





mrcc srcc
The mrcc project’s homepage is here: mrcc project.
mrcc项目的主页在这里: mrcc project 。
抽象 (Abstract)
mrcc is an open source compilation system that uses MapReduce to distribute C code compilation across the servers of the cloud computing platform. mrcc is built to use Hadoop by default, but it is easy to port it to other could computing platforms, such as MRlite, by only changing the interface to the platform. The mrcc project homepage is http://www.ericzma.com/projects/mrcc/ and the source code is public available.
mrcc是一个开放源代码编译系统,它使用MapReduce在云计算平台的服务器之间分发C代码编译。 mrcc默认情况下使用Hadoop ,但仅更改平台接口即可轻松将其移植到其他可能的计算平台,例如MRlite。 mrcc项目主页为http://www.ericzma.com/projects/mrcc/ ,其源代码是公开可用的。
介绍 (Introduction)
Compiling a big project such as Linux may cost much time. Usually, a big project consists of many small source code files and many of these source files can be compiled simultaneously. Parallel compilation on distributed servers is a way to accelerate the compilation.
编译大型项目(例如Linux)可能会花费大量时间。 通常,大型项目由许多小型源代码文件组成,并且其中许多源文件可以同时编译。 分布式服务器上的并行编译是一种加速编译的方法。
In this project, we build a compilation system on top of MapReduce for distributed compilation.
在这个项目中,我们在MapReduce之上构建了一个用于分布式编译的编译系统。
设计与建筑 (Design and architecture)
The system of mrcc consists of one master server that controls the job and many slave servers that do the compilation work as shown in Figure 1. The master and the slaves can be one of the jobtracker or the tasktracker of the MapReduce system.
mrcc的系统由一个控制作业的主服务器和许多进行编译工作的从属服务器组成,如图1所示。主服务器和从属服务器可以是MapReduce系统的jobtracker或tasktracker之一。
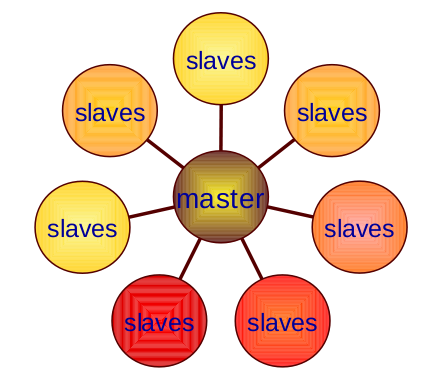
Figure 1: The architecture of mrcc
图1:MRCC的体系结构
mrcc runs as a front end of cc. When compiling one project, the user only need to add “-jN” parameter and “CC=mrcc” at the end of the normal “make” arguments and make the project on the master server. make will build a dependency tree of the project source files and then fork multiple mrcc instances when several source files can be compiled in parallel.
mrcc作为cc的前端运行。 编译一个项目时,用户只需在常规“ make”参数的末尾添加“ -jN”参数和“ CC = mrcc” ,然后在主服务器上创建项目。 make将构建项目源文件的依赖关系树,然后在可以并行编译多个源文件时派生多个mrcc实例。
mrcc will first do preprocessing such as expanding the options and inserting the header files into the source file. Then mrcc will determines whether the job can be done on MapReduce depending on the compiler’s options. For ensuring the correctness of the compilation, mrcc only distributes the jobs to slaves when they are safe. The other jobs are done on the master server locally.
mrcc首先将进行预处理,例如扩展选项并将头文件插入源文件。 然后, mrcc将根据编译器的选项确定是否可以在MapReduce上完成作业。 为了确保编译的正确性,mrcc仅在安全时才将作业分发给从属。 其他作业在本地主服务器上完成。
When doing remote compilation, mrcc first put the preprocessed source file into the network file system which is HDFS when using Hadoop, then it runs the job on MapReduce. Only the mapper which is called mrcc-map is used in this system. mrcc-map first gets the source file from the network file system, and then it calls the compiler locally on the slave. After the compilation finished, mrcc-map puts the object file which is the result of the compilation back into the network file system. After mrcc-map finished, mrcc on the master server get the object file from network file system and puts it into the local file system on the master node. By now, the compilation of one source file is finished. make can go on to compile the other files that depends on the completed one.
在进行远程编译时, mrcc首先将预处理的源文件放入使用Hadoop的网络文件系统HDFS中,然后在MapReduce上运行作业。 在该系统中仅使用称为mrcc-map的映射器。 mrcc-map首先从网络文件系统获取源文件,然后在从属服务器上本地调用编译器。 编译完成后, mrcc-map将作为编译结果的目标文件放回到网络文件系统中。 mrcc-map完成后,主服务器上的mrcc从网络文件系统获取目标文件,并将其放入主节点上的本地文件系统中。 至此,一个源文件的编译完成。 make可以继续编译依赖于已完成文件的其他文件。
实作 (Implementation)
The mrcc compilation system consists of two core parts: the main program mrcc and the mapper for MapReduce called mrcc-map.
mrcc编译系统包括两个核心部分:主程序mrcc和MapReduce的映射器mrcc-map 。
The overall system consists of seven parts:
整个系统包括七个部分:
- mrcc (mrcc.c, compile.c, remote.c, safeguard.c, exec.c);mrcc (mrcc.c,compile.c,remote.c,guard.c,exec.c);
- mrcc-map (mrcc-map.c);mrcc-map (mrcc-map.c);
- The compiler options processing part (args.c); 编译器选项处理部分(args.c);
- The logging part (trace.c, traceenv.c); 日志记录部分(trace.c,traceenv.c);
- The network file system and MapReduce interface part (netfsutils.c, mrutils.c); 网络文件系统和MapReduce接口部分(netfsutils.c,mrutils.c);
- The temporary files cleaning up part (tempfile.c, cleanup.c); 临时文件清理部分(tempfile.c,cleanup.c);
- Some other utilities for processing string, file path and name, and I/O operation (utils.c, files.c, io.c). 其他一些用于处理字符串,文件路径和名称以及I / O操作的实用程序(utils.c,files.c,io.c)。
In this report, we only introduce the two core parts of this system: mrcc and mrcc-map.
在此报告中,我们仅介绍该系统的两个核心部分: mrcc和mrcc-map 。
MRCC (mrcc)
The work flow is shown as Figure 2. There are five time lines in the process: mrcc is called, begins to compile locally or remotely while source file is being preprocessed, the preprocessing finishes, mrcc returns and mrcc finishes. During this process one or two new process is created by mrcc for source preprocessing or compiling. And some other works such as logging are done which we will not introduce. In the work flow graph, only the core functions are shown.
工作流程如图2所示。在此过程中,有五个时间轴:调用mrcc,在对源文件进行预处理时开始本地或远程编译,预处理完成,mrcc返回并且mrcc完成。 在此过程中,mrcc创建一个或两个新过程以进行源预处理或编译。 还有一些其他工作,例如日志记录,我们将不再介绍。 在工作流程图中,仅显示了核心功能。
Figure 2: Work flow of mrcc
图2:MRCC的工作流程
When mrcc is called, it first preprocesses the compiler options by functions such as expand_preprocessor_options() which expands the arguments passed to preprocessor. Then* make_tmpnam()* is called to creates a temporary file inside the temporary directory and registers it for later cleanup. In make_tmpnam() a random number is generated for the temporary file. We use this random number as the id of the job and the object file name. The temporary output directory of the MapReduce job will be generated from this id to avoid name conflict ion. For example, if the temporary file name for storing a preprocessed source file is “/tmp/mrcc_36994a30.i”, the object file name and the output directory name are “/tmp/mrcc_36994a30.o” and “/tmp/mrcc_36994a30.odir” on the network file system.
调用mrcc时,它首先通过诸如expand_preprocessor_options()之类的函数对编译器选项进行预处理,这些函数将扩展传递给预处理器的参数。 然后,调用make_tmpnam()*在临时目录中创建一个临时文件,并将其注册以供以后清除。 在make_tmpnam()中,将为临时文件生成一个随机数。 我们使用此随机数作为作业的ID和目标文件名。 MapReduce作业的临时输出目录将从该ID生成,以避免名称冲突。 例如,如果用于存储预处理源文件的临时文件名为“ /tmp/mrcc_36994a30.i”,则目标文件名和输出目录名称为“ /tmp/mrcc_36994a30.o”和“ /tmp/mrcc_36994a30.odir”在网络文件系统上。
mrcc then scans the options to determine whether this job can be done on remote server by calling scan_args(). While scanning the arguments, mrcc should also determine the default output file name according to the input source name. It is a little hard because the cc option rules are pretty complex. After that, mrcc calls the cpp_maybe() function to fork another process to run the preprocessor. The preprocessor insert header files into the source file. So the compiler version on the master and slaves needn’t to be identical since the remote server needn’t to do preprocessing.
然后,mrcc扫描选项以确定是否可以通过调用scan_args ()在远程服务器上完成此作业。 在扫描参数时,mrcc还应根据输入源名称确定默认的输出文件名。 有点麻烦,因为cc选项规则非常复杂。 之后,mrcc调用cpp_maybe()函数派生另一个进程来运行预处理器。 预处理器将头文件插入源文件。 因此,主服务器和从服务器上的编译器版本不必相同,因为远程服务器不需要进行预处理。
Then mrcc compiles the source remotely or locally depending on the compiler options. Local compilation is straight forward. mrcc wait for the preprocessor process to complete and fork another process to do the compilation.
然后, mrcc根据编译器选项在远程或本地编译源。 本地编译是直接的。 mrcc等待预处理器进程完成,然后派生另一个进程进行编译。
If the source file can be compiled on remote server, mrcc calls the function compile_remote(). mrcc should first wait for preprocessor to complete. Then mrcc put the preprocessed file into the network file system. After that, mrcc calls call_mapper() to generate relevant options and arguments from the id of the temporary file and the options and arguments of the compiler. The it runs the job on MapReduce. In this project, we use Hadoop Streaming to run the mrcc-map on the slaves. The options for mrcc-map are passed with the streaming job options.
如果可以在远程服务器上编译源文件,则mrcc调用函数compile_remote() 。 mrcc应该首先等待预处理程序完成。 然后,mrcc将预处理后的文件放入网络文件系统中。 之后,mrcc调用call_mapper()从临时文件的ID以及编译器的选项和参数生成相关的选项和参数。 它在MapReduce上运行作业。 在这个项目中,我们使用Hadoop Streaming在从站上运行mrcc-map。 mrcc-map的选项与流作业选项一起传递。
After mrcc-map successfully finishes the job, the object file now exists on the network file system. mrcc generates the output file name from the id of the temporary file and calls get_result_fs() to retrieve the object file from the network file system.
mrcc-map成功完成作业后,目标文件现在位于网络文件系统上。 mrcc根据临时文件的ID生成输出文件名,并调用get_result_fs()从网络文件系统中检索目标文件。
As soon as mrcc gets the object file, it returns so that make can continue to compile other source files that may depend on the completed one. But there are still several temporary files and directories on the network file system and local disk that needed to be cleaned up. We use a tricky function atexit() to do the cleaning up work after mrcc returns. By using atexit() some of the clean up I/O operation are done while the next compilation is running to improve the overall performance.
一旦mrcc获取了目标文件,它就会返回,以便make可以继续编译可能依赖于已完成文件的其他源文件。 但是,网络文件系统和本地磁盘上仍有一些临时文件和目录需要清理。 我们使用棘手的函数atexit()在mrcc返回后执行清理工作。 通过使用atexit(),一些清理I / O操作在下一次编译运行时完成,以提高整体性能。
地图 (mrcc-map)
mrcc-map is put in local directories on all the slaves servers. We doing this to avoid distributing the mrcc-map when the job is called because the mrcc-map does not changed during compiling one project. The flow of mrcc-map is simpler than mrcc as shown in Figure 3.
mrcc-map放在所有从属服务器上的本地目录中。 我们这样做是为了避免在调用作业时分发mrcc-map,因为在编译一个项目期间mrcc-map不会更改。 mrcc-map的流程比mrcc更简单,如图3所示。
mrcc-map first parse it’s arguments and finds out the file id generated by mrcc and the compilation options and arguments. Then mrcc-map gets the preprocessed file from net file system according to the id. After getting the preprocessed file, mrcc-map calls the local gcc/cc compiler and passes the compilation options and arguments to it. Then mrcc-map puts the object file to the netwrok file system and returns immediately. The clean up work is done after mrcc-map finishes to parallel I/O operation and the compilation in the same way that mrcc does.
mrcc-map首先解析它的参数,然后找出mrcc生成的文件ID以及编译选项和参数。 然后,mrcc-map根据ID从网络文件系统中获取预处理文件。 获取预处理文件后,mrcc-map会调用本地gcc / cc编译器,并将编译选项和参数传递给它。 然后mrcc-map将目标文件放入netwrok文件系统并立即返回。 在mrcc-map完成并行I / O操作和编译之后,以与mrcc相同的方式完成清理工作。
Figure 3: mrcc-map work flow
图3:mrcc-map工作流程
评价 (Evaluation)
Please refer to this paper for the evaluation experiments and results:
评估实验和结果请参考本文:
Z. Ma and L. Gu.The Limitation of MapReduce: A Probing Case and a Lightweight Solution. In Proc. of the 1st Intl. Conf. on Cloud Computing, GRIDs, and Virtualization (CLOUD COMPUTING 2010). Nov. 21-26, 2010, Lisbon, Portugal. (PDF from one author’s homepage)
Z.Ma和L.Gu. MapReduce的局限性:一个探测案例和一个轻量级的解决方案 。 在过程中。 第一国际机场 Conf。 有关云计算,GRID和虚拟化的信息(CLOUD COMPUTING 2010)。 2010年11月21日至26日,葡萄牙里斯本。 (来自一位作者主页的PDF )
安装与配置 (Installation and configuration)
安装Hadoop (Install hadoop)
Install Hadoop into a directory, such as /lhome/zma/hadoop and start Hadoop.
将Hadoop安装到目录中,例如/ lhome / zma / hadoop,然后启动Hadoop。
Please refer to this tutorial for how to install and start Hadoop: Hadoop Installation Tutorial (Hadoop 1.x)
请参考本教程以了解如何安装和启动Hadoop: Hadoop安装教程(Hadoop 1.x)
组态 (Configuration)
In netfsutils.c:
在netfsutils.c中:
As an example, we assume hadoop command’s full path is: /lhome/zma/hadoop/bin/hadoop
例如,我们假设hadoop命令的完整路径为:/ lhome / zma / hadoop / bin / hadoop
Set the variables as follows (We use the full path to avoid bad PATH environment).
如下设置变量(我们使用完整路径以避免不良的PATH环境)。
const char* put_file_fs_cmd = "/lhome/zma/hadoop/bin/hadoop dfs -put";
const char* get_file_fs_cmd = "/lhome/zma/hadoop/bin/hadoop dfs -get";
const char* del_file_fs_cmd = "/lhome/zma/hadoop/bin/hadoop dfs -rm";
const char* del_dir_fs_cmd = "/lhome/zma/hadoop/bin/hadoop dfs -rmr";In mrutils.c
在mrutils.c中
Set the variables and We also use the full path.
设置变量,然后我们也使用完整路径。
const char* mr_exec_cmd_prefix = "/lhome/zma/hadoop/bin/hadoop jar /lhome/zma/hadoop/contrib/streaming/hadoop-0.20.2-streaming.jar -mapper ";
const char* mr_exec_cmd_mapper = "/home/zma/bin/mrcc-map ";
const char* mr_exec_cmd_parameter = "-numReduceTasks 0 -input null -output ";
编译安装: (Compile and install:)
<code>$ make
# make install
</code>如何使用它 (How to use it)
在MapReduce上使用mrcc编译项目 (Compile the project using mrcc on MapReduce)
As building a project:
建立项目时:
$ make -j16 CC=mrcc
-jN: N is the maximum parallel compilation number. N may be set to the number of CPUs in the cluster.
-jN:N是最大并行编译数。 可以将N设置为群集中的CPU数量。
如果需要,启用详细日志记录 (Enable detailed logging if needed)
On master node in the same shell where mrcc runs:
在运行mrcc的同一shell中的主节点上:
$ . docs/mrcc.export
Or set environment variables:
或设置环境变量:
MRCC_LOG=./mrcc.log
MRCC_VERBOSE=1
export MRCC_LOG
export MRCC_VERBOSE
相关工作 (Related work)
GNU make can execute many commands simultaneously by using “-j” option. But make can only execute many commands on local machine. mrcc makes use of this feature of make and distributed these commands (compilation) across servers on MapReduce.
通过使用“ -j”选项,GNU make可以同时执行许多命令。 但是make只能在本地计算机上执行许多命令。 mrcc利用了make的这一功能,并将这些命令(编译)分布在MapReduce的服务器之间。
distcc is a program to distribute compilation of C/C++/Objective code between several machines on a network. distcc must use a daemon on every slaves and the master must controls all the jobs details such as load balance and failure tolerance. distcc is easy to set up and fast in a cluster with a small amount of machines, but it will be hard to manage this system when distcc is running on a computing platform with thousands of machines.
distcc是一个程序,用于在网络上的多台计算机之间分发C / C ++ /目标代码的编译。 distcc必须在每个从属服务器上使用守护程序,而主服务器必须控制所有作业的详细信息,例如负载平衡和故障容限。 distcc易于在具有少量计算机的集群中设置并快速运行,但是当distcc在具有数千台计算机的计算平台上运行时,将很难管理该系统。
参考资料 (References)
- Dean, J. and Ghemawat, S. 2004. MapReduce: simplified data processing on large clusters. In Proceedings of the 6th Conference on Symposium on Operating Systems Design & Implementation – Volume 6 (San Francisco, CA, December 06 – 08, 2004). Dean,J.和Ghemawat,S.2004。MapReduce:简化大型集群上的数据处理。 在第六届操作系统设计与实现研讨会会议记录–第6卷(加利福尼亚州旧金山,2004年12月6日至8日)上。
- http://hadoop.apache.orghttp://hadoop.apache.org
- http://www.ericzma.com/projects/mrcc/http://www.ericzma.com/projects/mrcc/
- http://hadoop.apache.org/common/releases.html#Downloadhttp://hadoop.apache.org/common/releases.html#Download
- http://www.kernel.org/http://www.kernel.org/
- https://github.com/distcc/distcchttps://github.com/distcc/distcc
- http://www.gnu.org/software/make/http://www.gnu.org/software/make/
- The Limitation of MapReduce: A Probing Case and a Lightweight Solution. In Proc. of the 1st Intl. Conf. on Cloud Computing, GRIDs, and Virtualization (CLOUD COMPUTING 2010). Nov. 21-26, 2010, Lisbon, Portugal.MapReduce的局限性:一个探测案例和一个轻量级的解决方案 。 在过程中。 第一国际机场 Conf。 有关云计算,GRID和虚拟化的信息(CLOUD COMPUTING 2010)。 2010年11月21日至26日,葡萄牙里斯本。
翻译自: https://www.systutorials.com/mrcc-a-distributed-c-compiler-system-on-mapreduce/
mrcc srcc















 876
876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









