









1、先说为什么会有BN:
我们在训练一个深度网络的时候,每一层的结果对整体结果都有很大影响的。而我们每次网络的输入都是batch_size大小的,这样做的目的是避免错误样本导致的梯度更新错误,而就是这样的batch_size个样本,他们在中间层的网络输出按道理来说应该分布是类似的,但是实际情况不是这样,他们的输出分布是乱七八糟的,网络层数越大,这种差异就越大,这就导致梯度更新方向手足无措,这个问题叫做covariate shift问题;还有一个问题,假设我们用的sigmoid函数,它的梯度在0附近的话比较大,如果激活函数的输入分布是乱七八糟的话就会导致BPTT时梯度消失的问题;
BN要解决的就是上述两个问题,具体怎么处理呢?
2、如何做BN:
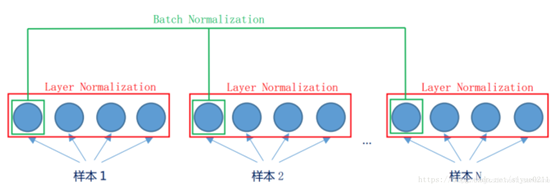
对激活函数的输入进行处理,与batch_size有很大的关系。我们知道每一层有很多的神经元,对于单个神经元来说,每次的输入是batch_size个样本的数据,看下图,最左边的就是这个神经元,那我们要整合的就是这个神经元的数据,
第一步:求均值
第二步:求方差
第三步:数值代换
第四步:加入scale和shift

得,你肯定该有疑问了,为啥还有第四步,前三步不就ok了,按道理来说,前三步是够了,但论文解释说是为了有可能变为原来的输入,这样的话原来的输入一部分改变了,一部分没有改变,有选择性的,这样可以提升网络的能力!无论你信不信,反正我信了。
3、BN的问题:
优点之前说了,解决covariate shift问题+梯度消失+加快训练。所以肯定存在缺点,其中一个那就是batch_size,这个值的大小会明显影响原始数据的分布;还有一个问题是BN对输入长度的影响,RNN中的输入是不定长的,那这样就会导致不同长度的输入没法BN呀。
4、LN = BN的改进:
看图1,我们知道了BN,还有另外一种就是LN,这个我以前理解错了,哎,transformer中的self-attention层的输出加上了输入x之后再进行LN,就是残差网络之后再LN,我之前居然把残差当做LN了,够傻的了。
看图说话,LN是对这一层的多个神经元进行处理,而且处理的是单样本的,与batch_size没有关系,意思就是输入一个样本,进入该层网络之后,假设有c个神经元,那就是要对这C个做上面的normalization操作,这样就可以解决BN的问题了。有啥缺点呢,暂时我也没想到,transformer中用的就是LN
5、WN:对权重的操作
发现没?之前的操作都是对中间层输出进行横向或者纵向的操作,那我们也可以对这个权重矩阵进行操作呀。但是好像效果很不好,















 5189
5189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









