







昨天开组会,讲论文的时候老师一直在问我推荐系统中数据缺失方面的知识,之前没太考虑过,就随口说了一个冷启动的问题,解释了一下。确实后来想想,冷启动问题确实是推荐系统里数据缺失的一部分。
原有的根据用户冷启动、物品冷启动、系统冷启动解决方法可以解决冷启动的问题,以及利用专家标注数据去解决冷启动问题。
但是深度学习在冷启动问题上也有很好的解决办法,又搬出了网络这个利器。
基于专家的CF方法,可以降低对用户行为数据的依赖,解决新物品冷启动的问题。但是对于大多数初创公司或者刚刚启动的APP,没有能力也没有资金去获得如此大批量的专家数据。
而深度学习技术的推广,让我们可以减少对外部数据的依赖,直接从物品本质内容上去理解他。
案例一:CNN 在音频流派分类上的应用。
在音乐推荐中,音乐流派是相当重要的特征。前面也有提到国外的Pandora 音乐APP 中,通过专家数据描述歌曲的特征细化到了歌曲的编曲、乐器搭配、乐器演奏特征、风格、根源、人声的特征、曲调、旋律特征等这些维度。
一般来说,人们可以通过一定音乐常识的积累,对一首歌曲进行分类。专家在几秒钟内,可以判断一首歌曲是民谣、摇滚还是爵士。然而,尽管这项任务对我们来说很简单,但是音乐的数据库是庞大的,像QQ 音乐、网易云音乐等平台,音乐的量级都在千
万以上。如果分类一首歌曲需要最快花费3 秒来计算,人工对1000 万首歌分类至少需要833 小时,且这是理想状态之下。所以我们就在想能否通过使用深度学习来帮助我们完成这项劳动密集型任务。我们希望通过以下几个步骤来完成音乐的分类:
1 )提取己知流派分类的歌曲样本;
2 ) 训练一个深度神经网络来分类歌曲;
3 ) 使用分类器对未分类的歌曲进行流派分类。
首先,我们需要一个数据集,为此我们需要一个己知流派分类的样本库。在QQ 音乐、豆瓣、网易云音乐平台上均有这样的流派分类, 分类里面的歌曲虽然不全,但是己足够我们训练模型了。下面的案例主要选择了摇滚、民谣、爵士、电子四个流派,每个流
派下载了1000 首歌。
一旦我们有足够多的流派,并有足够的歌曲, 我们就可以开始从数据中提取重要信息。一首歌对应一个音频文件。经典的采样频率为44100Hz一一每秒音频存储44100 个值,而立体声则为两倍。这意味着一首3 分钟长的立体声歌曲包含7938000 个样本。这样训练量会非常大,我们可以先把立体声声道丢弃,因为它包含高度冗余的信息。

接下来使用傅里叶变换将我们的音频数据转换到频域。这使得数据的表示更加简单和紧凑,我们将其以谱图形式输出。这个过程会给我们生成一个PNG 文件,其中包含我们的歌曲的所有频率随着时间的变化。这个步骤可以借助libsora 工具来完成。我们使用
每秒50 像素( 每像素20ms ) ,以降低PNG 图片的分辨率并将图片切割成10~ 15s 的片段,因为一般来说10s 就足够用于判断音乐的分类了。最后就可以得到如图4.39 这样的频谱图。
时域位于z 轴上,频率位于u 轴上,最高频率在顶部,最低频率在底部。频率的缩放幅度以灰度显示,其中白色是最大值,黑色是最小值。这样我们就把音频分类问题,转化为图片分类问题。对应图片分类, 最常用的深度学习方案是CNN 。我们可以构建如图
4.40 所示的CNN 网络分类模型。
利用上面的CNN 分类模型,我们已经可以得到一个不错的音乐分类模型了。然而,CNN 模型却不完全适用于音频分类。一般图片分类具有invariance ( 不变性〉,即图片旋转后对分类不会有影响,**但是音频的频谱图并不是这样,它在z 轴和u 轴分别表示具体时域和频域的特征。**另外CNN 通过filter size 获取前后信息,但是受限于size 大小, longdependence 方面不如LSTM。所以本书作者进一步提出了CNN+LSTM 的音乐分类结构,网络结构如图4.41 所示。
可以看到,上面的模型是在二层卷积层后,把不同通道上相同时序上的特征组合起来,作为LSTM 层的输入,然后再通过全连接层提取出进一步的音频分类特征。经过测试,方案- CNN 分类模型的四分类准确率为67% , 而方案二的准确率可以达到73 % ,对最后的分类准确率提升比较明显。
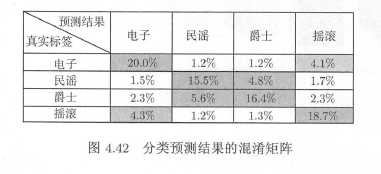
我们观察分类结果的混淆矩阵,其中纵坐标表示测试集音乐标注好的流派分类,横坐标为模型预测的分类。当纵坐标和横坐标标签一致时,说明模型预测正确;不一致时,说明模型预测有偏差。如图所示,标注为电子的音乐预测正确,即预测为电子音乐的数量,占整个测试集的20.03 。可以发现预测错误的主要是电子和摇滚、民谣和爵士的互错。事实上,这些流派本身比较接近,比如很多歌曲同时属于电子和摇滚两个流派。
除了流派分类结果可作为标签特征应用到模型之外,模型倒数第二层的128 维向量也可以作为歌曲特征应用到模型里,图4.43 是将各流派抽取了top100 新歌向量降维到二维平面后的结果。可以看到流派聚类效果也比较明显。事实上,使用高维度的向量特征,比流派分类这种低维特征信息表达能力强,对模型效果提升更加明显。

案例二:人脸魅力值打分在视频推荐中的应用。
2015 年的五一假期,微软how-old.net 大火。不仅有“郭德纲和林志颖之间其实差了个吴奇隆”的笑话,又有名人如李开复发微博称“终于达成愿望,有个比自己小50 岁的
老婆”的调侃。当时通过照片对年龄进行评估的技术刚刚形成应用,外界对微软的此项技术产生了各种质疑和猜测。但是现在看来,只有要大量的样本,训练一个端到端的年龄预测模型并不困难。

相较于传统的SVR 等机器学习方法,使用CNN 模型对魅力值的打分准确率已经有了显著提升。传统的SVR 模型在该样本集上的测试误差为0.3961 , 而使用两层CNN 后能降低到0.235 8 0
CNN 网络的深度对最后的分类和识别的效果有着很大的影响, 所以一般想法就是能把网络设计得越深越好, 但是事实上却不是这样, 常规的网络的堆叠( plain network )在网络很深的时候, 效果却越来越差了。
造成这种现象的原因之一即是网络越深,梯度消失的现象就越来越明显,网络的训练效果也不会很好。但是现在浅层的网络( shallower network )又无法明显提升网络的识别效果,所以现在要解决的问题就是怎样在加深网络的情况下又能够解决梯度消失的问
题。
为此引入了残差网络结构( residual network ) ,通过残差网络, 可以把网络层构建得很深,据说现在可以达到1000 多层,最终的网络分类的效果也非常好。
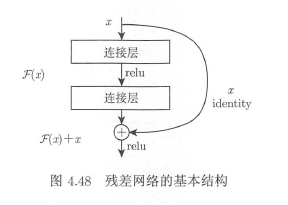
使用以上ResNet50 网络finetuning 后,模型训练后的误差可以有显著的降低( 见表4.4 )。在多数情况下,基于己训练好的网络进行finetuni吨,都能显著提高效率和效果,这是图片分类问题的小窍门。Keras 中包含了大部分效果比较好的图像分类模型。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









