






点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
今天自动驾驶之心为大家分享卡内基梅隆大学和哈佛大学最新的工作!DeepSeek在自动驾驶中的应用!如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
论文作者 | Tianchen Gao等
编辑 | 自动驾驶之心
论文题目: A Comparison of DeepSeek and Other LLMs
论文链接:https://arxiv.org/pdf/2502.03688
写在前面 && 笔者理解
春节期间,最火爆的两个关键词,一个是“哪吒”,另一个便是一款大语言模型DeepSeek(DS)。它的最新版自从2025年1月20日发布以来,轰动了整个AI行业,迅速登上了各大新闻和社交媒体的头条,冲上了苹果商店的下载榜首,令投资者惊叹不已,甚至导致包括Nvidia在内多个科技股下跌。
其火爆的原因简单来说就是:它用较小的训练成本,在一些基准任务中,取得了与人工智能行业的大玩家(例如OpenAI的ChatGPT)相同甚至更好的结果。比如:作者展示了在从MATH数据集中衍生的30多个复杂的数学问题上,DeepSeek-R1在这些复杂问题上取得了比ChatGPT和Gemini等更高的准确性。
而在2025年的今天,市面上大语言模型层出不穷,各大公司都有自己的模型,并都大肆宣传自己模型的优势。这篇论文,作者就从两个有趣的任务来对比DeepSeek-R1与其他4种具有代表性的LLM的结果:OpenAI的GPT-4o-mini(GPT)、Google的Gemini-1.5-flash(Gemini)、Meta的Llama-3.1-8b(Llama)和Anthropic的Claude-3.5-sonnet(Claude)。
在介绍完作者工作的最后,笔者也会在文章的末尾和大家聊一聊DeepSeek的火爆对未来自动驾驶技术以及行业的发展会有什么影响。
任务介绍
这篇论文,作者从两个任务来评价LLM的表现:
作者身份分类(AC):判断文档是人类生成的(hum),还是人工智能生成的(AI),或者是人类生成但经过人工智能编辑的(humAI)。
引文分类(CC):给定一个(学术)引文及其周围的短文本,判断引文的类型。
作者身份分类
在过去的两年中,人工智能生成的文本内容开始迅速传播,影响了互联网、工作场所和日常生活。这引发了一个问题:如何区分人工智能创作的内容与人类创作的内容?这个问题是非常值得关注的,首先,人工智能生成的内容可能在医疗保健、新闻和金融等领域包含有害的错误信息,而这些虚假和误导性信息的传播可能会威胁在线资源的完整性。其次,了解人类生成内容与人工智能写作内容之间的主要差异,可以显著帮助改进人工智能语言模型。
作者通过考虑两种分类设置来解决这个问题,即AC1和AC2:
(AC1):在第一种设置中,作者专注于区分人类生成的文本和人工智能生成的文本(即hum与AI)。
(AC2):在第二种设置中,作者考虑更微妙的区分人类生成文本和经过人工智能编辑的人类生成文本(即hum与humAI)。
对于实验,作者提出了一种通用方法,使用LLM和MADStat(一个大规模的统计出版物数据集)为作者的研究生成新的数据集。作者首先选择几位作者,并收集这些作者在MADStat中发表的所有论文。对于每篇论文,MADStat包含标题和摘要。
(hum):作者将所有摘要作为人类生成的文本。
(AI):对于每篇论文,作者将标题输入GPT-4o-mini,并要求其生成一个摘要。作者将这些摘要作为人工智能生成的文本。
(humAI):对于每篇论文,作者还要求GPT-4o-mini编辑摘要。作者将这些摘要作为humAI文本。
引文分类
当一篇论文被引用时,该引用可能是重要的,也可能是不重要的。因此,为了评估一篇论文的影响,作者不仅对论文被引用的次数感兴趣,还对其重要引用的次数感兴趣。问题是,虽然比较容易统计一篇论文的原始引用次数(例如通过谷歌学术、Web of Science),但不清楚如何统计一篇论文的“重要”引用次数。为了解决这一问题,注意在引用实例周围通常有一段短文本。该文本包含有关引用的重要信息,作者可以利用它来预测引用的类型。这引发了引文分类问题,目标是利用引用周围的短文本预测引用类型。
首先,在回顾了许多文献和实证结果后,作者提议将所有学术引用分为以下四种不同类型,将这四种类型分别编码为“1”、“2”、“3”和“4”:
“基本思想(FI)”
“技术基础(TB)”
“背景(BG)”
“比较(CP)”
其次,经过大量努力,作者从头开始收集了一个新的数据集,作者称之为CitaStat。在这个数据集中,作者下载了1996年至2020年期间统计学领域4本代表性期刊的所有论文的PDF格式,并手动为引用打上标签。
现在作者可以使用这个数据集来比较上述5种LLM在引文分类中的表现。作者考虑两个实验:
(CC1):一个4分类实验,作者直接使用CitaStat,不作任何修改。
(CC2):一个2分类实验,作者将类别“1”和“2”(“FI”和“TB”)合并为一个新的“S”(重要)类别,将类别“3”和“4”(“BG”和“CP”)合并为一个新的“I”(偶然)类别。
结果与贡献
作者已将所有5种LLM应用于上述四个实验(AC1、AC2、CC1、CC2),并有以下观察结果:
在分类错误方面,Claude始终优于所有其他LLM方法。DeepSeek-R1的表现不如Claude,但在大多数情况下优于Gemini、GPT和Llama。GPT在AC1和AC2中的表现不尽如人意,错误率与随机猜测相似,但在CC1和CC2中的表现比随机猜测好得多。Llama的表现不尽如人意:其错误率要么与随机猜测相当,甚至更高。
在计算时间方面,Gemini和GPT比其他三种方法快得多,DeepSeek-R1是最慢的(DeepSeek的一个较旧版本,DeepSeek V3,速度更快,但表现不如DeepSeek-R1)。
在成本方面,与其他方法相比,Claude对客户来说要贵得多。例如,对于CC1和CC2,Claude的费用为12.30美元,Llama的费用为1.20美元,其他三种方法(DeepSeek、Gemini和GPT)的费用不超过0.30美元。
在输出相似性方面,DeepSeek与Gemini和Claude最相似(GPT和Llama在AC1和AC2中的表现高度相似,但两者的表现相对不尽如人意)。
表1列出了所有5种LLM方法在错误率方面的排名(错误率最低的方法排名为1)。平均排名表明,DeepSeek优于Gemini、GPT和Llama,但不如Claude(注意,对于CC1和CC2,作者使用了DeepSeek的两个版本,R1和V3;表1中的结果基于R1。如果作者使用V3,则DeepSeek与Gemini在平均排名上并列;它仍然优于GPT和Llama)。

总体而言,作者发现Claude和DeepSeek的错误率最低,但Claude相对较贵,DeepSeek相对较慢。
作者的这篇工作有如下贡献:首先,由于DeepSeek在人工智能行业内外都受到了广泛关注,因此有必要了解它与其他流行的LLM相比如何。通过两个有趣的分类问题,作者证明了DeepSeek在使用短文本预测结果的任务中具有竞争力。其次,作者提出了引文分类作为一个有趣的新问题,理解它将有助于评估学术研究的影响。最后但并非最不重要的,作者提供了CitaStat作为一个新的数据集,可用于评估学术研究。作者还提出了一种通用方法,用于生成新的数据集(以MadStatAI为例),用于研究人工智能生成的文本。这些数据集可以作为基准,用于比较不同算法,并学习人类生成文本与人工智能生成文本之间的差异。
具体实验结果
作者身份分类任务
MADStat包含超过83,000篇摘要,但处理所有这些数据需要花费大量时间。作者选择了一个较小的子集,具体如下:首先,作者将范围限制在MADStat中拥有超过30篇论文的作者。其次,作者从未被抽样的作者池中随机抽取15位作者,每次抽取一位新作者时,作者都会检查他/她是否与之前抽取的作者共同撰写过论文;如果是这样,作者会删除这位作者并抽取一位新的,直到作者总数达到15位。最后,作者收集了这15位作者在MADStat中的所有摘要。这构成了一个包含582篇摘要的数据集。
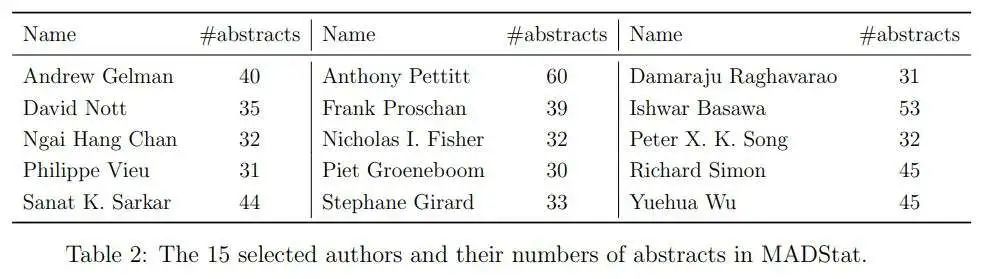
对于每篇原始人类撰写的摘要,作者使用GPT-4o-mini生成了两个变体。
AI版本:作者提供了论文标题,并要求生成一个新的摘要。提示语为:“为这篇具有以下标题的统计论文撰写摘要:[论文标题]。”
humAI版本:作者提供了原始摘要,并要求对其进行编辑。提示语为:“对以下摘要进行一些修订。确保不要过多改变长度。[原始摘要]。”
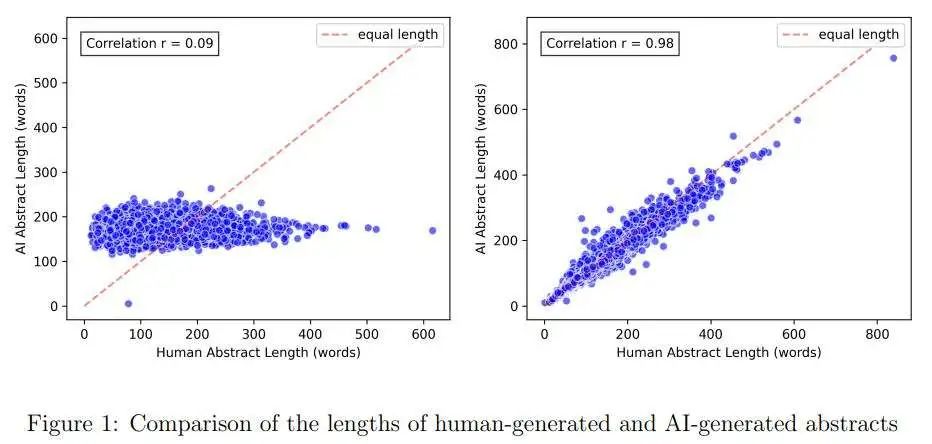
这两种变体均由AI创作,但它们看起来有所不同。AI版本通常与原始摘要有很大差异,因此“人类与AI”的分类问题相对容易。例如,图1的左侧面板比较了人类撰写摘要与AI版本摘要的长度。人类撰写摘要的长度变化很大,而AI生成的摘要长度大多在100到200字之间。humAI版本与原始摘要更为接近,通常只有一些局部的单词替换和轻微的句子重组。特别是,其长度与原始长度高度相关,这可以在图1的右侧面板中看到。
如前所述,作者考虑了两个分类问题:
(AC1):一个二分类问题,即“人类与AI”。
(AC2):一个二分类问题,即“人类与humAI”。
对于每个问题,有个测试样本,每个类别各占一半。作者将它们输入到每个LLM中,使用相同的提示:“你是一个分类器,用于判断文本是人类撰写的还是AI编辑的。请用一个词回答:如果是人类撰写的文本,回答‘人类’;如果是AI撰写的文本,回答‘ChatGPT’。尽可能做到准确。”
需要注意的是,与分类方法(例如,支持向量机、随机森林(Friedman等人,2001))相比,使用LLM进行分类的一个优势是,作者不需要提供任何训练样本。作者只需要用提示语输入LLM即可。
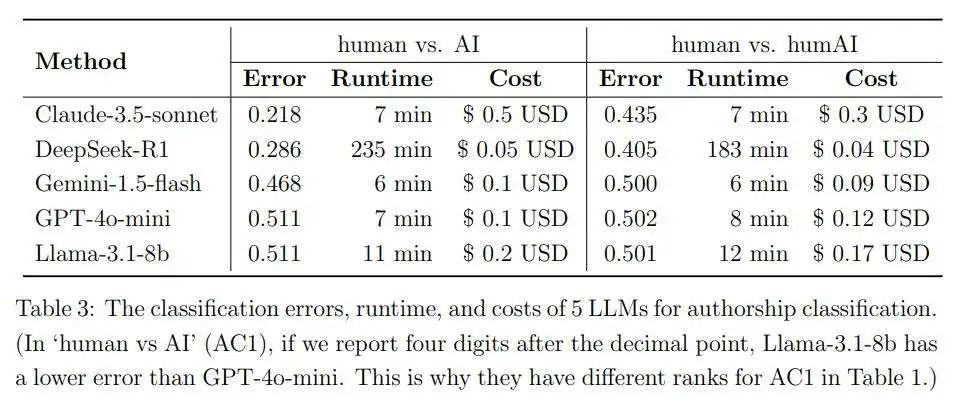
表3总结了5种LLM的表现。对于“人类与AI”(AC1),Claude-3.5-sonnet的错误率最低,为0.218,DeepSeek-R1位居第二,错误率为0.286。其他三种方法几乎总是预测“人类撰写”,这也解释了为什么它们的错误率接近0.5。对于“人类与humAI”(AC2),由于问题难度更大,可实现的最低错误率远高于“人类与AI”(AC1)。DeepSeek-R1的错误率最低,为0.405,Claude-3.5-sonnet位居第二,错误率为0.435。其他三种方法的错误率接近0.5。总之,Claude-3.5-sonnet和DeepSeek-R1在错误率方面表现最佳。如果还将运行时间考虑在内,Claude-3.5-sonnet的整体表现最佳。另一方面,Claude-3.5-sonnet的成本最高。
由于1164个测试摘要来自15位作者,作者还报告了每位作者的分类错误(即,测试文档仅包括该作者的人类撰写摘要和AI生成的变体)。图2显示了每位作者的错误率箱线图。
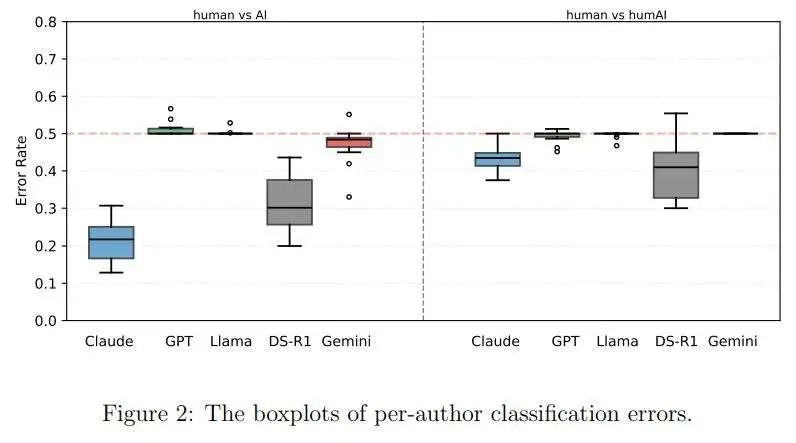
由于作者有不同的写作风格,这些图表比表3提供了更多的信息。对于“人类与AI”(AC1),Claude-3.5-sonnet仍然是明显的赢家。对于“人类与humAI”(AC2),DeepSeek-R1的表现仍然最佳。此外,其相对于Claude-3.5-sonnet的优势在这些箱线图中更为明显:尽管两种方法的整体错误率只有轻微差异,但DeepSeek-R1在某些作者上的表现确实更好。
作者还研究了不同LLM所做的预测之间的相似性。对于每对LLM,作者计算了在“人类与AI”(AC1)设置和“人类与humAI”(AC2)设置中对预测标签达成一致的百分比。结果如图3所示。
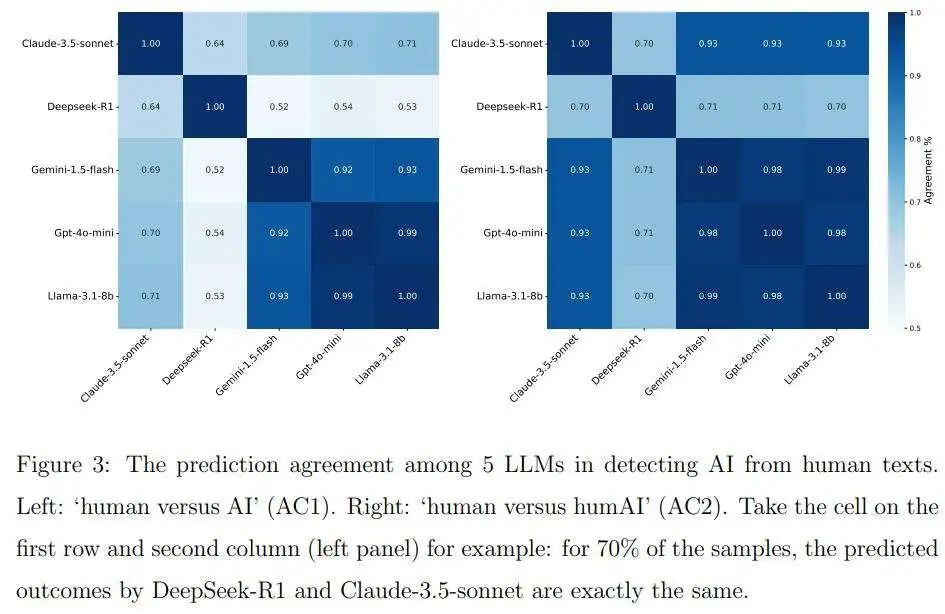
对于这两种设置,Gemini-1.5-flash、GPT-4o-mini和Llama-3.1-8b彼此之间的一致性极高。这是因为所有三种模型都对大多数样本预测为“人类撰写”。DeepSeek-R1和Claude与其他三种模型不同,它们在两种设置中的相互一致性分别为64%和70%。
引文分类任务
MADStat仅包含元信息和摘要,而不是完整的论文。作者通过下载完整论文并提取引用周围的文本创建了一个新的数据集,即CitaStat。作者随机选择了个,并手动将它们标记为以下四个类别之一:
“背景(BG)”(背景、动机、相关研究以及用于支持/说明观点的示例)。示例:“近年来,许多文章讨论了按地理区域(州)和肿瘤划分的当前和未来癌症死亡率的估计,其中包括Tiwari等人(2004年)……”
“比较(CP)”(对方法或理论结果的比较)。示例:“确定神经元对数量的另一种方法是遵循Medeiros和Veiga(2000b)以及Medeiros等人(2002年)的方法,使用一个序列……”
“基本思想(FI)”(直接启发或为当前论文提供重要思想的先前工作)。示例:“所提出的离散变换生存模型最初是受到Dabrowska和Doskum(1988a)提出的连续广义比率模型以及Zeng和Lin(2006年)的启发……”
“技术基础(TB)”(重要的工具、方法、数据集和其他资源)。示例:“作者通过欧拉方法(Protter和Talay 1997;Jacod 2004)数值求解该系统,时间步长为一天……”
有时两个类别可能会重叠。例如,引用了一篇参考文献作为提供基本思想的文献,同时在同一句子中也进行了比较。在这种情况下,作者将其标记为“基本思想(FI)”,以突出其比一般比较更为重要。有20个引用实例的手动标记结果为“不确定”。作者将其移除,最终获得了个标记样本(见表4)。
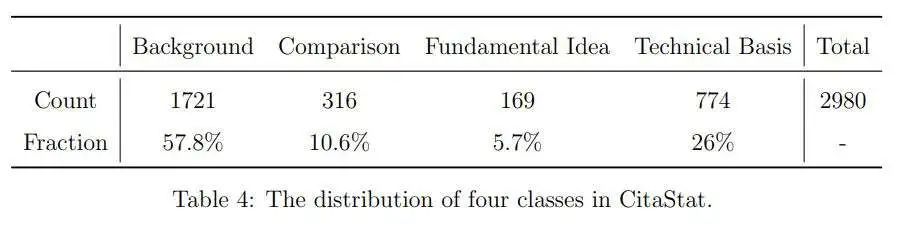
有了这个CitaStat数据集,作者考虑了两个问题,如前所述:
(CC1):4分类问题:给定引用的文本内容(即引用周围的文本),作者的目标是将其分类为四个类别之一。
(CC2):2分类问题:作者将四个类别重新组合为两个,其中“基本思想”和“技术基础”被视为“重要(S)”,而背景和比较被视为“偶然(I)”。给定引用的文本内容,作者的目标是预测它是否是一个“重要(S)”引用。
对于每种LLM,作者使用提示语来获取分类决策。与前面的作者身份分类问题不同,这个问题中的类别定义不是常识,需要包含在提示语中。在2分类问题中,作者使用图4中的提示语。

它提供了定义、示例以及如何将四个类别重新组合为两个的描述,旨在向LLM传达尽可能多的信息。4分类问题的提示语类似,只是移除了将4个类别组合为2个的描述,并修改了输出格式的要求(见图4)。
作者检查了所有5种LLM的表现。由于DeepSeek-R1的运行时间远长于其他方法,作者仅在149个随机选择的样本上对其进行了实施(这些样本包括所有样本的5%,并保持与完整数据集相同的类别比例),以评估其分类错误率。与此同时,作者在所有样本上运行了DeepSeek-V3,即DeepSeek-R1的一个较早版本。结果如表5所示。
对于4分类问题,Claude-3.5-sonnet的错误率最低,为0.327,紧随其后的是Gemini-1.5-flash,错误率为0.347。DeepSeek-R1的表现优于DeepSeek-V3,但不如其他方法,除了Llama-3.1-8b。对于2分类问题,Claude-3.5-sonnet仍然取得了最佳表现,错误率为0.261。DeepSeek-R1位居第二,错误率为0.275。Gemini-1.5-flash的表现不如DeepSeek-R1,但略优于DeepSeek-V3。总之,Claude-3.5-sonnet在错误率方面获胜。
就运行时间而言,GPT-4o-mini和Gemini-1.5-flash是最快的(尤其是GPT-4o-mini仅花费了15分钟)。DeepSeek-V3和Llama-3.1-8b相对较慢,需要数小时。就成本而言,DeepSeek-V3是最便宜的,而Claude 3.5-sonnet的成本显著高于其他方法。
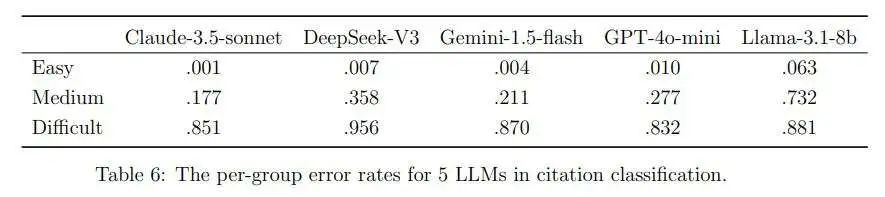
此外,在4分类设置中,作者根据5种LLM的平均预测错误率(这是5个二元值的平均值;作者排除了DeepSeek-R1,因为作者没有所有样本的结果)将所有样本分为三个组。最低的30%、中间的40%和最高的30%分别被称为简单案例、中等案例和困难案例。表6显示了所有5种LLM在每个组中的错误率。在简单案例中,除了Llama-3.1-8b之外,所有方法的错误率都不到0.01。在困难案例中,所有方法的表现都很差,GPT-4o-mini的错误率最低,为0.832,而DeepSeek V3的错误率最高,为0.956。在中等案例中,Claude-3.5-sonnet的表现良好,错误率为0.177,紧随其后的是Gemini-1.5-flash,其错误率相似,为0.211。Llama-3.1-8b的错误率显著更高,为0.732。
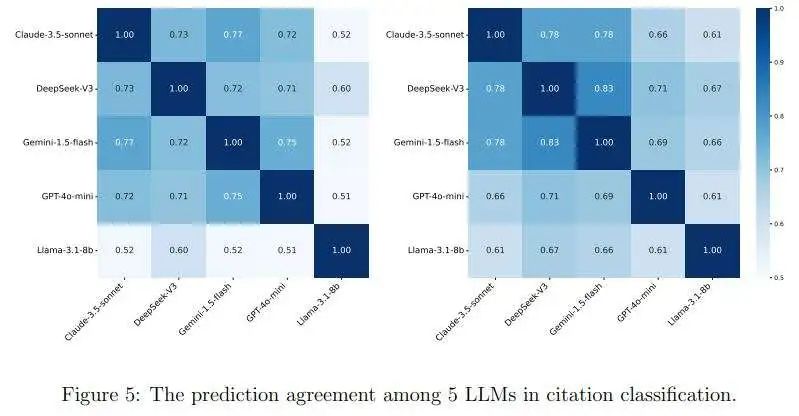
最后,作者研究了不同LLM所做的预测之间的相似性。对于DeepSeek-R1,由于作者仅在5%的样本上对其进行了实施,因此作者将其排除在比较之外。对于剩下的5种LLM的每对,作者计算了在4分类和2分类设置中对预测标签达成一致的百分比。结果如图5所示。
综上所述,DeepSeek在大多数情况下表现优于Gemini、GPT和Llama,但在准确性方面始终不如Claude。此外,DeepSeek的计算速度比其他模型慢,而Claude的成本远高于其他模型。鉴于DeepSeek是一种相对较新的LLM,其训练成本仅为其他LLM的一小部分,作者预计在不久的将来,DeepSeek将显著发展,并可能成为作者研究中最吸引人的LLM方法。
论文讨论
自2025年1月20日其最新版本发布以来,DeepSeek一直备受人工智能行业内外的关注。研究不同LLM之间的性能差异具有重要意义。在本文中,作者通过两项任务——作者身份分类和引文分类——对DeepSeek与其他4种流行的LLM(Claude、Gemini、GPT、Llama)进行了比较。在这些任务中,作者发现就预测准确性而言,DeepSeek在大多数情况下优于Gemini、GPT和Llama,但始终不如Claude。
作者的工作可以在几个方向上进行拓展。首先,将这些LLM与其他更多任务(例如自然语言处理、计算机视觉等)进行比较将十分有意义。例如,作者可以使用ImageNet数据集(Deng等人,2009)来比较这些LLM,看看哪种AI在分类任务中更为准确。
DeepSeek对自动驾驶的影响
自从ChatGPT火了之后,AI大模型上车的趋势已经成为车圈的热门话题。如今DeepSeek的热度也如燎原之火,快速蔓延到了汽车领域。截止2月8日,已经有包括吉利、岚图、智己等多家车企相继宣布进入或深度融合DeepSeek大模型,目标就是使其家的车机系统变得更加智能,给每个用户奉上拥有钢铁侠的“贾维斯”的体验。
那么除了给智能座舱系统加上buff之外,DeepSeek在自动驾驶领域上可以带来哪些影响呢?
笔者认为最大影响就是,为自动驾驶系统降低成本起到了积极作用,这也为一些二三线的厂商提供了一些破局的思路。
一方面,它可以帮助减小云端成本。其Transformer框架为基础,融合了多头潜在注意力(MLA)、DeepSeek混合专家模型(DeepSeekMoE)、无辅助损失的负载均衡策略以及多令牌预测(MTP)等核心创新技术,带来了高性能低成本的双重优势。在训练环节,DeepSeek采用自主研发的DualPipe算法,并结合基于FP8数据格式的混合精度训练框架,有效降低了训练过程中的内存需求,显著提升了训练效率。
另一方面,也可以帮助减小端侧成本。在推理能力方面,DeepSeek-R1在DeepSeek-V3基础模型之上,借助大规模强化学习技术强化了推理能力,并成功地将强化学习所赋予的强大推理能力推广至其他领域。此外,通过运用模型蒸馏技术,DeepSeek显著提升了小模型的推理性能。这使得在算力较低的芯片上也可以跑出效果不错的模型。
DeepSeek也可以代替其它的大模型,开发一些自动化标注工具(如半监督学习和主动学习),对图像的数据进行自动标注。通过数据清洗算法(如异常值检测、去噪算法),去除低质量数据。
此外,可以利用DeepSeek的对开放世界理解能力,比如识别训练数据中未覆盖的罕见物体(如特殊工程车辆、动物),从而弥补传统感知模型的长尾问题。还可以帮助描述当前行驶的路况,与驾驶员做交互,对自动驾驶决策做出可解释性的回答,尤其是对于现在主流的端到端的模型架构,是驾驶员也可以“知其然,知其所以然”。
站在2025年初,大模型已经火了两年有余,我们不知道未来会发生怎样的技术革命,但是作为自驾从业人员,我们仍需要保持对前沿技术的热情,永远让“新技术的风刮进自动驾驶圈”
① 自动驾驶论文辅导来啦

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 3730
3730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









