









 本文介绍了一种新颖的跨模态图神经网络(CMGNN),利用NLP的语义信息引导视觉特征学习,通过构建元节点和设计距离损失函数来实现全局嵌入的一致性和稳定性。实验结果显示,CMGNN在少样本学习中优于众多SOTA方法。
本文介绍了一种新颖的跨模态图神经网络(CMGNN),利用NLP的语义信息引导视觉特征学习,通过构建元节点和设计距离损失函数来实现全局嵌入的一致性和稳定性。实验结果显示,CMGNN在少样本学习中优于众多SOTA方法。
Abstract
尝试仅使用少数标记样本来预测未标记样本的少样本学习已引起越来越多的关注。尽管最近的工作取得了可喜的进展,但他们都没有注意到在剧集之间建立一致性,从而导致潜在嵌入空间的模糊性。在本文中,我们提出了一种新颖的跨模态图神经网络(CMGNN)来揭示情节之间的关联,以实现一致的全局嵌入。由于 NLP 引入的语义信息与视觉信息空间相比是相对固定的,因此我们利用它为每个类别构建元节点,以通过 GNN 指导相应的视觉特征学习。此外,为了确保全局嵌入,设计了距离损失函数以更大程度地迫使视觉节点更靠近其关联的元节点。对四个基准数据集的广泛实验和消融研究表明,它优于许多 SOTA 比较方法。
Introduction
为了连接全局嵌入的情节,我们提出了跨模态图神经网络 (CMGNN),它利用来自自然语言处理 (NLP) 的语义信息来指导每个类别的映射。它包含三个模块:(1)图像嵌入模块(IEM),(2)语义元知识模块(SMKM),和(3)图传播模块(GPM)。 IEM 的目的是获取真实和合成的视觉嵌入。然后,对于特定类别,SMKM 模块利用语义信息来构建元节点,这些元节点的作用类似于锚点来指导相应的视觉特征映射。最后,GPM 可以在图网络优化过程中将信息从元节点传播到普通可视节点。
虽然视觉信息空间的方差太大阻碍了全局表示的一致性,但 SMKM 利用每个类别的空间相对固定的语义信息来建立情节之间的联系。具体来说,我们首先建立元知识,它实际上是一个矩阵,每一行代表一个知识向量。然后,对于特定类别,我们通过情节对其共享语义信息采用注意方案来计算注意系数,该系数用于组合相关元节点的元知识矩阵。通过这样做,生成的元节点可以被视为构建一致的全局嵌入的锚。
SMKM 生成的元节点可以引导来自 IEM 的可视节点通过图更新在 GPM 中形成全局嵌入。而对于少样本学习,标记数据(视觉节点)太稀少,无法跨越足够平滑的流形全局嵌入空间,从而阻碍了它的泛化。因此,我们利用流形混合[4]来合成一些新的视觉嵌入,作为真实特征嵌入之间的转换来填充嵌入空间。此外,由于元节点通过图更新对视觉节点的隐含影响不够稳定,我们设计了一种新的损失函数来强制视觉节点聚类到相应的元节点。
Contributions
- 据我们所知,CMGNN 是第一个具有跨模态信息的图神经网络,用于获取全局嵌入以进行小样本学习。
- 为确保全局嵌入平滑和稳定,我们利用流形混合来填充原始空白嵌入空间,并设计显式距离损失以迫使视觉节点更靠近相应的锚节点,以获得更好的全局嵌入。
- 每个先进的 GNN 方法,例如 EGNN和 DPGN都可以灵活地集成到我们的框架中。广泛的实验结果表明,我们的方法优于许多最先进的方法。
Method
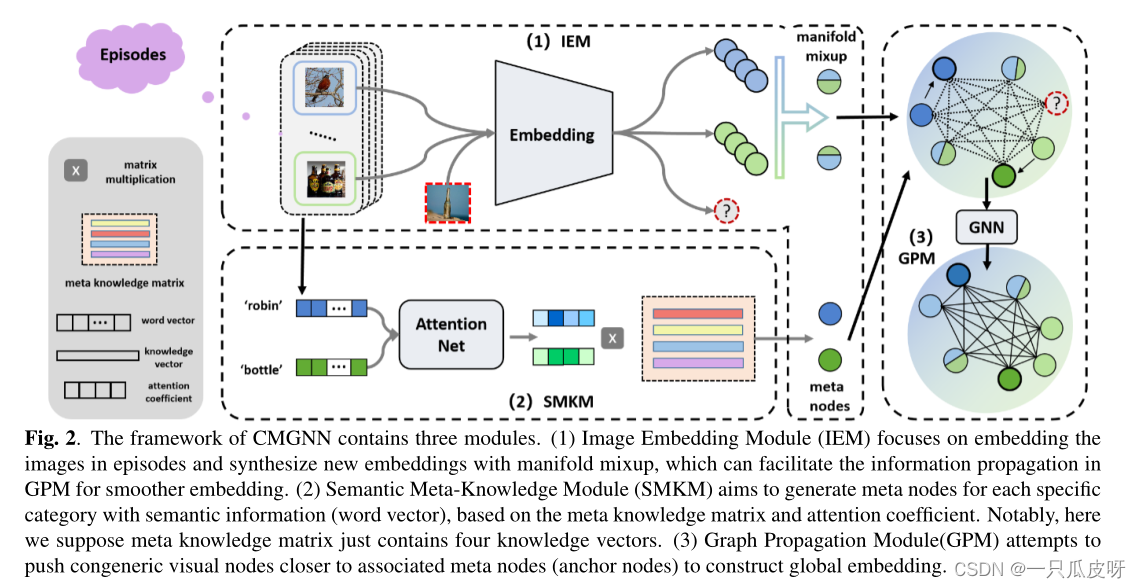
首先,在 IEM 中,我们提取真实图像的特征嵌入 𝑉𝑟𝑣,并通过流形混合合成新的特征嵌入 𝑉𝑠𝑣,统称为视觉节点 𝑉𝑣。
然后,在 SMKM 中,我们利用标签中的词向量作为语义信息来生成具有可学习元知识矩阵的注意机制的特殊元节点 𝑉𝑚。
最后,在 GPM 中,𝑉𝑚 和 𝑉𝑣 将被用来构造一个全连接图,引导视觉节点形成平滑的全局嵌入。
同时,采用与流形混合相关的特殊边初始化来促进图中的信息传播。
此外,除了分类损失函数 Lcla 之外,还设计了一种新颖的距离约束损失函数 Ldis,以确保视觉节点更接近相应的元节点(锚节点)。
图像嵌入模块
输入为真实图像xi的IEM将提取相关特征zi如下:
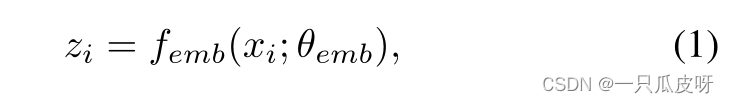
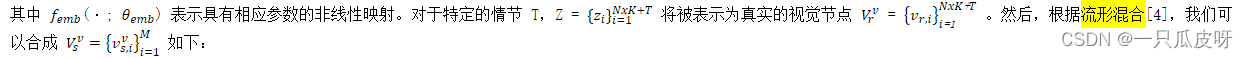
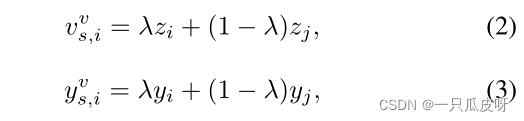
其中 M 表示合成新节点的数量,λ 服从均匀分布,即 λ ∼ U(0, 1)。所以所有的视觉节点都可以表示为 𝑉𝑣。通过这样做,合成节点可以作为真实节点之间的转换,使图密集,促进其中的信息聚合以获得更好的细化节点,其有效性将在消融研究中得到证明。
语义元知识模块
![]()
![]()
![]()
![]()
图传播模块
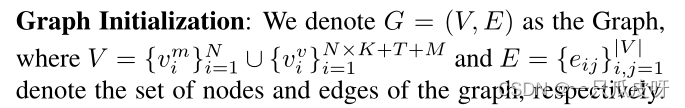
然后,初始边 e0,ij 设置如下:
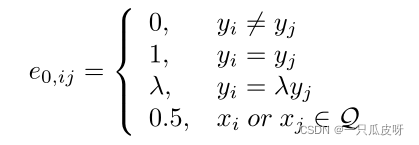
其中 i, j ≤ N × K + T + M, λ 与流形混合中的一致,Q 表示查询集。请注意,e0,ij 的值将在 [0, 1] 范围内缩放,其中 e0,ij = 0 表示 (v0,i, v0,j) 之间没有相似性,反之亦然。
因为我们提出的 CMGNN 是一个少样本学习的框架,任何先进的 GNN 方法都可以在这里轻松使用,例如 EGNN [3] 和 DPGN [5]。通过流形混合分割合成的节点作为真实节点之间的转换,将改善图中的信息传播,导致相似的节点被拉近而不同的节点通过更新被推开。同时,同类视觉节点将隐式地聚集到相应的元节点上进行全局嵌入。
损失函数和优化器
我们可以在对图进行所有更新后获得最终图,然后查询样本的预测计算如下:
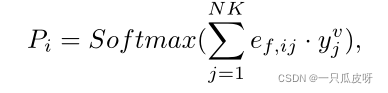
为了优化 CMGNN 中的所有参数,我们提出如下分类损失函数:
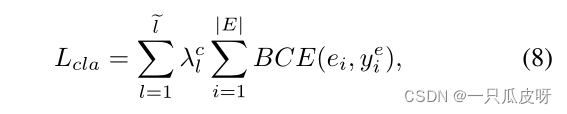
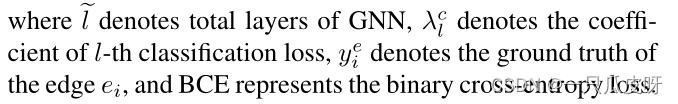
此外,为了便于全局嵌入,我们设计了一个距离损失函数来显式地强制同类视觉节点 Vv 聚集到它们相应的元节点 Vm,其定义如下:
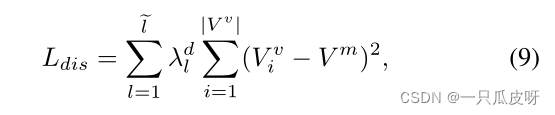

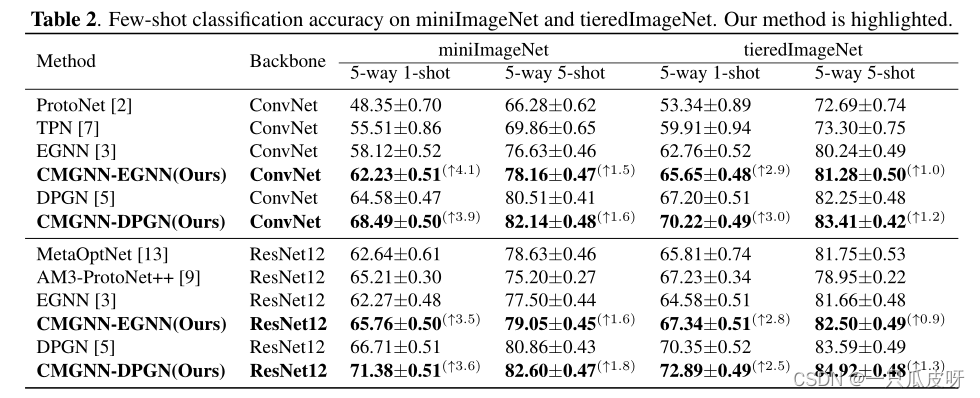
Experiment


















 687
687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









