





 本文介绍了如何基于行为树的概念设计一个简单但可扩展的AI系统,以应用于游戏中的机器人行为。通过行为树,机器人可以表现出更丰富和智能的行为,如徘徊、攻击或逃避。文章通过一个简单的机器人竞技场游戏为例,逐步讲解了如何构建和实现行为树,以创建不同类型的AI行为。
本文介绍了如何基于行为树的概念设计一个简单但可扩展的AI系统,以应用于游戏中的机器人行为。通过行为树,机器人可以表现出更丰富和智能的行为,如徘徊、攻击或逃避。文章通过一个简单的机器人竞技场游戏为例,逐步讲解了如何构建和实现行为树,以创建不同类型的AI行为。

人工智能
游戏AI是一个非常广泛的主题,尽管有很多材料,但我找不到能以较慢,更易理解的速度缓慢引入这些概念的东西。 本文将尝试解释如何基于行为树的概念来设计一个非常简单但可扩展的AI系统。
什么是AI?
人工智能是参与游戏的实体表现出的类似于人类的行为。 与其说是实体执行的智能和周到的行动,还不如说是一种实际的智能推理驱动的行为。 目的是试图欺骗玩家,使他们认为其他“智能”实体是由人类而不是机器控制的。 说起来容易做起来难,但是我们可以使用很多技巧来实现一些真正好的,看似随机和“智能”的行为。
一个例子
在我们跳入有趣的话题之前,让我们草拟一个我们想要实现的计划。 同样,我将以机器人为例。 想象一下一个竞技场,机器人将在其中争夺战,最后一个站位的机器人将是赢家。
竞技场将是一块木板,机器人将随机放置在上面。 我们将其制作为基于回合的游戏,以便我们可以追踪整个AI的发展,但可以轻松地将其转变为实时游戏。
规则很简单:
- 木板是矩形
- 机器人可以在任一方向上每转一圈将瓷砖移动到任何相邻的未占用瓷砖上
- 机器人具有一定范围,并且可以向其范围内的机器人射击
- 机器人将具有通常的属性:它们造成的伤害和生命值
为了简单起见,我们将使用非常简单的结构。 该应用程序将具有Droid类和Board类。 机器人将具有以下定义它的属性:
public class Droid {
final String name;
int x;
int y;
int range;
int damage;
int health;
Board board;
public Droid(String name, int x, int y, int health, int damage, int range) {
this.name = name;
this.x = x;
this.y = y;
this.health = health;
this.damage = damage;
this.range = range;
}
public void update() {
// placeholder for each turn or tick
}
/* ... */
/* getters and setters and toString() */
/* ... */
} Droid只是具有一些属性的简单pojo。 这些属性不言自明,但这是它们的简短摘要:
-
name–机器人的唯一名称,也可以用于ID。 -
x和y–网格上的坐标。 -
health,damage和range-它说了什么。 -
board–是机器人所在的Board以及其他机器人的参考。 我们需要这样做,因为机器人将通过了解其环境(即board <./ li>)来做出决策。
还有一个空的update()方法,每次droid结束旋转时都会调用该方法。 如果是实时游戏,则从游戏循环(最好是从游戏引擎)中调用update方法。
还有一些显而易见的getter和setter以及toString()方法,它们从清单中省略了。 Board类非常简单。
public class Board {
final int width;
final int height;
private List<Droid> droids = new ArrayList<Droid>();
public Board(int width, int height) {
this.width = width;
this.height = height;
}
public int getWidth() {
return width;
}
public int getHeight() {
return height;
}
public void addDroid(Droid droid) {
if (isTileWalkable(droid.getX(), droid.getY())) {
droids.add(droid);
droid.setBoard(this);
}
}
public boolean isTileWalkable(int x, int y) {
for (Droid droid : droids) {
if (droid.getX() == x && droid.getY() == y) {
return false;
}
}
return true;
}
public List<Droid> getDroids() {
return droids;
}
} 它具有width和height ,并且包含机器人列表。 它还包含一些方便的方法来检查给定坐标上是否已经存在机器人,以及一种轻松地逐个添加机器人的方法。
到目前为止,这是相当标准的。 我们可以在板上分散一些机器人,但它们不会做任何事情。 我们可以创建板,向其中添加一些机器人,然后开始调用update() 。 它们只是一些愚蠢的机器人。
不太傻的机器人
为了使droid做某事,我们可以在其update()方法中实现逻辑。 这就是所谓的每一次跳动或在我们的情况下每转一次的方法。 例如,我们希望我们的机器人在竞技场(木板)上徘徊,如果他们看到射程范围内的其他机器人,请接合它们并开始向它们射击直到它们死亡。 这将是非常基本的AI,但仍然是AI。
伪代码如下所示:if enemy in range then fire missile at it
otherwise pick a random adjacent tile and move there
这意味着,机器人之间的任何相互作用都将导致僵持,较弱的机器人会被破坏。 我们可能要避免这种情况。 因此,我们可以补充一下,如果机器人有可能丢失,请尝试逃跑。 仅在无处可逃时站起来战斗。
if enemy in range then
if enemy is weaker then fightescape route exists then escapefightwander
一切都很好。 机器人将开始“智能化”地工作,但是除非我们添加更多代码来做更多聪明的事情,否则它们仍然非常有限。 而且,它们将起到相同的作用。 想象一下,如果您将它们放在更复杂的舞台上。 在竞技场上,有一些道具如力量道具可以增强力量,可以避免障碍。 例如,当机器人四处飞来飞去时,请决定在拿起医疗/修理包与拿起武器加电之间。它很快就会失控。 如果我们想要一个行为不同的机器人该怎么办。 一个是攻击机器人,另一个是修理机器人。 当然,我们可以通过对象合成来实现这一目标,但是机器人的大脑将极其复杂,游戏设计的任何变化都需要付出巨大的努力才能适应。
让我们看看是否可以提出一个可以解决这些问题的系统。
大脑来了
我们可以将机器人的AI模块视为某种大脑。 大脑由遵循一系列规则作用于机器人的几个例程组成。 这些规则支配着例程的执行,因此它将生存和赢得比赛的机会最大化作为最终目标。 如果我们想到由例程组成的人类大脑,并以马斯洛的需求层次作为参考,我们可以立即识别出一些例程。
- 生理程序–每次都需要执行的程序,否则将没有任何生命
- 自给自足的生活程序–一旦生活条件得到满足,就必须执行该程序,以确保长期生存
- 有抱负的例程–如果在维持生计后仍需要再次执行生计时还剩下时间,将执行此例程
让我们分解一下人类的智慧。 人类需要呼吸才能生存。 每次呼吸都会消耗能量。 一个人可以呼吸这么多,直到能量耗尽。 要补充能量,就需要吃饭。 只有在他/她有食物可支配的情况下才能吃饭。 如果没有可用的食物,则需要消耗更多的能量。 如果购买食物需要很长时间(例如,需要狩猎)并且获得的食物量很少,那么在食用之后,人们需要更多食物,并且例程会立即重新开始。 如果从超市购买散装的食物,吃完后还有很多剩余的空间,这样人类就可以继续做更多有趣的事情,这些都是他/她理想的部分。 例如,结交朋友,发动战争或看电视之类的事情。试想一下,人脑中有多少东西可以使我们发挥功能并尝试对其进行模拟。 所有这些都忽略了我们正在获得和响应的大多数刺激。 为此,我们需要对人体进行参数设置,并且由刺激触发的每个传感器将更新正确的参数,并且执行的例程将检查新值并采取相应措施。 我现在不会描述它,但是您希望我有所想法。
让我们切换回更简单的机器人。 如果我们尝试使人类例程适应于机器人,我们将得到如下内容:
- 生理的/存在的-在本示例中我们可以忽略这一部分,因为我们设计的是机器人,它们是机械的。 当然,对于它们来说,它们仍然需要从电池或其他可能耗尽的能源中获取能量(例如动作点)。 为了简单起见,我们将忽略这一点,并认为能源是无限的。
- 生存/安全–此例程将确保机器人在避免当前威胁的情况下在当前回合中存活并存活。
- 有抱负–一旦安全例行检查成功就可以启动,而不必激活机器人的逃逸例行程序。 机器人目前的简单愿望是杀死其他机器人。
尽管所描述的例程非常简单并且可以进行硬编码,但是我们将要实现的方法更加复杂。 我们将使用基于行为树的方法。
首先,我们需要将机器人的所有活动委托给它的大脑。 我将其称为“ Routine而不是大脑。 它可以被称为Brain或AI或其他任何东西,但我选择Routine是因为它将作为组成所有例程的基类。 它还将负责控制大脑中的信息流。 Routine本身是具有3个状态的有限状态机。
public abstract class Routine {
public enum RoutineState {
Success,
Failure,
Running
}
protected RoutineState state;
protected Routine() { }
public void start() {
this.state = RoutineState.Running;
}
public abstract void reset();
public abstract void act(Droid droid, Board board);
protected void succeed() {
this.state = RoutineState.Success;
}
protected void fail() {
this.state = RoutineState.Failure;
}
public boolean isSuccess() {
return state.equals(RoutineState.Success);
}
public boolean isFailure() {
return state.equals(RoutineState.Failure);
}
public boolean isRunning() {
return state.equals(RoutineState.Running);
}
public RoutineState getState() {
return state;
}
}这三种状态是:
-
Running-该例程当前正在运行,并且将在下一回合中作用于机器人。 例如。 该例程负责将机器人移动到某个位置,并且机器人在运输过程中仍然不间断地移动。 -
Success–例行程序已经完成,并且成功完成了应做的工作。 例如,如果例程仍然是“移动到位置”,则当机器人到达目的地时例程成功。 -
Failure-使用前面的示例(移至),机器人的移动被中断(机器人被破坏或出现了意外障碍或其他常规例程受到干扰)并且没有到达目的地。
Routine类具有act(Droid droid, Board board)抽象方法。 我们需要传入Droid和Board因为当例程执行操作时,它会在droid上并且在知道droid的环境即董事会上也这样做。 例如,moveTo例程将在每转一圈更改机器人的位置。 通常,当例程作用于机器人时,它会使用从其环境中收集的知识。 这些知识是根据实际情况建模的。 想象一下,机器人(像我们人类一样)不能看到整个世界,而只能看到它的视线范围。 我们人类的视野大约为135度,因此,如果我们要模拟人类,我们将进入一个包含我们看到的区域和其中所有可见分量的世界切片,并通过例行程序来尽其所能并得出结论。 我们也可以对机器人进行此操作,只需传递range所覆盖的板子部分即可,但我们现在将使其保持简单并使用整个板子。 start() , succeed()和fail()方法是简单的公共可重写方法,可以相应地设置状态。 另一方面, reset()方法是抽象的,必须由每个具体例程来实现,以重置该例程专有的任何内部状态。 其余的是查询例程状态的便捷方法。
学习走路
让我们实现第一个具体例程,即上面讨论的MoveTo 。
public class MoveTo extends Routine {
final protected int destX;
final protected int destY;
public MoveTo(int destX, int destY) {
super();
this.destX = destX;
this.destY = destY;
}
public void reset() {
start();
}
@Override
public void act(Droid droid, Board board) {
if (isRunning()) {
if (!droid.isAlive()) {
fail();
return;
}
if (!isDroidAtDestination(droid)) {
moveDroid(droid);
}
}
}
private void moveDroid(Droid droid) {
if (destY != droid.getY()) {
if (destY > droid.getY()) {
droid.setY(droid.getY() + 1);
} else {
droid.setY(droid.getY() - 1);
}
}
if (destX != droid.getX()) {
if (destX > droid.getX()) {
droid.setX(droid.getX() + 1);
} else {
droid.setX(droid.getX() - 1);
}
}
if (isDroidAtDestination(droid)) {
succeed();
}
}
private boolean isDroidAtDestination(Droid droid) {
return destX == droid.getX() && destY == droid.getY();
}
} 这是一个非常基本的类,它将使机器人将一个磁贴向目的地移动,直到到达目的地。 除了机器人是否处于活动状态之外,它不会检查任何其他约束。 那就是失败的条件。 该例程具有2个参数destX和destY 。 这些是MoveTo例程将用来实现其目标的最终属性。 该例程的唯一职责是移动机器人。 如果无法做到这一点,它将失败。 而已。 在这里,单一责任非常重要。 我们将看到如何将这些结合起来以实现更复杂的行为。 reset()方法只是将状态设置为Running 。 它没有其他内部状态或值需要处理,但是需要覆盖。该例程的核心是act(Droid droid, Board board)方法,该方法执行操作并包含逻辑。 首先,它检查故障情况,即机器人是否死亡。 如果它已经死了并且例程处于活动状态(状态为Running ),则该例程将无法执行应有的操作。 它调用超类的默认fail()方法将状态设置为Failure并退出该方法。方法的第二部分检查成功条件。 如果机器人尚未到达目的地,则将机器人向目的地移动一格。 如果到达目的地,则将状态设置为Success 。 检查isRunning()以确保该例程仅在该例程处于活动状态且尚未完成时才起作用。
我们还需要填写Droid的update方法以使其使用例程。 这只是一个简单的委托。 它是这样的:
public void update() {
if (routine.getState() == null) {
// hasn't started yet so we start it
routine.start();
}
routine.act(this, board);
} 它应该仅由第6行组成,但我还要检查一下状态是否为null ,如果为null ,则start例程。 这是在首次调用update启动例程的一种方法。 这是一种准命令模式,因为在act方法中,将action命令的接收者作为参数(即机器人本身)作为参数。 我还修改了Routine类以在其中记录不同的事件,因此我们可以看到正在发生的事情。
// --- omitted --- */
public void start() {
System.out.println(">>> Starting routine: " + this.getClass().getSimpleName());
this.state = RoutineState.Running;
}
protected void succeed() {
System.out.println(">>> Routine: " + this.getClass().getSimpleName() + " SUCCEEDED");
this.state = RoutineState.Success;
}
protected void fail() {
System.out.println(">>> Routine: " + this.getClass().getSimpleName() + " FAILED");
this.state = RoutineState.Failure;
}
// --- omitted --- */ 让我们用一个简单的Test类对其进行测试。
public class Test {
public static void main(String[] args) {
// Setup
Board board = new Board(10, 10);
Droid droid = new Droid("MyDroid", 5, 5, 10, 1, 2);
board.addDroid(droid);
Routine moveTo = new MoveTo(7, 9);
droid.setRoutine(moveTo);
System.out.println(droid);
// Execute 5 turns and print the droid out
for (int i = 0; i < 5; i++) {
droid.update();
System.out.println(droid);
}
}
} 这是带有main方法的标准类,该方法首先设置一个10 x 10的正方形Board并在坐标5,5处添加具有所提供属性的Droid 。 在第10行上,我们创建了MoveTo例程,该例程将目标设置为(7,9) 。 我们将此例程设置为机器人的唯一例程(第11行),并打印机器人的状态(第12行)。 然后我们执行5转并在每转之后显示机器人的状态。
运行Test我们将看到以下内容打印到sysout中:
Droid{name=MyDroid, x=5, y=5, health=10, range=2, damage=1}
>>> Starting routine: MoveTo
Droid{name=MyDroid, x=6, y=6, health=10, range=2, damage=1}
Droid{name=MyDroid, x=7, y=7, health=10, range=2, damage=1}
Droid{name=MyDroid, x=7, y=8, health=10, range=2, damage=1}
>>> Routine: MoveTo SUCCEEDED
Droid{name=MyDroid, x=7, y=9, health=10, range=2, damage=1}
Droid{name=MyDroid, x=7, y=9, health=10, range=2, damage=1} 如我们所见,机器人按预期从位置(5,5)开始。 首次调用update方法,启动MoveTo例程。 随后的3次对更新的调用将通过将机器人的坐标每转一圈将其移动到目的地。 例程成功后,传递给该例程的所有调用都将被忽略,因为它已完成。
这是第一步,但不是很有帮助。 假设我们要让我们的机器人在板上徘徊。 为此,我们将需要重复执行MoveTo例程,但是每次重新启动它时,都需要随机选择目的地。
徘徊
但是,让我们从Wander例程开始。 它只不过是一个MoveTo但是只要我们了解棋盘,我们就会生成一个随机目的地。
public class Wander extends Routine {
private static Random random = new Random();
private final Board board;
private MoveTo moveTo;
@Override
public void start() {
super.start();
this.moveTo.start();
}
public void reset() {
this.moveTo = new MoveTo(random.nextInt(board.getWidth()), random.nextInt(board.getHeight()));
}
public Wander(Board board) {
super();
this.board = board;
this.moveTo = new MoveTo(random.nextInt(board.getWidth()), random.nextInt(board.getHeight()));
}
@Override
public void act(Droid droid, Board board) {
if (!moveTo.isRunning()) {
return;
}
this.moveTo.act(droid, board);
if (this.moveTo.isSuccess()) {
succeed();
} else if (this.moveTo.isFailure()) {
fail();
}
}
} 遵循单一责任原则, Wander类的唯一目的是在板上选择随机的目的地。 然后,它使用MoveTo例程将机器人获取到新的目的地。 reset方法将重新启动它并选择一个新的随机目标。 目标是在构造函数中设置的。 如果我们希望机器人漫游,可以将Test类更改为以下内容:
public class Test {
public static void main(String[] args) {
// Setup
Board board = new Board(10, 10);
Droid droid = new Droid("MyDroid", 5, 5, 10, 1, 2);
board.addDroid(droid);
Routine routine = new Wander(board);
droid.setRoutine(routine);
System.out.println(droid);
for (int i = 0; i < 5; i++) {
droid.update();
System.out.println(droid);
}
}
}输出将类似于以下内容:
Droid{name=MyDroid, x=5, y=5, health=10, range=2, damage=1}
>>> Starting routine: Wander
>>> Starting routine: MoveTo
Droid{name=MyDroid, x=6, y=6, health=10, range=2, damage=1}
Droid{name=MyDroid, x=7, y=7, health=10, range=2, damage=1}
Droid{name=MyDroid, x=7, y=8, health=10, range=2, damage=1}
>>> Routine: MoveTo SUCCEEDED
>>> Routine: Wander SUCCEEDED
Droid{name=MyDroid, x=7, y=9, health=10, range=2, damage=1}
Droid{name=MyDroid, x=7, y=9, health=10, range=2, damage=1} 注意Wander如何包含和委托MoveTo例程。
重复,重复,重复...
一切都很好,但是如果我们希望机器人反复游荡怎么办? 我们将创建一个Repeat例程,其中将包含要重复的例程。 同样,我们将使该例程生效,以便它可以接受一个参数来指定我们要重复该例程多少次。 如果不接受参数,则它将永久重复包含例程,直到机器人死掉为止。
public class Repeat extends Routine {
private final Routine routine;
private int times;
private int originalTimes;
public Repeat(Routine routine) {
super();
this.routine = routine;
this.times = -1; // infinite
this.originalTimes = times;
}
public Repeat(Routine routine, int times) {
super();
if (times < 1) {
throw new RuntimeException("Can't repeat negative times.");
}
this.routine = routine;
this.times = times;
this.originalTimes = times;
}
@Override
public void start() {
super.start();
this.routine.start();
}
public void reset() {
// reset counters
this.times = originalTimes;
}
@Override
public void act(Droid droid, Board board) {
if (routine.isFailure()) {
fail();
} else if (routine.isSuccess()) {
if (times == 0) {
succeed();
return;
}
if (times > 0 || times <= -1) {
times--;
routine.reset();
routine.start();
}
}
if (routine.isRunning()) {
routine.act(droid, board);
}
}
} 该代码很容易理解,但是我将解释一些添加的内容。 属性routine在构造函数中传递,并且该例程将被重复。 originalTimes是一个存储变量,其中包含初始次数值,因此我们可以使用reset()调用重新启动例程。 这只是初始状态的备份。 times属性是提供的例程将被重复多少次。 如果它是-1那么它是无限的。 所有这些都编码在act方法内部的逻辑中。 为了测试这一点,我们需要创建一个Repeat例程并提供要重复的内容。 例如,要使机器人无限地徘徊,我们需要这样做:
Routine routine = new Repeat((new Wander(board)));
droid.setRoutine(routine); 如果我们反复调用update ,我们将看到机器人将不断移动。 检查以下样本输出:
Droid{name=MyDroid, x=5, y=5, health=10, range=2, damage=1}
>> Starting routine: Repeat
>>> Starting routine: Wander
>>> Starting routine: MoveTo
Droid{name=MyDroid, x=4, y=6, health=10, range=2, damage=1}
>>> Routine: MoveTo SUCCEEDED
>>> Routine: Wander SUCCEEDED
Droid{name=MyDroid, x=4, y=7, health=10, range=2, damage=1}
>>> Starting routine: Wander
>>> Starting routine: MoveTo
Droid{name=MyDroid, x=5, y=6, health=10, range=2, damage=1}
Droid{name=MyDroid, x=6, y=5, health=10, range=2, damage=1}
Droid{name=MyDroid, x=7, y=4, health=10, range=2, damage=1}
Droid{name=MyDroid, x=8, y=3, health=10, range=2, damage=1}
Droid{name=MyDroid, x=8, y=2, health=10, range=2, damage=1}
>>> Routine: MoveTo SUCCEEDED
>>> Routine: Wander SUCCEEDED
Droid{name=MyDroid, x=8, y=1, health=10, range=2, damage=1}
>>> Starting routine: Wander
>>> Starting routine: MoveTo
Droid{name=MyDroid, x=7, y=2, health=10, range=2, damage=1}
Droid{name=MyDroid, x=6, y=3, health=10, range=2, damage=1} 请注意Repeat例程不会结束。
组装情报
到目前为止,我们只是在编写行为。 但是,如果我们想对机器人进行决策并建立更复杂的行为,该怎么办? 输入行为树。 这个术语没有描述它的含义,我发现的大多数文章也没有描述。 我将从首先要实现的目标开始,希望这一切都是有意义的。 我想实现本文开头所述的行为。 我希望我的机器人扫描其范围内是否有较弱的机器人,如果有,请使其接合,否则请逃离。 看下图。 它显示了一棵树。 它不过是由多个不同例程组成的例程。 每个节点都是一个例程,我们将必须实现一些特殊的例程。
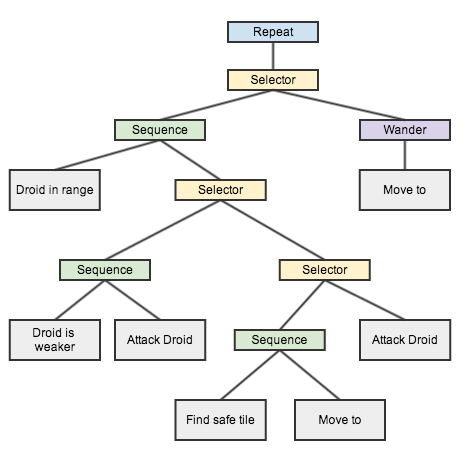

Droid AI(行为树)
让我们打破常规。
-
Repeat–是较早实施的例程。 它将永远重复给定的例程,或者直到嵌入式例程失败为止。 -
Sequence–顺序例程只有在其包含的所有例程都成功后才能成功。 例如,要攻击机器人,敌方机器人必须在射程范围内,需要装载枪支,机器人需要拉动扳机。 一切按此顺序进行。 因此,该序列包含例程列表并对其执行操作,直到所有例程都成功为止。 如果枪未装弹,则没有必要扳动扳机,因此整个攻击都是失败的。 -
Selector–此例程包含一个或多个例程的列表。 当它起作用时,如果列表中的例程之一成功,它将成功。 例程的执行顺序由例程的传递顺序设置。如果我们想随机化例程的执行,则创建一个Random例程很容易,其唯一目的是随机化例程列表通过了。 - 所有灰色例程都是树上的叶子,这意味着它们不能再包含任何后续例程,而这些例程将作用于作为接收者的droid上。
上面的树代表了我们想要实现的非常基本的AI。 让我们从根开始。Repeat –将无限期重复选择器,直到两个分支都无法成功执行。 选择器中的例程是: Attack a droid and Wander 。 如果两者均失败,则表明机器人已死。 Attack a droid例程是一系列例程,这意味着所有例程都必须成功才能使整个分支成功。 如果失败,则后退是通过Wander选择一个随机目的地并将其移动到那里。 然后重复。
我们需要做的就是实现例程。 例如, IsDroidInRange可能看起来像这样:
public class IsDroidInRange extends Routine {
public IsDroidInRange() {}
@Override
public void reset() {
start();
}
@Override
public void act(Droid droid, Board board) {
// find droid in range
for (Droid enemy : board.getDroids()) {
if (!droid.getName().equals(enemy)) {
if (isInRange(droid, enemy)) {
succeed();
break;
}
}
}
fail();
}
private boolean isInRange(Droid droid, Droid enemy) {
return (Math.abs(droid.getX() - enemy.getX()) <= droid.getRange()
|| Math.abs(droid.getY() - enemy.getY()) < droid.getRange());
}
} 这是一个非常基本的实现。 它确定机器人是否在范围内的方法是,通过遍历板上的所有机器人,以及敌方机器人(假设名称唯一)是否在范围内,则成功了。 否则失败。 当然,我们需要以某种方式将这个机器人输入下一个例程,即IsEnemyStronger 。 这可以通过为droid提供上下文来实现。 一种简单的方法可能是Droid类可以具有一个属性nearestEnemy , nearestEnemy success ,例程将填充该字段,而失败则将其清除。 这样,以下例程就可以访问droid的内部,并使用该信息确定其成功或失败的情况。 当然,可以并且应该对此进行扩展,以便机器人将在其范围内包含一系列机器人,并有例程确定机器人是否应该飞行或战斗。 但这不是本介绍的范围。
我不会实现本文中的所有例程,但是您将能够在github上查看代码:https ://github.com/obviam/behavior-trees ,我将添加越来越多的例程。
然后去哪儿?
仅仅看一下就可以做出很多改进。 作为测试系统的第一步,为了方便起见,我将例程的创建移至工厂。
/**
* Static convenience methods to create routines
*/
public class Routines {
public static Routine sequence(Routine... routines) {
Sequence sequence = new Sequence();
for (Routine routine : routines) {
sequence.addRoutine(routine);
}
return sequence;
}
public static Routine selector(Routine... routines) {
Selector selector = new Selector();
for (Routine routine : routines) {
selector.addRoutine(routine);
}
return selector;
}
public static Routine moveTo(int x, int y) {
return new MoveTo(x, y);
}
public static Routine repeatInfinite(Routine routine) {
return new Repeat(routine);
}
public static Routine repeat(Routine routine, int times) {
return new Repeat(routine, times);
}
public static Routine wander(Board board) {
return new Wander(board);
}
public static Routine IsDroidInRange() {
return new IsDroidInRange();
}
}这将允许以更优雅的方式测试某些方案。 例如,要放置2个具有不同行为的机器人,您可以执行以下操作:
public static void main(String[] args) {
Board board = new Board(25, 25);
Droid droid1 = new Droid("Droid_1", 2, 2, 10, 1, 3);
Droid droid2 = new Droid("Droid_2", 10, 10, 10, 2, 2);
Routine brain1 = Routines.sequence(
Routines.moveTo(5, 10),
Routines.moveTo(15, 12),
Routines.moveTo(2, 4)
);
droid1.setRoutine(brain1);
Routine brain2 = Routines.sequence(
Routines.repeat(Routines.wander(board), 4)
);
droid2.setRoutine(brain2);
for (int i = 0; i < 30; i++) {
System.out.println(droid1.toString());
System.out.println(droid2.toString());
droid1.update();
droid2.update();
}
}当然,到目前为止,这并不是最好的解决方案,但是它比例程的不断实例化要好。 理想情况下,应该使用脚本编写脚本并从外部源加载AI,例如通过脚本编写,或者至少以JSON形式提供,并由AI汇编程序创建。 这样,每次调整AI时都不需要重新编译游戏。 但是同样,这也不是本文的范围。
此外,我们如何决定哪个动作需要转牌/勾号或立即得到评估? 一种可能的解决方案是将动作点分配给机器人,机器人可以花一转(如果是实时的话,则要打勾),并为每个动作分配成本。 只要机器人机器人用尽了点,我们就可以继续前进。 我们还需要跟踪哪个例程是当前例程,以便我们优化树的遍历。 如果AI非常复杂(特别是在实时游戏中),这将很有帮助。
如果您认为本文很有用,并且想要获取代码,请检查github存储库。 您也可以返回,因为我打算对其进行扩展和更新,以便使其演变为更完整的AI示例。 因为这是我第一次接触AI,所以有很多事情需要改进,而且我总是对改进提出批评和想法。
翻译自: https://www.javacodegeeks.com/2014/08/game-ai-an-introduction-to-behaviour-trees.html
人工智能















 212
212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









