










本文是关于深度人脸识别,British Machine Vision Conference, 2015
Visual Geometry Group Department of Engineering Science
University of Oxford
VGG网络提出的那帮家伙
开源代码 http://www.robots.ox.ac.uk/~vgg/software/vgg_face/
本文主要说了两件事:
1)从零开始构建一个人脸识别数据库,一共 2.6M images, over 2.6K people,构建过 程主要是程序实现的,少量人工参与。
2)通过对比各种CNN网络,提出了一个简单有效的CNN网络,在各种公开的人脸识别数据库上得到很好的效果。
首先来看看各种数据库的比较:
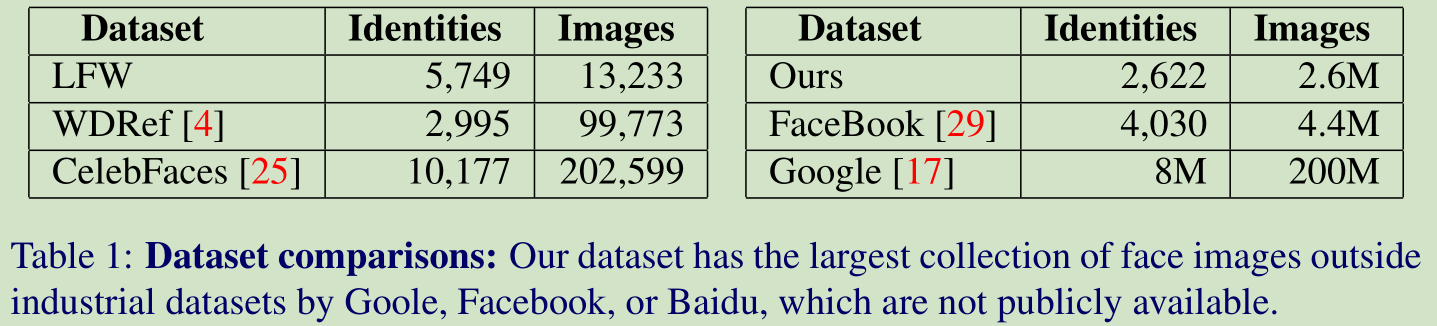
Google 的数据库数据量最大,但是人家不是公开的。
下图是我们数据库里的六个人的人脸照片

2 Related Work
人脸识别一开始大家都是基于 shallow 方法来解决, SIFT, LBP, HOG等。最近随着CNN网络的优异表现,很多学者用CNN来做人脸识别, DeepFace,一系列DeepID, Facenet。
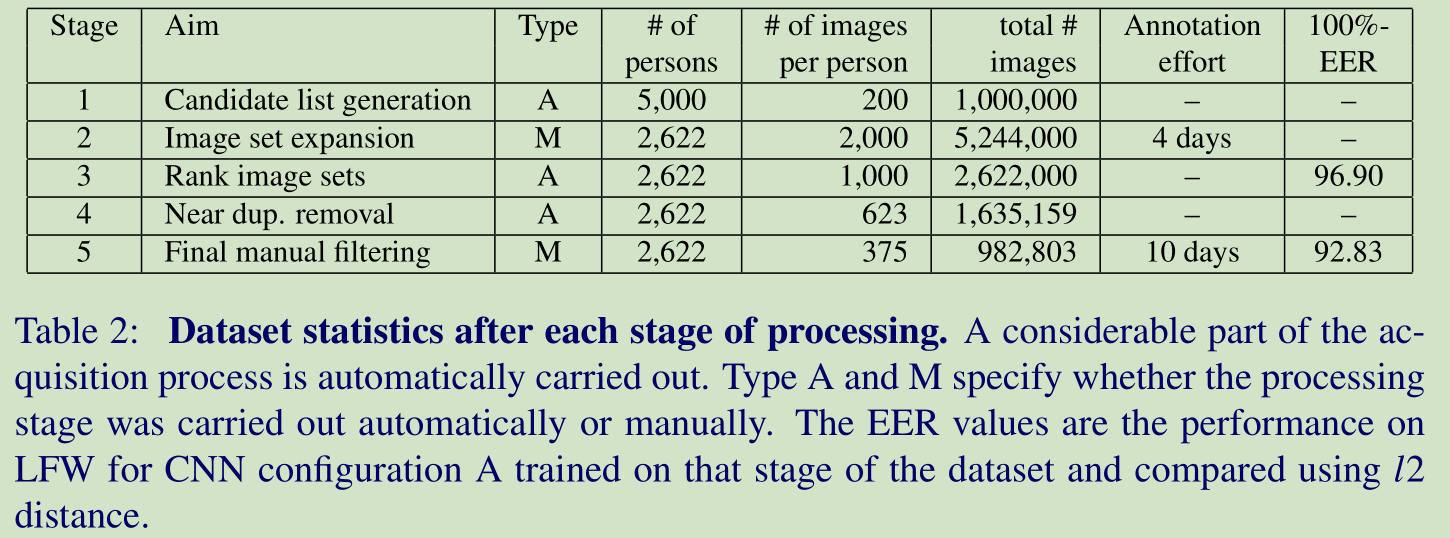
3 Dataset Collection
下面来说说我们的数据库是怎么构建的。
Stage 1. Bootstrapping and filtering a list of candidate identity names
Stage 2. Collecting more images for each identity
Stage 3. Improving purity with an automatic filter
Stage 4. Near duplicate removal
Stage 5. Final manual filtering
4 Network architecture and training
受文献【19】的启发,我们使用了 很深的网络
这里我们将人脸识别看做分类问题,有多少个人脸就有多少个类。参考文献【17】,我们使用 triplet loss 来训练得到一个 face embedding,这可以提高效果。最小化triplet loss 如下:
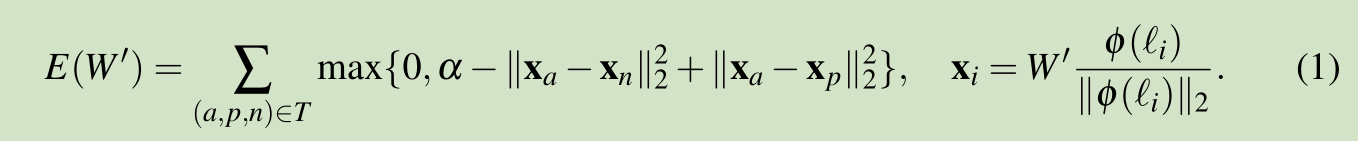
4.3 Architecture
这里我们考虑了三个网络结构,A,B,D。 网络A 的结构如下:
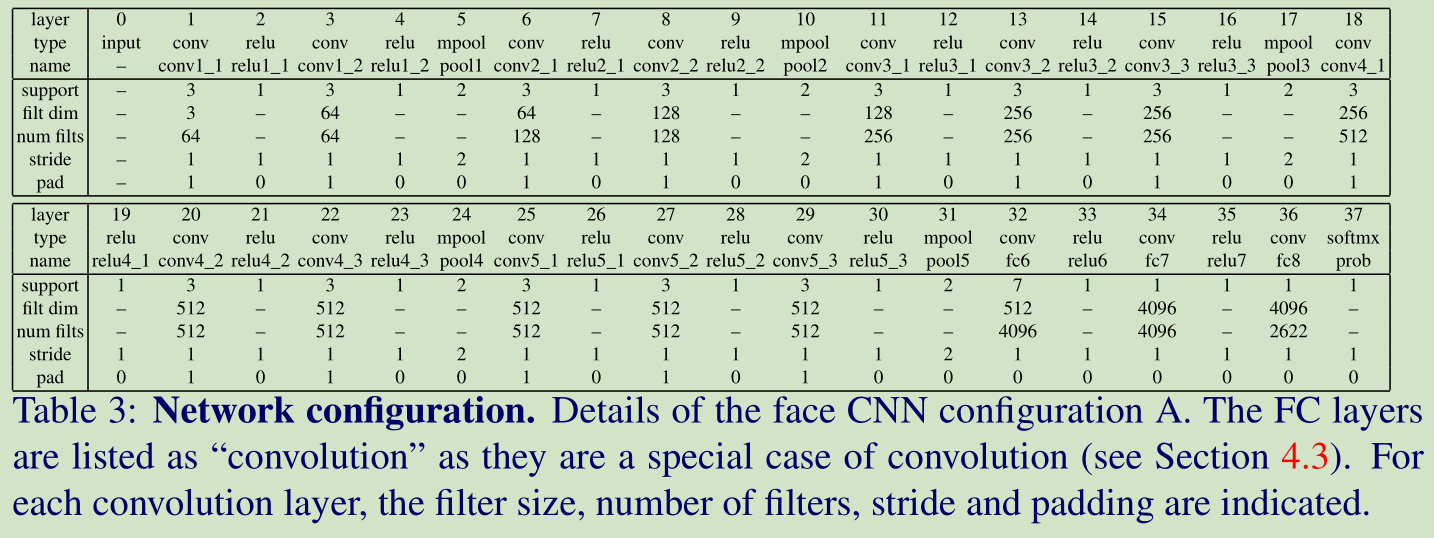
这里我们将全链接层看做卷积层。网络B,D比网络A分别多了2个和5个卷积层。输入的人脸图像大小是 224*224。
4.4 Training
这里主要说了一下训练时的一些参数设置。
5 Datasets and evaluation protocols
在两个数据库上进行了测试 :
Labeled Faces in the Wild dataset (LFW), YouTube Faces (YTF)
6 Experiments and results
硬件配置: NVIDIA Titan Black GPUs with 6GB of onboard memory, using
four GPUs together
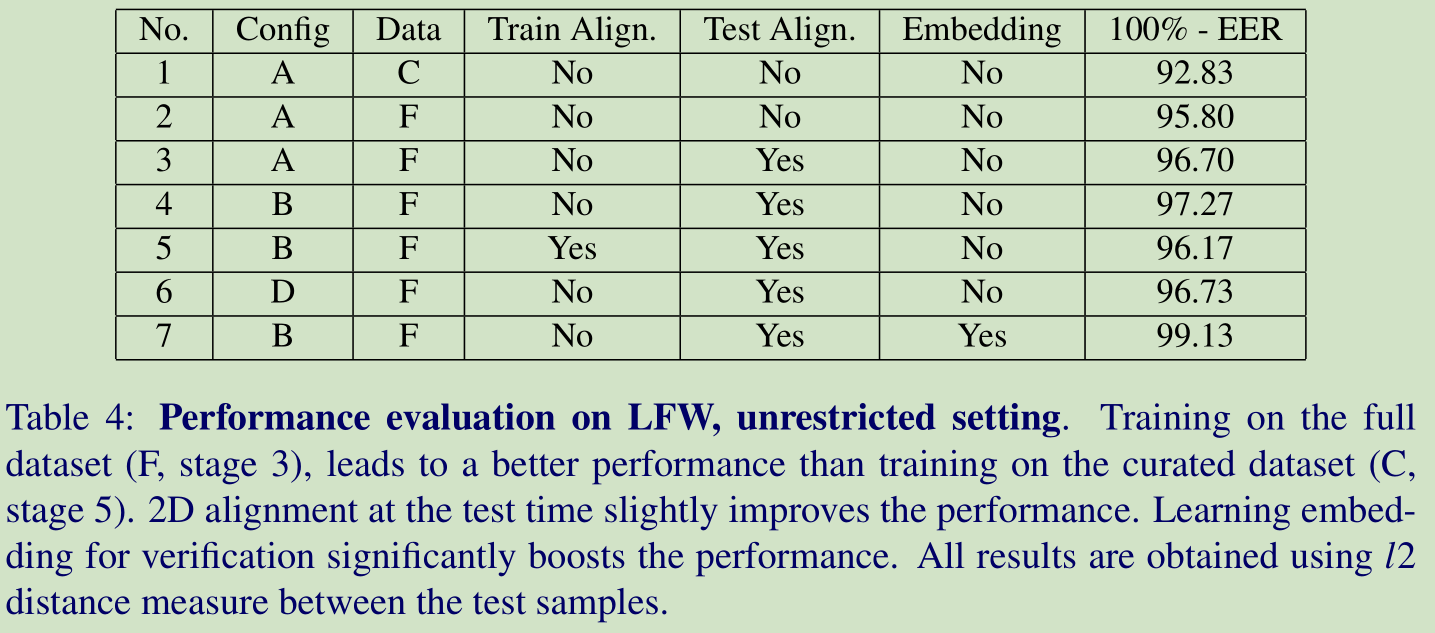
不同网络结构效果如下:
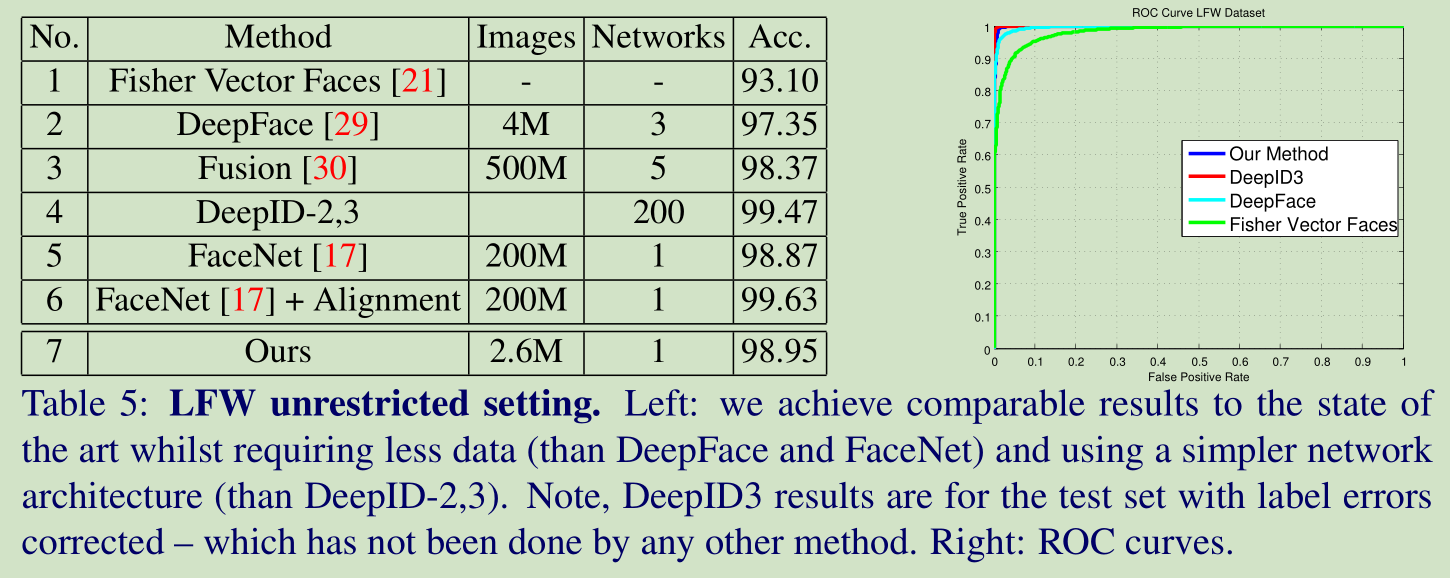
在LFW上和其他算法的结果对比:
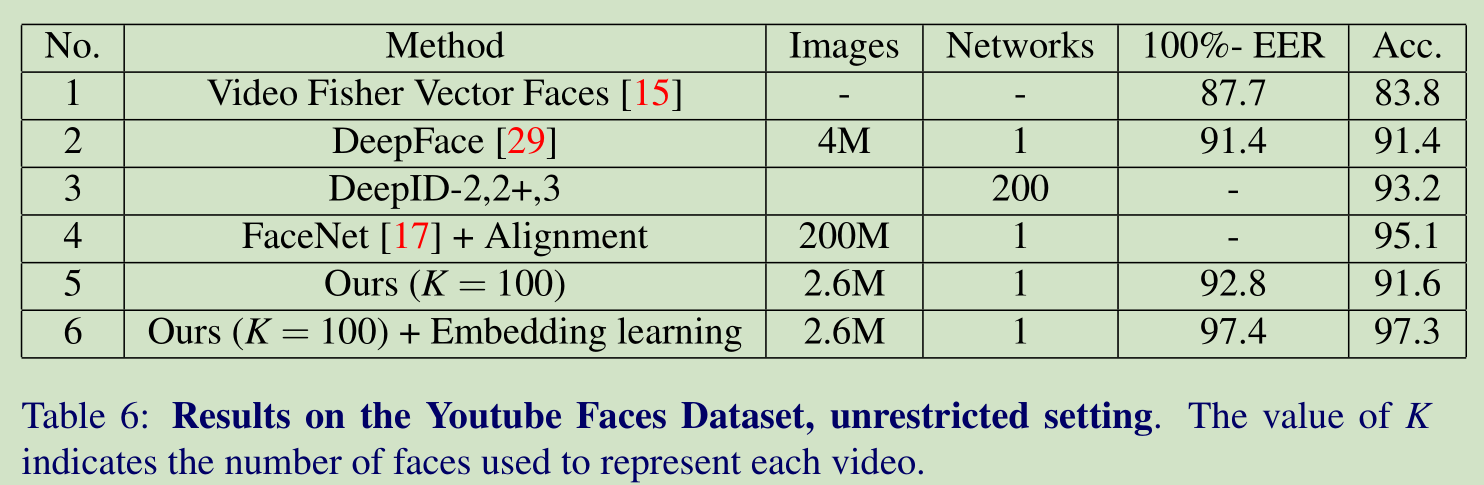
在 Youtube 上和其他算法的结果对比:
6.1 Component analysis
Dataset curation: 在网络A上,数据净化后的效果要差一下,可能原因有两个:1)更多的有噪声的数据会好些,2)可能是净化后把一下较难的训练数据去除了。
Alignment: 对测试图像进行 2D对齐是有帮助的,但是对训练图像进行2D对齐没有帮助
Architecture: 网络B的效果最好。可能的原因比较多。
Triplet-loss embedding: 这个对结果的改善还是挺大的。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









