









CVPR2016
Latent Embeddings for Zero-shot Classification
本文还是针对 zero-shot classification 问题。以前基于 structured embedding frameworks 解决这个问题的思路主要如下:首先将 图像和 类别信息映射到某些多维向量空间。 一般图像的嵌入信息( Image embeddings )通过 CNN提取特征,类别嵌入信息 Class embeddings 可以通过两个方法获取:1)人工标记属性得到,2)直接从大量未标记文本资料中自动提取。然后我们学习一个discriminative bilinear compatibility 函数,使得同一类图像相近,不同类图像相远。一旦这个函数学习固定,我们可以通过该函数实现 zero-shot classification 。
本文主要 改进的就是 这个 discriminative bilinear compatibility,将其改为线性函数模型集合。针对不同类、特征图像,我们自动选择(通过 the selection being latent 实现)最好的线性函数模型来进行分类。
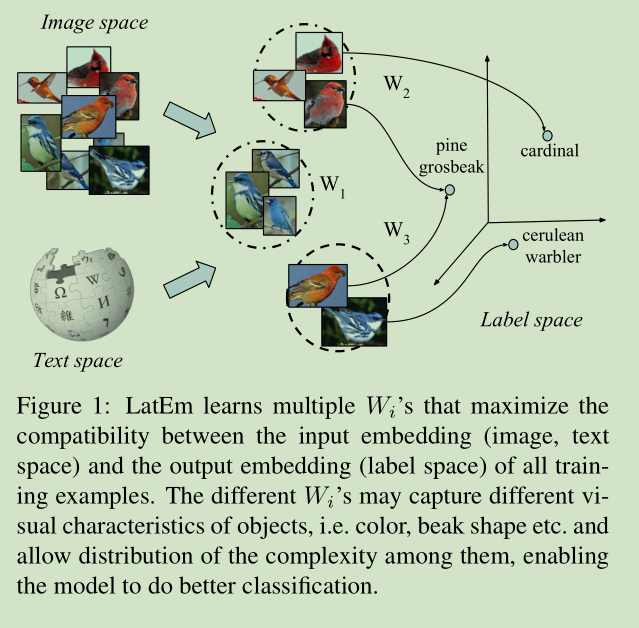
实验结果:
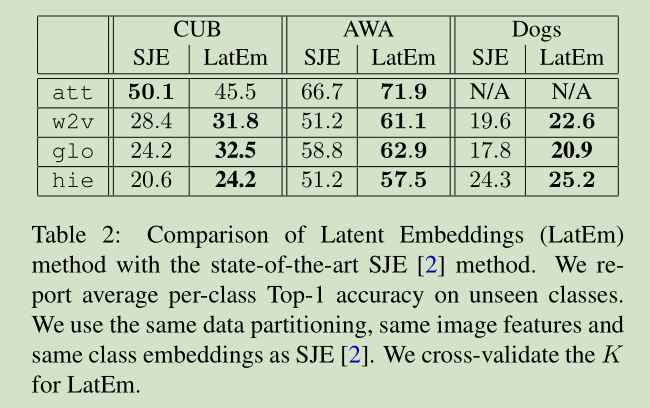
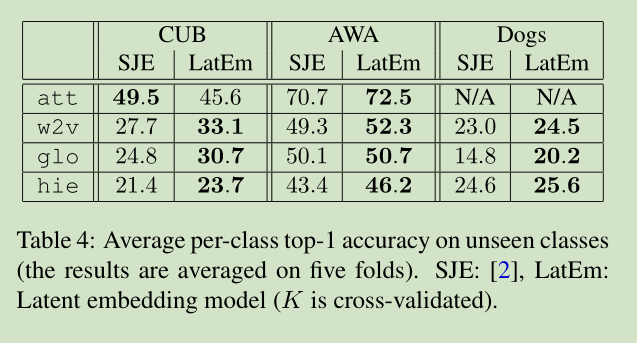















 54
54

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









