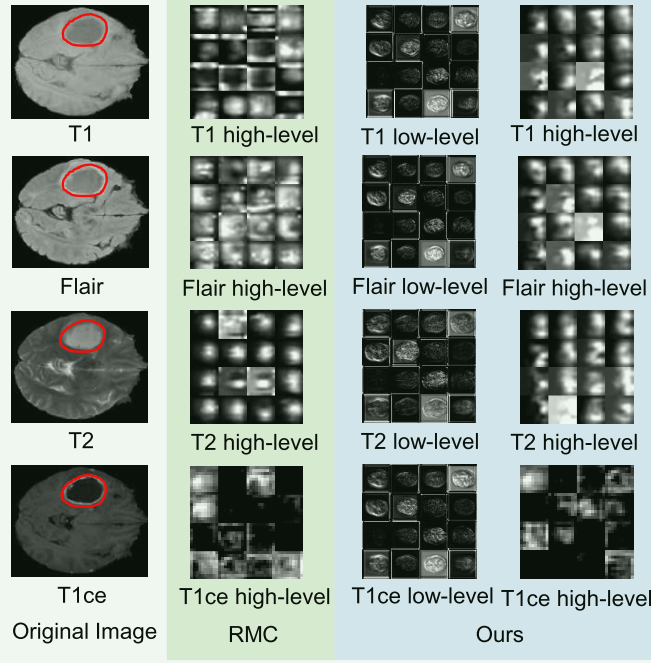
- 本研究提出的引导辅助多模态框架在两个数据集上的所有评估指标中均取得了最高分数,显著优于比较方法,证明了其框架在脑肿瘤分级方面的鲁棒性和效率。
- 不同于AGG和MMD-VAE,本研究方法可以直接利用整个MRI图像进行训练和预测,而无需复杂的数据预处理步骤来获取肿瘤注释。
【方法局限性】
论文中提到的:
- 该框架需要两阶段的训练过程,可能在重新实现时比较复杂。
- 尽管采用了轻量级的主干网络以降低计算成本,但模型的大小仍然很大,训练和推理过程可能效率不高。
- 本研究的方法是在BraTS2018和BraTS2019数据集上开发和测试的,样本数量可能不足以支持一个鲁棒的模型。
- 真实世界的数据可能包含更多的环境噪声,并表现出较大的领域偏移。如何利用先进的领域适应技术来消除领域偏移问题,使模型对噪声更加鲁棒也是未来的方向。
论文中未提:
论文的主模态和次要模态是人为指定的,不够灵活















 1102
1102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









