






Overview
This guide explains the performance counters found in the Arm Streamline tool's profiling template for the Mali-G76 GPU. This GPU is part of the Mali Bifrost architecture family. Note that the Streamline template only shows a subset of the available performance counters. However, it covers the most common types of GPU workload performance analysis.
The counter template in Streamline follow a step-by-step analysis workflow, starting with a coarse analysis of the overall GPU workload, before moving on to a more detailed analysis of the rendering content the application is passing to the GPU, and how the GPU shader cores process that workload.
This guide contains the following sections:
- CPU performance: look at how to analyze the overall usage of the CPU by observing the activity on the CPU clusters and cores in the system, and how that workload is split across threads.
- GPU activity: look at how to analyze the overall usage of the GPU by observing the activity on the GPU processing queues, and the workload split between non-fragment and fragment processing.
- Content behavior: look at how to analyze content efficiency by observing the number of vertices being processed, the number of primitives being culled, and the number of pixels being processed.
- Shader core data paths: look at Mali shader core workload, throughput, and data path utilization.
- Shader core unit overview: look at the macro-scale usage of the shader core by observing the effectiveness of depth and stencil testing, the number of threads spawned for shading, and relative loading of the programmable core processing pipelines.
- Shader core varying unit: look at performance of the varying unit, and how the unit is being used by the shader programs that are running. This can be used to find optimization opportunities for varying-bound content that has been identified in the Shader core section.
- Shader core texture unit: look at performance of the texture filtering unit, and how the unit is being used by the shader programs that are running. This can be used to find optimization opportunities for texture-bound content that has been identified in the Shader core section.
- Shader core load/store unit: look at performance of the load/store unit, and how the unit is being used by the shader programs that are running. This can be used to find optimization opportunities for texture-bound content that has been identified in the Shader core section.
- Shader core memory access: look at the memory traffic between the shader core and the L2 cache and external memory system, broken down by unit. This can be used to identify which type of workload is causing memory traffic, helping to narrow down where optimizations should be targeted.
GPU性能指标详解
2.1 Mali GPU Utilization
l 性能指标含义
Mali GPU Utilization包含Non Fragment Utilization和Fragment Utilization两个性能指标。Non Fragment Utilization指非片段处理耗时占整体GPU处理耗时百分比,Fragment Utilization指片段处理耗时占整体GPU处理耗时百分比。
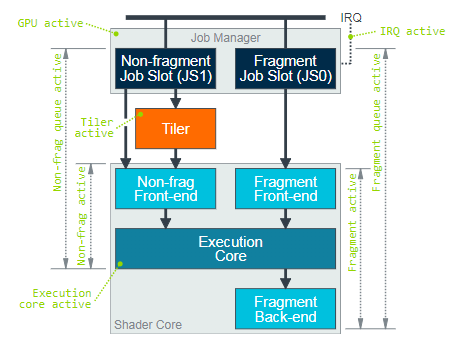
上图显示了通过GPU处理不同类型工作负载的基本处理管道数据路径,以及各个层次结构中每个处理模块的性能指标。在Mali GPU上运行的工作负载由作业管理器统一协调,该任务管理器负责将工作负载调度到GPU内部的各个处理单元上,它将两个FIFO工作队列(称为作业插槽)公开给图形驱动程序。一个插槽用于非片段工作负载,其中包括vertex shading, tiling,geometry shading, tessellation shading, and compute shading,还有一个插槽用于片段着色工作负载,主要包括光栅化、EarlyZ、FPK、Fragment shading、Blender、Tile write等。

l 性能指标意义
用于定位GPU瓶颈是在非片段处理阶段还是片段处理阶段,可用于指导程序优化方向。当出现GPU瓶颈时,正常情况下Non Fragment Utilization和Fragment Utilization至少有一个是接近100%,如果两者都低于100%,则有可能是Non Fragment和Fragment之间存在数据依赖关系。
Non Fragment Utilization过高原因及优化建议:
Ø 顶点数量过多
² 是否有大量不可见顶点,优化建议:遮挡剔除、视锥裁剪、背面裁剪。
² 可见顶点数量多,优化建议:使用Lod简化模型,使用距离裁剪。
Ø 顶点属性数据量大,优化建议:使用中精度属性、删除无用属性。
Ø 顶点Shader过于复杂,优化建议:顶点Shader中避免采样纹理,尽量使用低精度变量进行计算。
Ø 使用了复杂的compute shader或者geometry shader、tessellation shader
Fragment Utilization过高原因及优化建议:
Ø 片段数目过多
² 使用Mask材质导致EarlyZ和FKP机制失效,优化建议:提前渲染Mask mesh深度或者降低Mask mesh面数,检查是否可以禁用Mask。
² 粒子等半透明像素过多,优化建议:减少粒子数量,控制粒子大小。
Ø 片段Shader过于复杂
² ALU逻辑计算耗时高,优化建议:避免动态分支,避免使用高耗时函数、把复杂的计算转移到VS阶段。
² 纹理采样耗时高,优化建议:减少纹理采样次数、使用压缩格式纹理、避免使用各项异性过滤方式。
² Load/Store耗时高,优化建议:使用中精度变量,尽量避免使用高精度计算。
2.2 PixelThrought
l 性能指标含义
指平均每个已着色Pixel所耗费的GPU Cycle,包括Non Fragment处理Cycle和Fragment处理Cycle。假设GPU最高频率为800Mhz,GPU使用率100%,游戏运行分辨率为1080*2340,FPS为60。
每秒Shaded Pixel (不考虑OverDraw)= 1080 * 2340 * 60 = 151.6M
PixelThrought = 800M / 151.6 = 5.27 Cycle
说明在这种情况下平均渲染每个Pixel 花费5.27个Cycle。
l 性能指标意义
由于该指标衡量的是平均每个已着色Pixel所耗费的GPU Cycle,所以通常情况下该指标和Vertex Shader或Fragment Shader复杂度有关,可以根据Non Fragment Utilization和Fragment Utilization这两个指标来判定哪部分瓶颈。如果是Fragment处理瓶颈,说明当前场景下Fragment Shader较为复杂,导致处理单个Pixel所耗费Cycle较高。
l 性能指标测试验证
测试用例:保持顶点数和Fragment数量不变,使用循环语句和次数控制VS和FS计算量,验证对PixelThroughput的影响。
测试机型:Oppo R15(GPU型号:Mali G72 MP3)
测试数据:
| VS LoopNum | FS LoopNum | PixelThroughput(cycles) |
| 0 | 0 | 0.1 |
| 100 | 0 | 1.7 |
| 0 | 100 | 3.8 |
| 100 | 100 | 4.3 |
测试结论:Shader中循环次数越多,计算量越大,PixelThroughput越高。
2.3 Mali OverDraw
l 性能指标含义
Overdraw就是在一帧当中,同一个像素被重复绘制的次数。PerfDog中OverDraw是每秒的平均OverDraw,即
OverDraw = 每秒Shaded Fragments / 每秒Screen Pixels
假设游戏运行FPS为60, 游戏运行分辨率为1080*2340,每秒Shaded Fragments 数量为273M。OverDraw = 273*1000000 / (1080*2340*60) = 1.8
从以上公式上可以看出在固定分辨率和帧率下,OverDraw越高则说明每帧处理的Fragments数量越大,负载越高,当负载超过GPU最大处理能力后就会引起掉帧。
l 性能指标意义
当我们分析GPU性能时,首先需要定位性能瓶颈。如果某段时间Fragment Utilization突然升高,原因可能是以下两个方面:
1、Fragment数量增大,对应Overdraw性能指标升高,优化方向是降低OverDraw。
2、Fragment平均处理耗时增大,对应PixelThrought性能指标升高,优化方向是降低材质Shader复杂度。
Overdraw过高原因及优化建议:
在游戏中,Overdraw过高主要是由AlphaTest和AlphaBlend物件渲染导致,Opaque物件由于GPU中的EarlyZ、FPK机制会自动进行排序并剔除被遮挡片段,所以Opaque物件对于OverDraw影响较小。
AlphaTest物件Overdraw影响:AlphaTest物件的深度写入需要在执行FragmenShader之后才能确定是否写入深度,延迟的深度写入会影响TBDR架构下的HSR效率,因为后续图元需要等到AlphaTest图元执行完FragmenShader并更新深度缓冲区后才能继续处理。
Ø AlphaTest物件Overdraw优化建议
² 从前往后排序渲染。
² 美术制作时减小AlphaTest三角形图元面积。

AlphaBlend物件Overdraw影响:AlphaBlend物件可以被Opaque物件EarlyZ剔除,但是因为不会写深度,所以AlphaBlend三角形彼此不能EarlyZ剔除,叠加时产生OverDraw。游戏中的半透明粒子特效、UI等容易产生OverDraw问题。

Ø AlphaBlend物件Overdraw优化建议
² 降低半透明混合叠加层数,例如半透明粒子特效根据机型调整粒子数量。
² 尽量缩减半透明图元屏幕渲染面积,例如渲染粒子特效或UI时使用不规则面片代替矩形面片进行渲染。
l 性能指标测试验证
Ø 测试用例1:验证AlphaBlend物件叠加渲染对OverDraw影响
从摄像机开始由近到远绘制全屏四边形,用滑块控制靠近摄像机的N层(共20层,0<N<=20)为半透明全屏四边形,后面(20-N)层为不透明全屏四边形,验证Fragments/pixel的值是否符合OverDraw的定义。
测试机型:Oppo R15(GPU型号:Mali G72 MP3)
测试数据:
| 不透明层数 | 半透明层数 | OverDraw |
| 20 | 0 | 1 |
| 19 | 1 | 2 |
| 10 | 10 | 10.9 |
| 20 | 20 | 19.8 |
测试结论:不透明三角形由于GPU 有EarlyZ和FKP机制,把被遮挡的不透明三角形给剔除掉了,所以被遮挡的不透明三角形不会增加OverDraw。而最上层的半透明三角形由于不会写深度,所以上层的不透明三角形并不会遮挡掉下层的不透明三角形,会增加OverDraw,OverDraw和不透明三角形层数正比。
Ø 测试用例2:验证AlphaTest物件渲染排序方式对OverDraw影响
在场景中摆放50个2D公告板草,然后调整草的渲染排序方式,测试OverDraw。
测试机型:Oppo R15(GPU型号:Mali G72 MP3)
测试数据:
| 渲染排序方式 | 从前往后绘制 | 从后往前绘制 | 随机顺序绘制 |
| OverDraw | 24.6 | 32.3 | 26.9 |
测试结论:AlphaTest从前往后绘制由于能够充分利用GPU EarlyZ机制剔除被遮挡Fragment,所以能够有效降低OverDraw。
2.4 BusRead/ BusWrite
l 性能指标含义
BusRead/ BusWrite分别表示GPU每秒通过系统总线从外部共享内存中读取和写入的字节数。GPU读写外部DDR内存非常的耗电,通常来说每GB / s带宽功耗为100mW。另外读写外部内存相对于GPU内部Cache来说,延迟会更大。
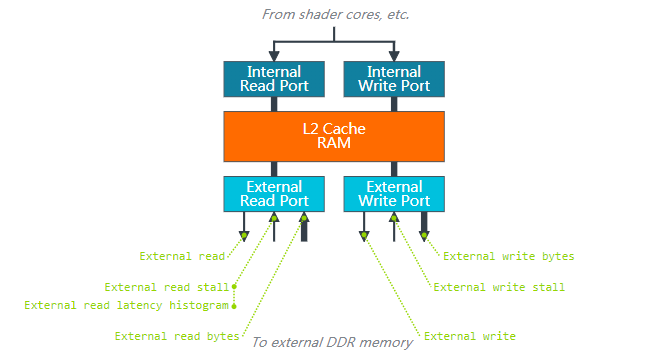
BusRead带宽主要来自于GPU的Load/Store Unit、Texture Unit和 Tile Unit三个处理单元,包括顶点输入属性数据、Uniform数据、TileList数据、纹理数据、颜色/深度数据的读取,BusRead大小取决于GPU这几个单元每秒的数据读取量以及L1、L2缓存的命中率。在总数据量不变的情况下,缓存命中率越高,BusRead越小。
BusWrite带宽主要来自于GPU的Load/Store Unit和 Tile Unit两个处理单元,包括顶点输出属性数据、TileList数据、颜色/深度数据的存储。
l 性能指标意义
BusRead带宽过高原因及优化建议:
Ø 顶点属性带宽
² 减少顶点数量:使用遮挡剔除、视锥剔除、距离剔除、Lod。
² 顶点Position属性使用单独的缓冲区,其他属性使用一个缓冲区。
² 移除在Vertex Shader中不参与计算的顶点输入属性数据。
² 尽量使用中精度属性。
Ø 纹理带宽
² 使用ETC2、ASTC等压缩格式。
² 使用MipMap,可以增加Cache命中率,降低带宽。
² 避免使用各项异性过滤方式。
² 相邻像素纹理坐标尽量连续,防止跳变,影响Cache命中率。
Ø 颜色/深度缓冲区带宽
² 渲染阴影时Framebuffer只绑定深度缓冲区,禁用颜色缓冲区。
² 后处理RT只绑定颜色缓冲区,禁用深度缓冲区。
² 每帧开始时调用glClear函数清除颜色、深度、模板缓冲区,防止重新Load上一帧Framebuffer数据。
² 避免调用glReadPixels等函数从Framebuffer中获取像素。
BusWrite带宽过高原因及优化建议:
Ø 顶点输出属性带宽
² 减少顶点数量:使用遮挡剔除、视锥剔除、距离剔除、Lod。
² 尽量使用中精度输出属性。
Ø Tile List带宽
² 降低三角形数量,特别是微小三角形,可根据ScreenSize剔除。
² 检查是否开启背面裁剪。
Ø 颜色/深度缓冲区带宽
² 渲染阴影时Framebuffer只绑定深度缓冲区,禁用颜色缓冲区。
² 后处理RT只绑定颜色缓冲区,禁用深度缓冲区。
² 对于每一个framebuffer,一帧中只绑定一次,并且在解绑或使用framebuffer object的结果之前,要确保所有影响它的渲染指令提交完毕。
l 性能指标测试验证
Ø 测试用例1:验证FrameBuffer颜色缓冲区格式对内存带宽的影响
渲染一个全屏四边形,仅修改颜色缓冲区格式,验证对内存带宽影响。
测试机型:Oppo R15(GPU型号:Mali G72 MP3)
测试数据:
| FBO附加纹理 内部格式 | 平均 帧率 | L2LoadStore (MB/s) | L2Texture (MB/s) | BusRead (MB/s) | BusWrite (MB/s) |
| RGB565 | 59.7 | 0.0 | 88.2 | 127.8 | 2 |
| RGB24 | 59.7 | 0.0 | 88.4 | 166.7 | 2.8 |
测试结论:颜色缓存区使用24位相比16位格式,BusRead和BusWrite带宽都有明显增加,BusRead增加24%,BusWrite增加28%。
Ø 测试用例2:验证FrameBuffer是否附加深度缓冲区对内存带宽的影响
渲染一个全屏四边形,仅修改是否附加深度缓冲区,验证对内存带宽影响。
测试机型:Oppo R15(GPU型号:Mali G72 MP3)
测试数据:
| 是否附件深度缓冲区 | 平均 帧率 | L2LoadStore (MB/s) | L2Texture (MB/s) | BusRead (MB/s) | BusWrite (MB/s) |
| 否 | 59.7 | 0.0 | 88.4 | 143 | 173 |
| 是 | 59.7 | 0.0 | 86.4 | 174 | 190 |
测试结论:附加深度缓冲区相比没有深度缓冲区,由于多了深度的读写,BusRead和BusWrite带宽都有增加。
Ø 测试用例3:验证纹理过滤方式对内存带宽的影响
渲染一个全屏四边形,仅修改四边形纹理过滤方式,验证对内存带宽影响。
测试机型:Oppo R15(GPU型号:Mali G72 MP3)
测试数据:
| 纹理 类型 | 平均 帧率 | 过滤方式 | L2LoadStore (MB/s) | L2Texture (MB/s) | BusRead (MB/s) | BusWrite (MB/s) |
| GL_Texture2D | 59.7 | Nearest | 0.0 | 64.8 | 132.2 | 0.7 |
| GL_Texture2D | 59.7 | 双线性 | 0.0 | 73.6 | 135.0 | 0.8 |
| GL_Texture2D | 59.6 | 三线性 | 0.0 | 94.7 | 162.2 | 0.8 |
测试结论:由于三线性需要采样两个MipMap,L2Texture带宽和BusRead都会增加。
From:

















 2225
2225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









