







文章使用了全卷积的网络,接受任意大小的输入,生成对应大小的输出。将
AlexNet,VggNet,GoogleNet转换为全卷积网络,并定义了结合深层和浅层信息的结构用于分割。
全卷积网络结构
卷积的输入和输出关系为:
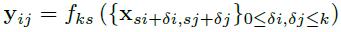
对于AlexNet来说,全连接层维度固定,不包含空间信息,但全连接可以看作是与覆盖全区域的核的卷积,这样就会生成特征图,如下图所示。
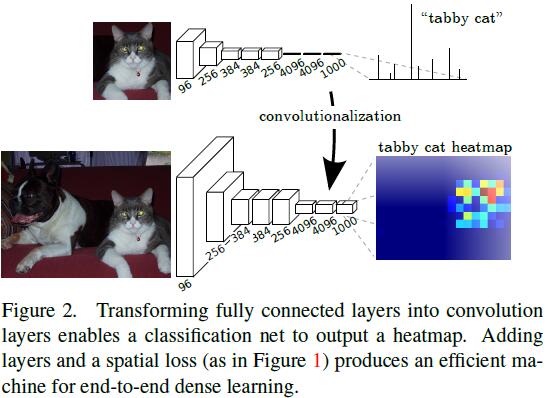
网络输出尺寸是10*10的特征图,特征图的生成过程等效于在小图像块上使用网络计算,图像块之间有交叠,所有计算时间并不高。
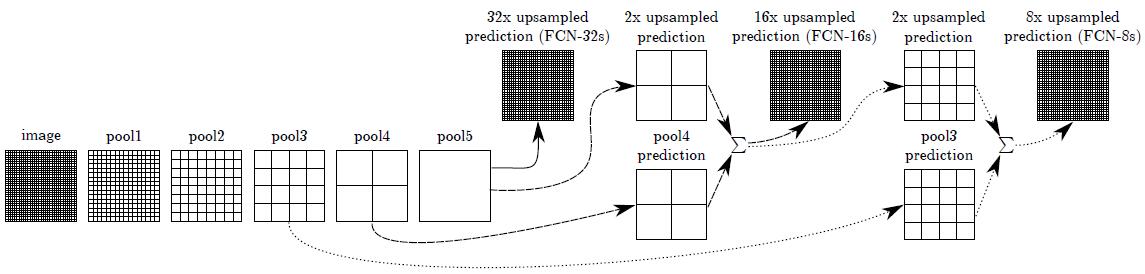
分割所采用的网络结构,采用skip layer的方法,在浅层处减小upsampling的步长,得到的fine layer 和 高层得到的coarse layer做融合,然后再upsampling得到输出。这种做法兼顾local和global信息,如下图所示:
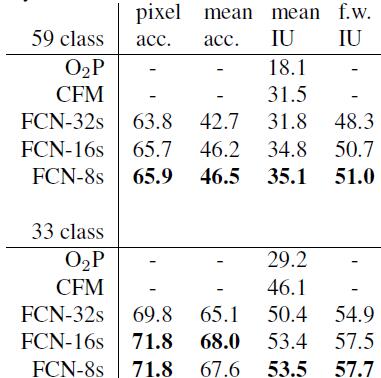
实验结果
在Pascal Context上的实验结果如下表所示:















 495
495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









